
專案例項---隨機森林在Kaggle例項:Titanic中的應用(二)
4、 特徵工程
特徵工程主要是對一些不適合直接參與建模的特徵進行各種處理,通過已有資料構建一些新特徵,對特徵進行啞變數轉換等等。
4.1 對Name進行處理
由於名字一般都比較雜亂,似乎對模型預測沒有任何作用。但是通過對Name進行觀察發現,在姓名裡包含了一些身份資訊,性別資訊,我們可以粗略看一下。
#對Name進行處理
#檢視Name
print(dataset["Name"].head())結果如下:
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 從上面可以看到名字中間部分有Mr、Mrs這些能代表性別也能一定程度上反映身份的資訊,更具體的可以檢視整個資料集,這裡直接提取出中間部分,並進行統計。
#下面直接提取名字中間部分
dataset_title=[i.split("," 結果如下
count 1299
unique 18
top Mr
freq 753
Name: Title, dtype: object
['Mr' 'Mrs' 'Miss' 'Master' 'Don' 'Rev' 以下是從百度查詢到的相關解釋:
Mr.= mister,先生
Mrs.= mistress,太太/夫人
Miss,複數為misses,對未婚婦女用,
Ms.或Mz,美國近來用來稱呼婚姻狀態不明的婦女
Madame簡寫是Mme.,複數是mesdames(簡寫是Mme)
Mlle,小姐
Lady, 女士,指成年女子,有些人尤其是長者認為這樣說比較禮貌
Dona,是西班牙語對女子的稱謂,相當於英語的 Lady
Master,傭人對未成年男少主人的稱呼,相當於漢語的"少爺"。
Mr. Mister的略字,相當於漢語中的"先生",是對男性一般的稱呼,區別於有頭銜的人們,如Doctor, Professor,Colonel等
Don,n. <西>(置於男士名字前的尊稱)先生,堂
jonkheer是貴族
St.= saint,聖人
Rev.= reverend,用於基督教的牧師,如the Rev. Mr.Smith
Dr.= doctor,醫生/博士
Colonel,上校
major,意思有少校人意思
The Countless,女伯爵所以我們可以將上面定義的Title進行分類:
第一類:’Mr’ 、’Don’
第二類:’Mrs’ 、’Miss’ 、’Mme’ 、’Ms’ 、’Lady’、 ‘Dona’ 、’Mlle’
第三類: ‘Sir’ 、’Major’、 ‘Col’ 、’Capt’
第四類:’Master’ 、’Jonkheer’、 ‘the Countess’
第五類:’Rev’ 、’Dr’
#將title合併為幾個組
dataset["Title"]=dataset["Title"].replace(['Mr','Don'],'Mr')
dataset["Title"]=dataset["Title"].replace(['Mrs','Miss','Mme','Ms','Lady','Dona','Mlle'],'Ms')
dataset["Title"]=dataset["Title"].replace(['Sir','Major','Col','Capt'],'Major')
