
Java提高篇之hashCode
本文轉自:http://www.cnblogs.com/chenssy/p/3651218.html
本文作者個人站點:http://cmsblogs.com/,裡面有一系列java方面的原始碼解讀,個人表示寫的還可以~~~~
在前面三篇博文中LZ講解了(HashMap、HashSet、HashTable),在其中LZ不斷地講解他們的put和get方法,在這兩個方法中計算key的hashCode應該是最重要也是最精華的部分,所以下面LZ揭開hashCode的“神祕”面紗。
hashCode的作用
要想了解一個方法的內在原理,我們首先需要明白它是幹什麼的,也就是這個方法的作用。在講解陣列時(java提高篇(十八)——陣列),我們提到陣列是java中效率最高的資料結構,但是“最高”是有前提的。第一我們需要知道所查詢資料的所在位置。第二:如果我們進行迭代查詢時,資料量一定要小,對於大資料量而言一般推薦集合。
在Java集合中有兩類,一類是List,一類是Set他們之間的區別就在於List集合中的元素師有序的,且可以重複,而Set集合中元素是無序不可重複的。對於List好處理,但是對於Set而言我們要如何來保證元素不重複呢?通過迭代來equals()是否相等。資料量小還可以接受,當我們的資料量大的時候效率可想而知(當然我們可以利用演算法進行優化)。比如我們向HashSet插入1000資料,難道我們真的要迭代1000次,呼叫1000次equals()方法嗎?hashCode提供瞭解決方案。怎麼實現?我們先看hashCode的原始碼(Object)。
public native int hashCode();它是一個本地方法,它的實現與本地機器有關,這裡我們暫且認為他返回的是物件儲存的物理位置(實際上不是,這裡寫是便於理解)。當我們向一個集合中新增某個元素,集合會首先呼叫hashCode方法,這樣就可以直接定位它所儲存的位置,若該處沒有其他元素,則直接儲存。若該處已經有元素存在,就呼叫equals方法來匹配這兩個元素是否相同,相同則不存,不同則雜湊到其他位置(具體情況請參考(Java提高篇()—–HashMap))。這樣處理,當我們存入大量元素時就可以大大減少呼叫equals()方法的次數,極大地提高了效率。
所以hashCode在上面扮演的角色為尋域(尋找某個物件在集合中區域位置)。hashCode可以將集合分成若干個區域,每個物件都可以計算出他們的hash碼,可以將hash碼分組,每個分組對應著某個儲存區域,根據一個物件的hash碼就可以確定該物件所儲存區域,這樣就大大減少查詢匹配元素的數量,提高了查詢效率。
hashCode對於一個物件的重要性
hashCode重要麼?不重要,對於List集合、陣列而言,他就是一個累贅,但是對於HashMap、HashSet、HashTable而言,它變得異常重要。所以在使用HashMap、HashSet、HashTable時一定要注意hashCode。對於一個物件而言,其hashCode過程就是一個簡單的Hash演算法的實現,其實現過程對你實現物件的存取過程起到非常重要的作用。
在前面LZ提到了HashMap和HashTable兩種資料結構,雖然他們存在若干個區別,但是他們的實現原理是相同的,這裡我以HashTable為例闡述hashCode對於一個物件的重要性。
一個物件勢必會存在若干個屬性,如何選擇屬性來進行雜湊考驗著一個人的設計能力。如果我們將所有屬性進行雜湊,這必定會是一個糟糕的設計,因為物件的hashCode方法無時無刻不是在被呼叫,如果太多的屬性參與雜湊,那麼需要的運算元時間將會大大增加,這將嚴重影響程式的效能。但是如果較少屬相參與雜湊,雜湊的多樣性會削弱,會產生大量的雜湊“衝突”,除了不能夠很好的利用空間外,在某種程度也會影響物件的查詢效率。其實這兩者是一個矛盾體,雜湊的多樣性會帶來效能的降低。
那麼如何對物件的hashCode進行設計,LZ也沒有經驗。從網上查到了這樣一種解決方案:設定一個快取標識來快取當前的雜湊碼,只有當參與雜湊的物件改變時才會重新計算,否則呼叫快取的hashCode,這樣就可以從很大程度上提高效能。
在HashTable計算某個物件在table[]陣列中的索引位置,其程式碼如下:
int index = (hash & 0x7FFFFFFF) % tab.length;為什麼要&0x7FFFFFFF?因為某些物件的hashCode可能會為負值,與0x7FFFFFFF進行與運算可以確保index為一個正數。通過這步我可以直接定位某個物件的位置,所以從理論上來說我們是完全可以利用hashCode直接定位物件的散列表中的位置,但是為什麼會存在一個key-value的鍵值對,利用key的hashCode來存入資料而不是直接存放value呢?這就關係HashTable效能問題的最重要的問題:Hash衝突!
