
mysql的limit用法、邏輯分頁和物理分頁
物理分頁為什麼用limit
在講解limit之間,我們先說說分頁的事情。
分頁有邏輯分頁和物理分頁,就像刪除有邏輯刪除和物理刪除。邏輯刪除就是改變資料庫的狀態,物理刪除就是直接刪除資料庫的記錄,而邏輯刪除只是改變該資料庫的狀態。例如

同理,邏輯分頁和物理分頁是有區別的
| 物理分頁 | 邏輯分頁 | Cool |
|---|---|---|
| 物理分頁依賴的是某一物理實體,這個物理實體就是資料庫,比如MySQL資料庫提供了limit關鍵字,程式設計師只需要編寫帶有limit關鍵字的SQL語句,資料庫返回的就是分頁結果。 | 邏輯分頁依賴的是程式設計師編寫的程式碼。資料庫返回的不是分頁結果,而是全部資料,然後再由程式設計師通過程式碼獲取分頁資料,常用的操作是一次性從資料庫中查詢出全部資料並存儲到List集合中,因為List集合有序,再根據索引獲取指定範圍的資料。 | 概念 |
| 每次都要訪問資料庫,對資料庫造成的負擔大 | 只需要訪問一次資料庫 | 資料庫負擔 |
| 每次只讀取一部分資料,佔用的記憶體空間較小 | 一次性將資料讀取到記憶體,佔用較大的記憶體空間。如果使用java開發,Java本身引用的框架就佔用了很多記憶體,這無疑加重了伺服器的負擔。 | 伺服器負擔 |
| 每次需要資料時都訪問資料庫,能夠獲取資料庫的最新狀態,實時性強 | 因為一次性讀入到記憶體,資料發生了改變,資料庫逇最新狀態無法實時反映到操作中 | 實時性 |
| 資料庫量大、更新頻繁的場合 | 資料量較小、資料穩定的場合 | 伺服器負擔 |
為什麼邏輯分頁佔用較大的記憶體空間,比如我有一張表,表的資訊是:
-- ----------------------------
-- Table structure for vote_record_memory
-- ----------------------------
DROP TABLE IF EXISTS `vote_record_memory`;
CREATE TABLE `vote_record_memory` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(20) NOT NULL,
`vote_id` int(11) NOT NULL,
`group_id` 向該表中插入300萬條資料後,再轉儲到桌面,檢視轉儲後的SQL檔案的屬性:
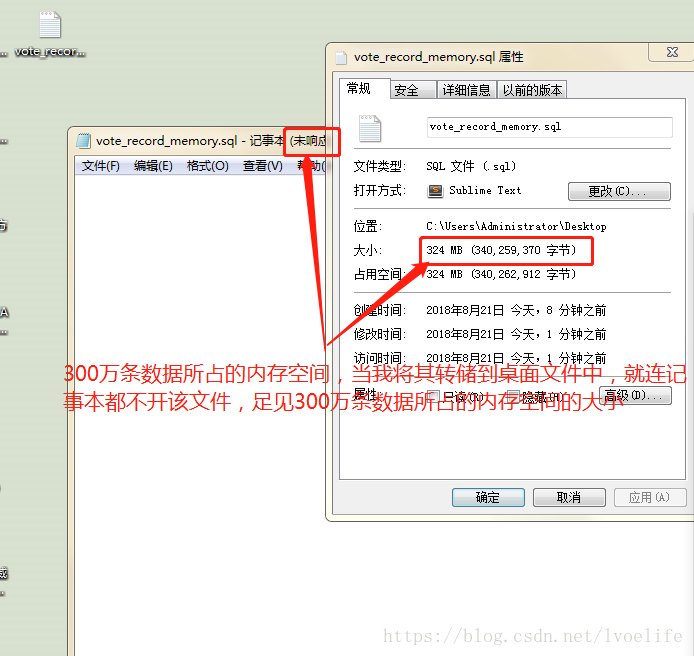
這是多麼龐大的資料,佔用的記憶體多麼可怕,為什麼我們再選用資料庫。這也是我們使用雲伺服器時,設定mysql的儲存空間的大小。
我們一般不推薦使用邏輯分頁,而使用物理分頁。在使用物理分頁的時候,就要考慮到limit的用法。
解釋limit
limit X,Y ,跳過前X條資料,讀取Y條資料
- X表示第一個返回記錄行的偏移量,Y表示返回記錄行的最大數目
- 如果X為0的話,即 limit 0, Y,相當於limit Y、
通過業務分析limit
- 我有一張工資表,只顯示最新的前兩條記錄,同時進行員工姓名和工資提成備註查詢
SELECT
cue.real_name empName,