dataset["Title"]=dataset["Title"].replace(['Master','Jonkheer','the Countess'],'Jonkheer')
dataset["Title"]=dataset["Title"].replace(['Rev','Dr'],'Rev')檢視各組的倖存率
#我們檢視各組的倖存率情況:
g=sns.barplot(data=dataset[:train_len],x="Title",y="Survived")
g.set_ylabel("Survival Probability")
plt.show()結果如下:
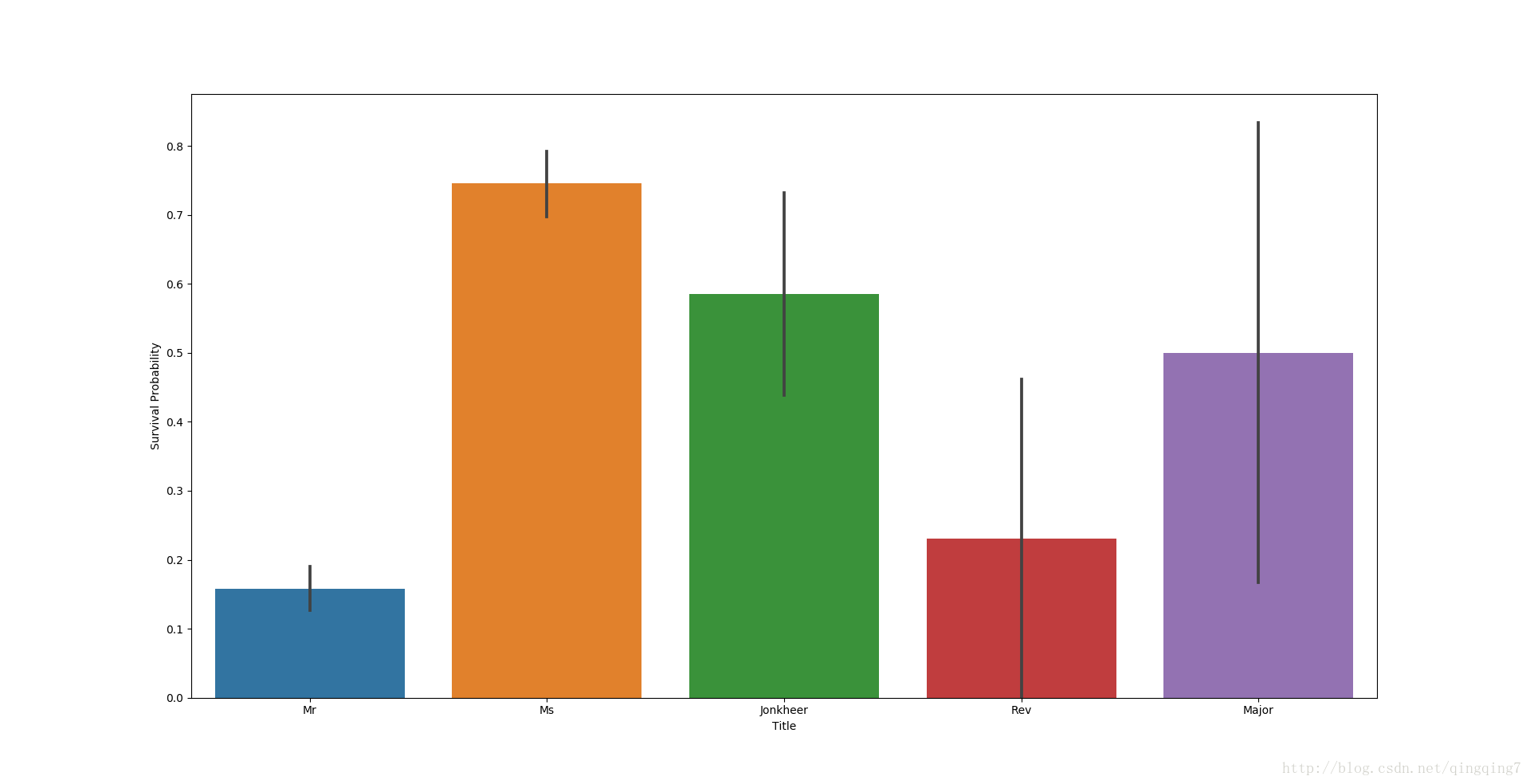
從圖上可以看到男女的差別與之前的分析是一致的,同時貴族和軍人相對其他男性也有較高的倖存率,但是神職人員和醫生的生存率並沒有高出很多,醫生的倖存率有點不合邏輯因而重新分組。
結果如下:
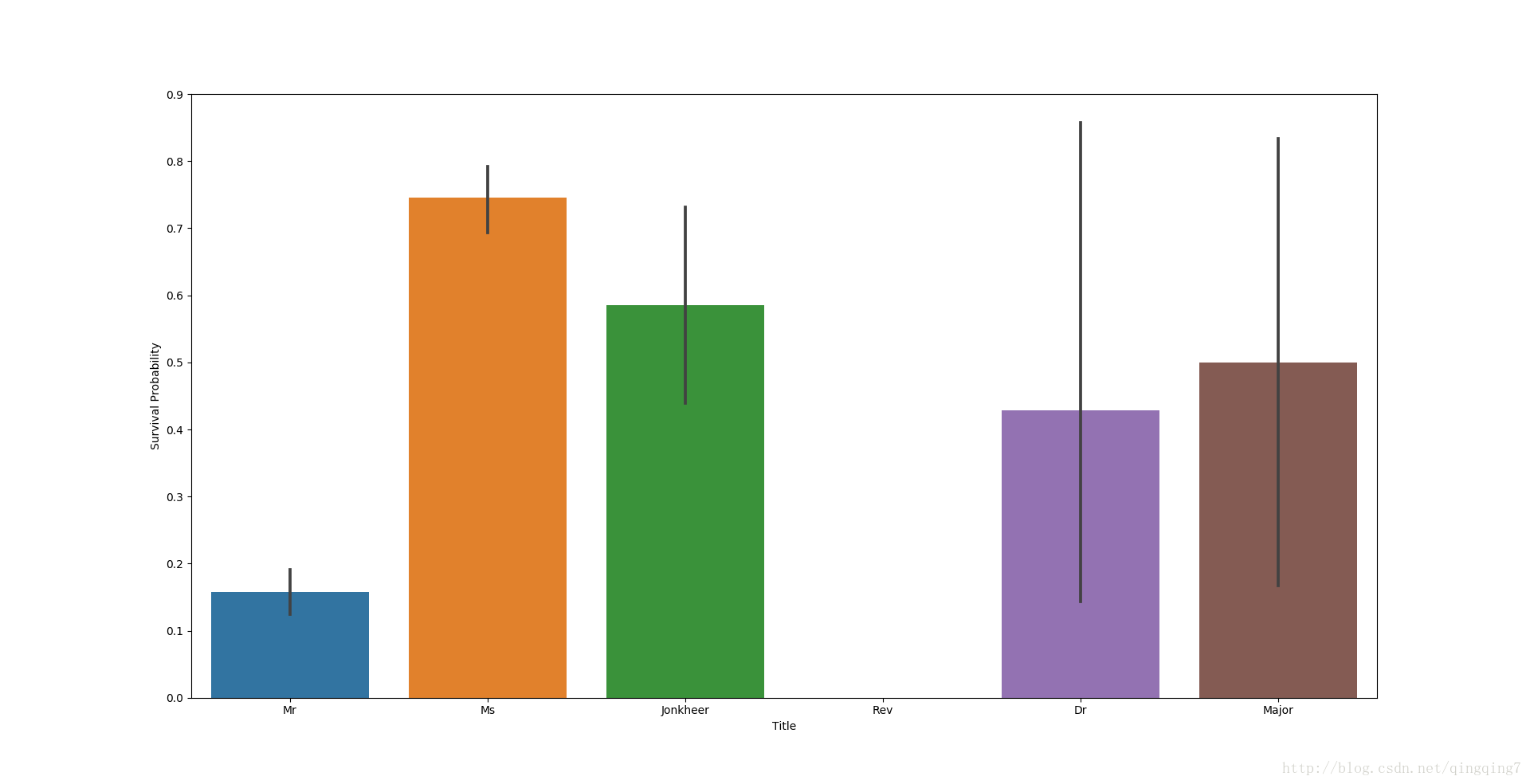
從圖上看到神職人員沒有幸存的,而醫生的倖存率較普通男性仍然高出很多。
#下面將姓名數值化
dataset["Title"]=dataset["Title"].map({'Mr':0,'Ms':1,'Major':2,'Jonkheer':3,'Rev':4,'Dr':5})
dataset["Title"]=dataset["Title"].astype(int)
#將Title啞變數化
dataset=pd.get_dummies(dataset,columns=["Title"],prefix="TL")
# 去掉name這一特徵
dataset.drop(labels = ["Name"], axis = 1, inplace = True)
print(dataset.info())4.2 對Cabin進行處理
#對Cabin進行處理
#先檢視Cabin的情況
print(dataset["Cabin"].describe())結果如下:
count 292
unique 186
top G6
freq 5
Name: Cabin, dtype: object從上可以看到Cabin中有186個不同的取值,直接統計不太可能也沒必要。
下面再檢視缺失值的情況
print(dataset["Cabin"].isnull().sum())結果如右:1007
缺失值和存在真實值的樣本比例是1007:292,通常這種情況可以直接將該特徵去掉(而且船艙與票價是有相關性的);這裡我們並沒有去掉,主要考慮到船艙本身可能能反映乘客的身份和逃生的硬體實施和便利性,而普通人群中沒有特殊身份的人更可能缺少船艙資訊,用字母X來表示缺失,不失為一種恰當的處理方法。首字母相同的船艙情況相近,船艙資訊直接用首字母來代替也是合理的。
#將船艙資訊進行替換
dataset["Cabin"]=pd.Series([i[0] if not pd.isnull(i) else 'X' for i in dataset['Cabin']])
#再來檢視一下船艙資訊
print(dataset["Cabin"].describe())