我們知道衝突的產生是由於不同的物件產生了相同的雜湊碼,假如我們設計物件的雜湊碼可以確保99.999999999%的不重複,但是有一種絕對且幾乎不可能遇到的衝突你是絕對避免不了的。我們知道hashcode返回的是int,它的值只可能在int範圍內。如果我們存放的資料超過了int的範圍呢?這樣就必定會產生兩個相同的index,這時在index位置處會儲存兩個物件,我們就可以利用key本身來進行判斷。所以具有相索引的物件,在該index位置處存在多個物件,我們必須依靠key的hashCode和key本身來進行區分。
hashCode與equals
在Java中hashCode的實現總是伴隨著equals,他們是緊密配合的,你要是自己設計了其中一個,就要設計另外一個。當然在多數情況下,這兩個方法是不用我們考慮的,直接使用預設方法就可以幫助我們解決很多問題。但是在有些情況,我們必須要自己動手來實現它,才能確保程式更好的運作。
對於equals,我們必須遵循如下規則:
-
對稱性:如果x.equals(y)返回是“true”,那麼y.equals(x)也應該返回是“true”。
-
反射性:x.equals(x)必須返回是“true”。
-
類推性:如果x.equals(y)返回是“true”,而且y.equals(z)返回是“true”,那麼z.equals(x)也應該返回是“true”。
-
一致性:如果x.equals(y)返回是“true”,只要x和y內容一直不變,不管你重複x.equals(y)多少次,返回都是“true”。
任何情況下,x.equals(null),永遠返回是“false”;x.equals(和x不同型別的物件)永遠返回是“false”。
對於hashCode,我們應該遵循如下規則:
1. 在一個應用程式執行期間,如果一個物件的equals方法做比較所用到的資訊沒有被修改的話,則對該物件呼叫hashCode方法多次,它必須始終如一地返回同一個整數。
2. 如果兩個物件根據equals(Object o)方法是相等的,則呼叫這兩個物件中任一物件的hashCode方法必須產生相同的整數結果。
3. 如果兩個物件根據equals(Object o)方法是不相等的,則呼叫這兩個物件中任一個物件的hashCode方法,不要求產生不同的整數結果。但如果能不同,則可能提高散列表的效能。
至於兩者之間的關聯關係,我們只需要記住如下即可:
如果x.equals(y)返回“true”,那麼x和y的hashCode()必須相等。
如果x.equals(y)返回“false”,那麼x和y的hashCode()有可能相等,也有可能不等。
理清了上面的關係我們就知道他們兩者是如何配合起來工作的。先看下圖:
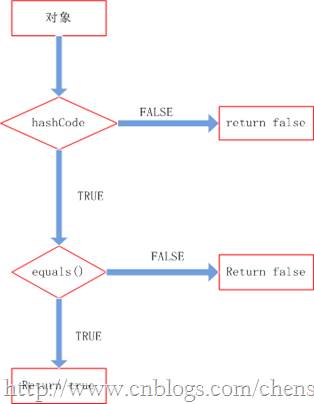
整個處理流程是:
1、判斷兩個物件的hashcode是否相等,若不等,則認為兩個物件不等,完畢,若相等,則比較equals。
2、若兩個物件的equals不等,則可以認為兩個物件不等,否則認為他們相等。
例項:
public class Person {
private int age;
private int sex; //0:男,1:女
private String name;
private final int PRIME = 37;
Person(int age ,int sex ,String name){
this.age = age;
this.sex = sex;
this.name = name;
}
/** 省略getter、setter方法 **/
@Override
public int hashCode() {
System.out.println("呼叫hashCode方法...........");
int hashResult = 1;
hashResult = (hashResult + Integer.valueOf(age).hashCode() + Integer.valueOf(sex).hashCode()) * PRIME;
hashResult = PRIME * hashResult + ((name == null) ? 0 : name.hashCode());
System.out.println("name:"+name +" hashCode:" + hashResult);
return hashResult;
}
/**
* 重寫hashCode()
*/
public boolean equals(Object obj) {
System.out.println("呼叫equals方法...........");
if(obj == null){
return false;
}
if(obj.getClass() != this.getClass()){
return false;
}
if(this == obj){
return true;
}
Person person = (Person) obj;
if(getAge() != person.getAge() || getSex()!= person.getSex()){
return false;
}
if(getName() != null){
if(!getName().equals(person.getName())){
return false;
}
}
else if(person != null){
return false;
}
return true;
}
}
該Bean為一個標準的Java Bean,重新實現了hashCode方法和equals方法。public class Main extends JPanel {
public static void main(String[] args) {
Set<Person> set = new HashSet<Person>();
Person p1 = new Person(11, 1, "張三");
Person p2 = new Person(12, 1, "李四");
Person p3 = new Person(11, 1, "張三");
Person p4 = new Person(11, 1, "李四");
//只驗證p1、p3
System.out.println("p1 == p3? :" + (p1 == p3));
System.out.println("p1.equals(p3)?:"+p1.equals(p3));
System.out.println("-----------------------分割線--------------------------");
set.add(p1);
set.add(p2);
set.add(p3);
set.add(p4); System.out.println("set.size()="+set.size());
}
}
執行結果如下:
從上圖可以看出,程式呼叫四次hashCode方法,一次equals方法,其set的長度只有3。add方法執行流程完全符合他們兩者之間的處理流程。