print(dataset["Cabin"].isnull().sum())可以看到如下結果:
count 1299
unique 9
top X
freq 1007
Name: Cabin, dtype: object
0現在只有Cabin只有9個值,而缺失值為0。
#檢視不同船艙的倖存率
g=sns.barplot(data=dataset[:train_len],x="Cabin",y="Survived")
g.set_ylabel("Survival Probability")
plt.show()結果如下:
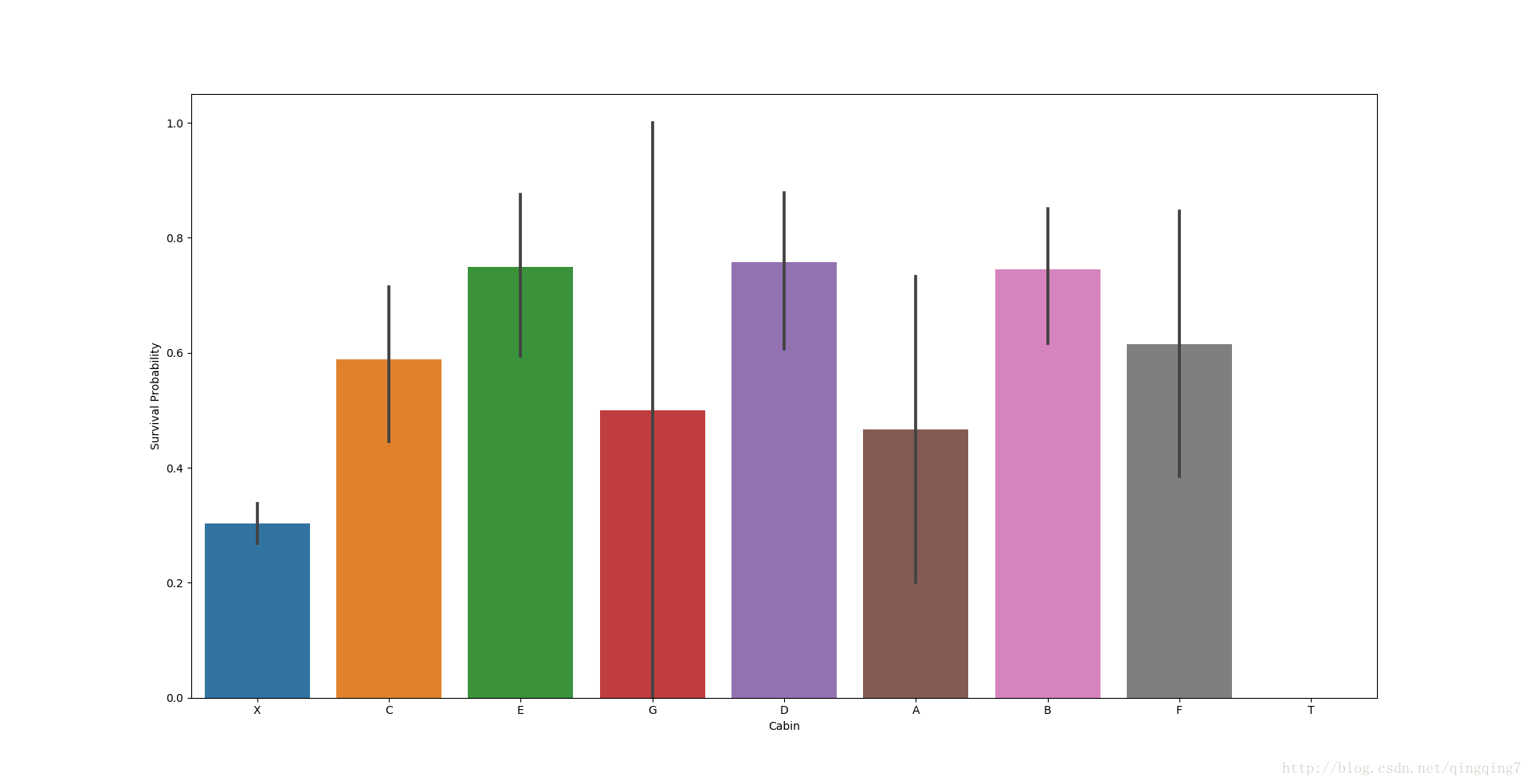
從圖上可以看到不同船艙的倖存率是有差異的,除了T(全部遇難),其他有船艙資訊的倖存率均要高於沒有船艙資訊的乘客,與預期一致。
#利用啞變數將Cabin資訊數值化
dataset=pd.get_dummies(dataset,columns=["Cabin"],prefix="Cabin")
#再來檢視一下船艙資訊
print(dataset.info())結果如下:
RangeIndex: 1299 entries, 0 to 1298
Data columns (total 20 columns):
Age 1299 non-null float64
Embarked 1299 non-null object
Fare 1299 non-null float64
Parch 1299 non-null int64
PassengerId 1299 non-null int64
Pclass 1299 non-null int64
Sex 1299 non-null int64
SibSp 1299 non-null int64
Survived 881 non-null float64
Ticket 1299 non-null object
Title 1299 non-null int32
Cabin_A 1299 non-null uint8
Cabin_B 1299 non-null uint8
Cabin_C 1299 non-null uint8
Cabin_D 1299 non-null uint8
Cabin_E 1299 non-null uint8
Cabin_F 1299 non-null uint8
Cabin_G 1299 non-null uint8
Cabin_T 1299 non-null uint8
Cabin_X 1299 non-null uint8
dtypes: float64(3), int32(1), int64(5), object(2), uint8(9)
memory usage: 118.1+ KB
None4.3 對Ticket進行處理
通過對原始資料進行檢視可以知道,Ticket中包含的資訊也是比較雜亂的,需要做一定處理。船票主要是分為兩種,有字母字首和沒有字母字首的,有字母字首的應該是一些較特殊的票,其中就有類似於現在的VIP這種票,也可能有一些比較差的票。正如之前的分析中講到,將船票這一特徵納入到模型中主要是考慮船票本身能反映票價和位置等資訊從而與生存率相關聯;而相同的字母字首具有相同的性質,因而這裡將字母字首來代替船票資訊。如果是純數字,則歸為同一類“X”。
#對Ticket進行處理
Ticket=[]
for i in list(dataset["Ticket"]):
if not i.isdigit():
Ticket.append(i.replace(".","").replace("/","").strip().split(' ')[0])
else:
Ticket.append("X")
dataset["Ticket"]=Ticket
#檢視替換後的情況
print(dataset["Ticket"].describe())結果如下:
count 1299
unique 37
top X
freq 954
Name: Ticket, dtype: object#檢視不同船票的生存率
g=sns.barplot(data=dataset,x="Ticket",y="Survived")
g.set_ylabel("Survival Probability")
plt.show()結果如下:
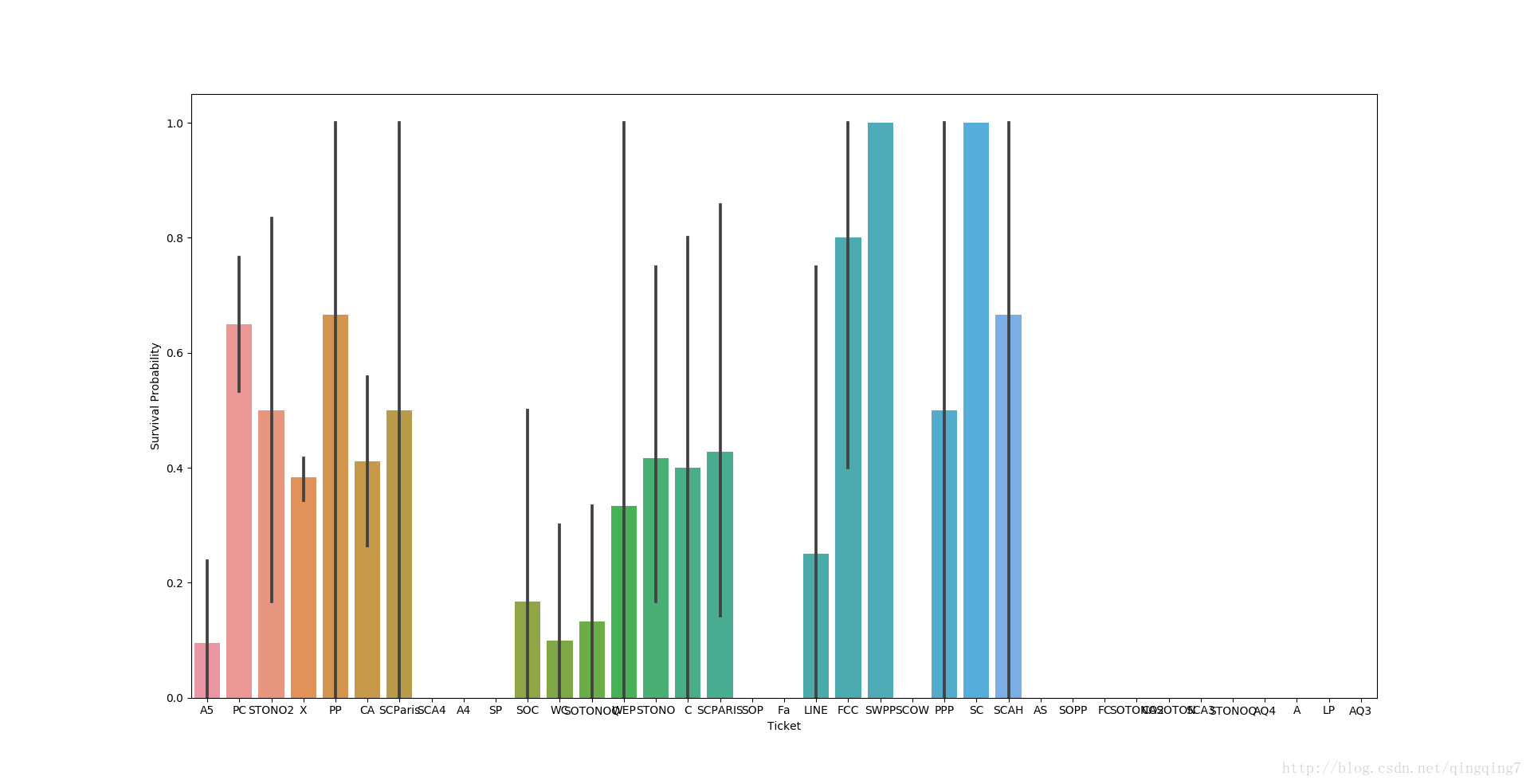
從圖上可以看到不同船票之間的差別。
#利用啞變數將Ticket數值化
dataset=pd.get_dummies(dataset,columns=["Ticket"],prefix="T")4.4 對Embarked進行處理
#將Embarked啞變數化
dataset = pd.get_dummies(dataset, columns = ["Embarked"], prefix="Em")4.4 對Pclass進行處理
#將Pclass啞變數化
dataset["Pclass"] = dataset["Pclass"].astype("category")
dataset = pd.get_dummies(dataset, columns = ["Pclass"],prefix="Pc")4.5 去除PassengerId
dataset.drop(labels = ["PassengerId"], axis = 1, inplace = True)4.6 檢視處理好的資料
#檢視最終資料
#print(dataset.head())
print(dataset.info())結果如下:
RangeIndex: 1299 entries, 0 to 1298
Data columns (total 64 columns):
Age 1299 non-null float64
Fare 1299 non-null float64
Parch 1299 non-null int64
Sex 1299 non-null int64
SibSp 1299 non-null int64
Survived 881 non-null float64
TL_0 1299 non-null uint8
TL_1 1299 non-null uint8
TL_2 1299 non-null uint8
TL_3 1299 non-null uint8
TL_4 1299 non-null uint8
TL_5 1299 non-null uint8
Cabin_A 1299 non-null uint8
Cabin_B 1299 non-null uint8
Cabin_C 1299 non-null uint8
Cabin_D 1299 non-null uint8
Cabin_E 1299 non-null uint8
Cabin_F 1299 non-null uint8
Cabin_G 1299 non-null uint8
Cabin_T 1299 non-null uint8
Cabin_X 1299 non-null uint8
T_A 1299 non-null uint8
T_A4 1299 non-null uint8
T_A5 1299 non-null uint8
T_AQ3 1299 non-null uint8
T_AQ4 1299 non-null uint8
T_AS 1299 non-null uint8
T_C 1299 non-null uint8
T_CA 1299 non-null uint8
T_CASOTON 1299 non-null uint8
T_FC 1299 non-null uint8
T_FCC 1299 non-null uint8
T_Fa 1299 non-null uint8
T_LINE 1299 non-null uint8
T_LP 1299 non-null uint8
T_PC 1299 non-null uint8
T_PP 1299 non-null uint8
T_PPP 1299 non-null uint8
T_SC 1299 non-null uint8
T_SCA3 1299 non-null uint8
T_SCA4 1299 non-null uint8
T_SCAH 1299 non-null uint8
T_SCOW 1299 non-null uint8
T_SCPARIS 1299 non-null uint8
T_SCParis 1299 non-null uint8
T_SOC 1299 non-null uint8
T_SOP 1299 non-null uint8
T_SOPP 1299 non-null uint8
T_SOTONO2 1299 non-null uint8
T_SOTONOQ 1299 non-null uint8
T_SP 1299 non-null uint8
T_STONO 1299 non-null uint8
T_STONO2 1299 non-null uint8
T_STONOQ 1299 non-null uint8
T_SWPP 1299 non-null uint8
T_WC 1299 non-null uint8
T_WEP 1299 non-null uint8
T_X 1299 non-null uint8
Em_C 1299 non-null uint8
Em_Q 1299 non-null uint8
Em_S 1299 non-null uint8
Pc_1 1299 non-null uint8
Pc_2 1299 non-null uint8
Pc_3 1299 non-null uint8
dtypes: float64(3), int64(3), uint8(58)
memory usage: 134.5 KB
None5、 資料建模
#重新獲取訓練資料和測試資料
train=dataset[:train_len]
train["Survived"]=train["Survived"].astype(int)
Y_train=train["Survived"]
X_train=train.drop(labels=["Survived"],axis=1)
test=dataset[train_len:]
test.drop(labels=["Survived"],axis=1,inplace=True)5.1 利用分類演算法進行分類
有時候可能會使用多種演算法進行測試,從中選出比較適應資料場景的演算法;對新樣本的預測也可能是綜合多種演算法的結果;這裡我直接選用隨機森林進行資料分類,之後有時間再做更復雜的訓練。
使用搜索最佳引數的方式進行訓練。
# 搜尋隨機森林的最佳引數
RFC = RandomForestClassifier()
## 設定引數網路
rf_param_grid = {"max_depth": [None],
"max_features": [1, 3, 10],
"min_samples_split": [2, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [False],
"n_estimators" :[100,300],
"criterion": ["gini"]}
gsRFC = GridSearchCV(RFC,param_grid = rf_param_grid, cv=kfold, scoring="accuracy", n_jobs= 1, verbose = 1)
gsRFC.fit(X_train,Y_train)
RFC_best = gsRFC.best_estimator_
print(RFC_best)
# 列印最佳得分
print(gsRFC.best_score_)結果如下:
RandomForestClassifier(bootstrap=False, class_weight=None, criterion='gini',
max_depth=None, max_features=3, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=3, min_samples_split=3,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
0.83427922815從以上結果可以看到,如果使用隨機森林作模型,其最佳配置為max_features=3,min_samples_leaf=3,min_samples_split=3,n_estimators=100,最佳得分為0.83427922815
可以使用不同演算法進行嘗試,優中選優。
5.2 評估模型效果
這裡只通過學習曲線對比欠擬合和過擬合的情況
欠擬合:簡單講就是模型引數太少,不管資料多少,都無法正確反映出資料真實的結構和規律;欠擬合情況下訓練集的效果較差,測試集的效果也差。
在欠擬合情況下,增加樣本數量對模型沒有什麼幫助,因為引數本身不夠,模型先天不足;
過擬合:模型引數太多,資料太少,這樣模型的引數取值會過分的迎合訓練集資料特點,從對訓練集的資料擬合的非常好,但測試集資料結構不一定與訓練集完全一樣,這就導致了此種情況下得到的模型泛化能力很弱,在訓練集之外的資料中效果很差;
在過擬合情況下,增加訓練樣本模型效果會得到提升,因為樣本越多,資料結構就越複雜,從而需要更多引數建立模型。
# 效果評估
#####--------------------------------------------------------------------------------------------------
### 效果評估之學習曲線
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
"""Generate a simple plot of the test and training learning curve"""
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
g = plot_learning_curve(gsRFC.best_estimator_,"RF mearning curves",X_train,Y_train,cv=kfold)
plt.show()結果如下:
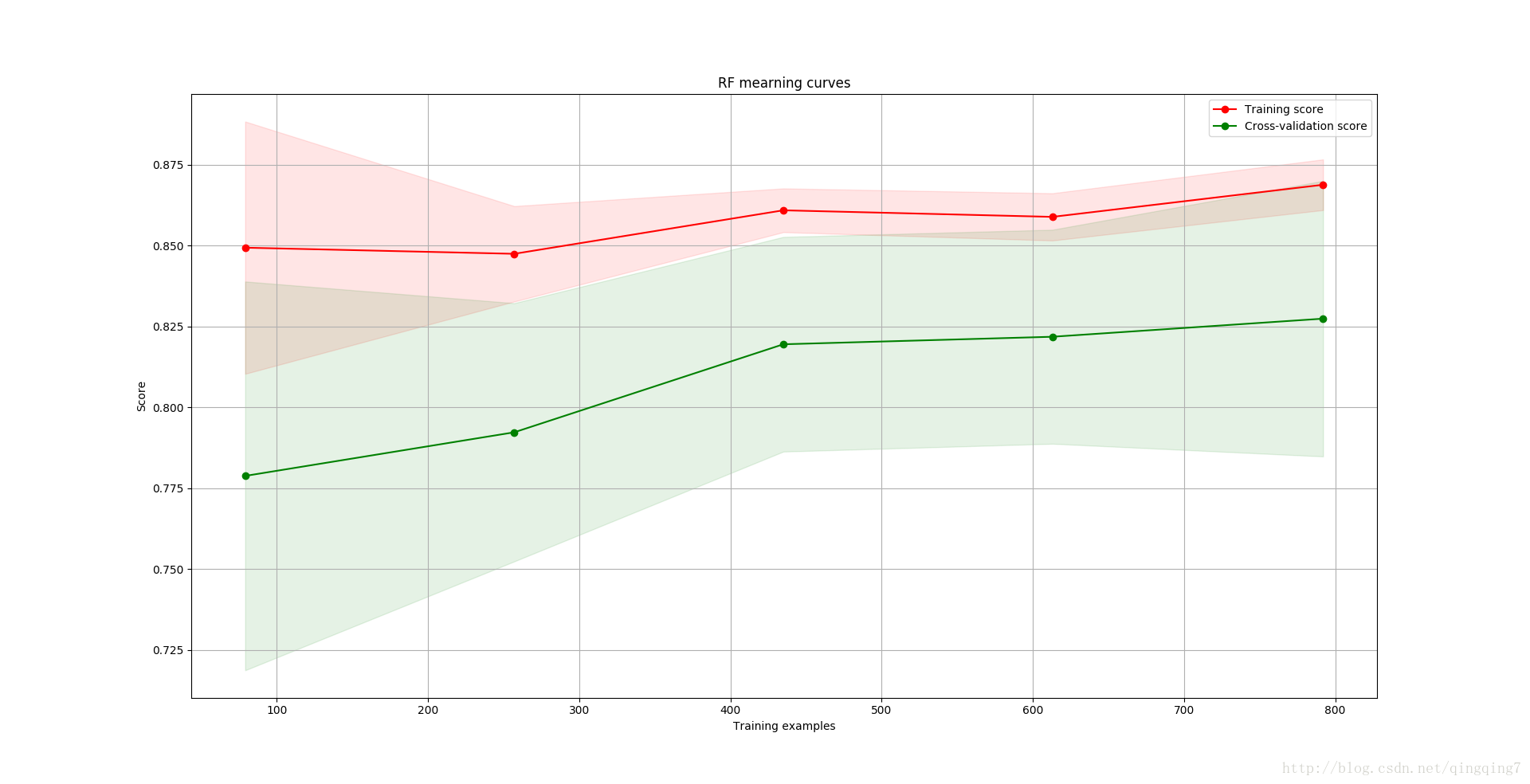
如何檢視學習曲線?
首先看訓練集的得分和交叉驗證的得分會不會隨著樣本增加而產生大的變化,如果樣本增加得分明顯提高說明過擬合;
然後看訓練集得分和交叉驗證得分差別大不大,如果兩差別很大,說明模型在不同資料中表現不一樣,即模型的泛化能力差;
從上圖中可以看到隨機森林演算法中隨著樣本的增多,分類效果變好,說明有一定的過擬合,但變化程度不大,說明過擬合能接受;而訓練樣本中的得分一直都比交叉驗證時的高,這個與實際情況相符;交叉驗證時得分與訓練樣本中的得分差別不大,說明模型的泛化能力不差。
效果的檢視更需要通過與其他演算法對比,才知道哪種演算法比較適應該資料場景。這裡只有一種演算法,只是演示如下檢視學習曲線。
5.3 檢視特徵變數在模型中的權重
不算演算法權重的意義並不完全相同,在迴歸演算法,權重表示迴歸係數,在PCA演算法中,權重僅反映該特徵包含資訊的多少。
# 特徵變數權重分析
#####--------------------------------------------------------------------------------------------------
nrows = ncols = 1
fig, axes = plt.subplots(nrows = nrows, ncols = ncols, sharex="all", figsize=(15,15))
#names_classifiers = [("AdaBoosting", ada_best),("ExtraTrees",ExtC_best),("RandomForest",RFC_best),("GradientBoosting",GBC_best)]
names_classifiers = [("RandomForest",RFC_best)]
nclassifier = 0
for row in range(nrows):
for col in range(ncols):
name = names_classifiers[nclassifier][0]
classifier = names_classifiers[nclassifier][1]
indices = np.argsort(classifier.feature_importances_)[::-1][:40]
g = sns.barplot(y=X_train.columns[indices][:40],x = classifier.feature_importances_[indices][:40] , orient='h',ax=axes[row][col])
g.set_xlabel("Relative importance",fontsize=12)
g.set_ylabel("Features",fontsize=12)
g.tick_params(labelsize=9)
g.set_title(name + " feature importance")
nclassifier += 1
plt.show()結果如下:
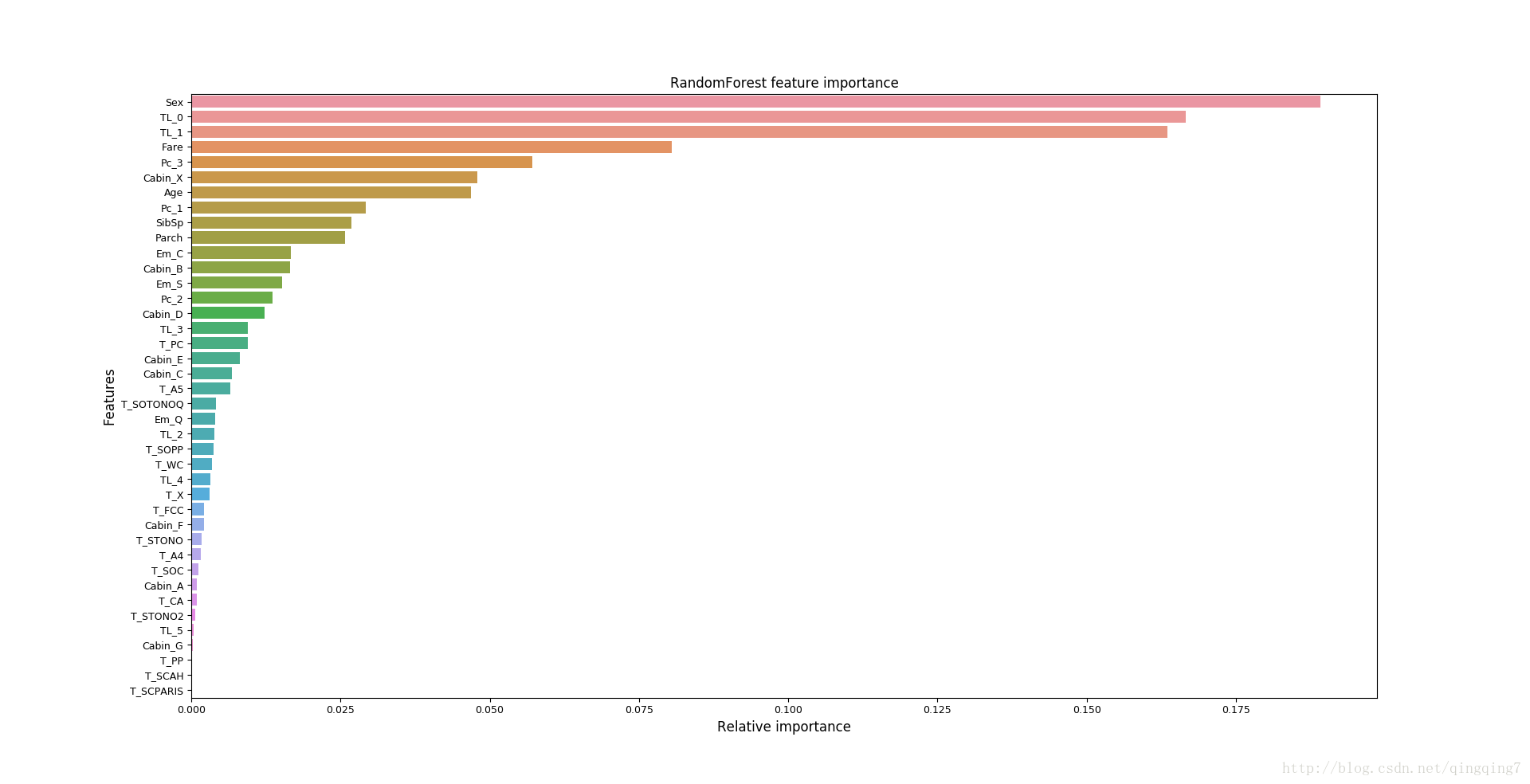
從上圖可以看到,在隨機森林的生成模型中,對預測結果產生最大權重的特徵是sex,然後是TL_0和TL_1;
如果對比不同演算法,可能會看到在不同演算法中,各特徵權重並不是完全相同的。還有一個有趣的現象,同樣的演算法,同樣的輸入,兩次跑的結果中不同特徵的權重可能也不一樣,像隨機森林之類演算法也好理解,畢竟在抽取樣本和特徵組成新資料集的時候本身也存在隨機性。
5.4 整合預測
利用多種演算法建模並對測試樣本進行預測
其思想其實跟隨機森林的整體思想是一樣的,對最後的結果採取少數服從多數的策略。
# 整合預測
#####--------------------------------------------------------------------------------------------------
votingC = VotingClassifier(estimators=[('rfc', RFC_best),('svc', SVMC_best)], voting='soft', n_jobs=4)#裡面放的是各演算法最佳引數之下的模型
votingC = votingC.fit(X_train, Y_train)
test_Survived = pd.Series(votingC.predict(test), name="Survived")
results = pd.concat([IDtest,test_Survived],axis=1)
results.to_csv("ensemble_python_voting.csv",index=False)對測試集的預測結果儲存至當前資料夾的ensemble_python_voting.csv檔案中。
至此單機版的資料探勘整個過程就大致如此了!