zs.push_money AS pushMoney,
zs.push_money_note AS pushMoneyNote,
zs.create_datetime AS createTime
FROM
zq_salary zs //主表
LEFT JOIN core_user_ext cue ON cue.id = zs.user_id //從表 on之後是從表的條件
WHERE
zs.is_deleted = 0
AND (
cue.real_name LIKE '%李%'
OR zs.push_money_note LIKE '%測%'
)
ORDER BY
zs.create_datetime DESC
LIMIT 2;
就相當於
ORDER BY
zs.create_datetime DESC
LIMIT 0,2;
limit的效率問題
- 我有一個需求,就是從vote_record_memory表中查出3600000到3800000的資料,此時在id上加個索引,索引的型別是Normal,索引的方法是BTREE,分別用兩種方法查詢
-- 方法1
SELECT * FROM vote_record_memory vrm LIMIT 3600000,20000 ;
-- 方法2
SELECT * FROM vote_record_memory vrm WHERE vrm.id >= 3600000 LIMIT 20000 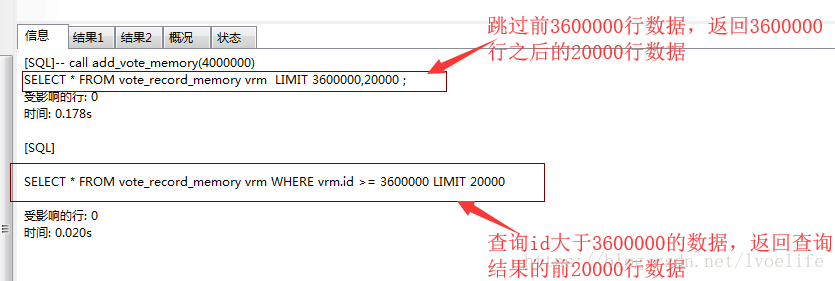
你會發現,方法2的執行效率遠比方法1的執行效率高,幾乎是方法1的九分之一的時間。
為什麼方法1的效率低,而方法二的效率高呢?
分析一、
因為在方法1中,我們使用的單純的limit。limit隨著行偏移量的增大,當大到一定程度後,會出現效率下降。而方法2用上索引加where和limit,效能基本穩定,受偏移量和行數的影響不大。分析二、
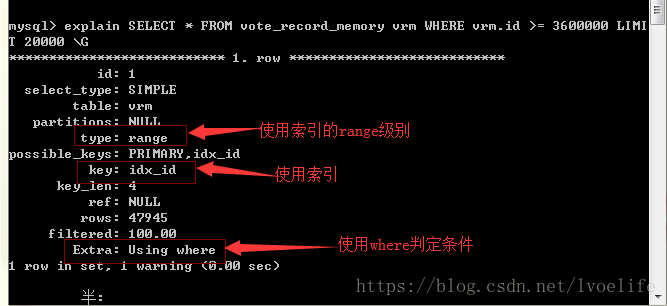
我們用explain來分析
可見,limit語句的執行效率未必很高,因為會進行全表掃描,這就是為什麼方法1掃描的的行數是400萬行的原因。方法2的掃描行數是47945行,這也是為什麼方法2執行效率高的原因。我們儘量避免全表掃描查詢,尤其是資料非常龐大,這張表僅有400萬條資料,方法1和方法就有這麼大差距,可想而知上千萬條的資料呢。
能用索引的儘量使用索引,type至少達到range級別,這不是我說的,這是阿里巴巴開發手冊的5.2.8中要求的
我不用索引查詢到的結果和返回的時間和方法1的時間差不多:


SELECT * FROM vote_record_memory vrm WHERE vrm.id >= 3600000 LIMIT
20000 受影響的行: 0 時間: 0.196s
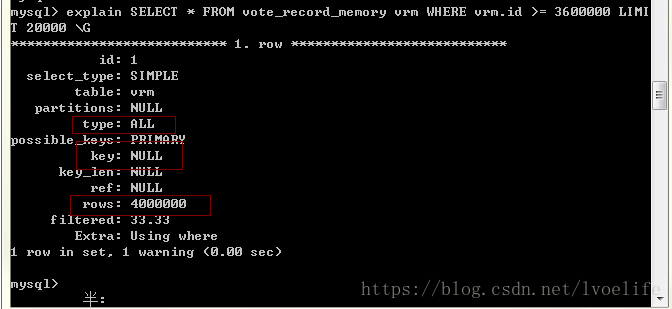
這也就是我們為什麼儘量使用索引的原因。mysql索引方法一般有BTREE索引和HASH索引,hash索引的效率比BTREE索引的效率高,但我們經常使用BTREE索引,而不是hash索引。因為最重要的一點就是:Hash索引僅僅能滿足”=”,”IN”和”<=>”查詢,不能使用範圍查詢。
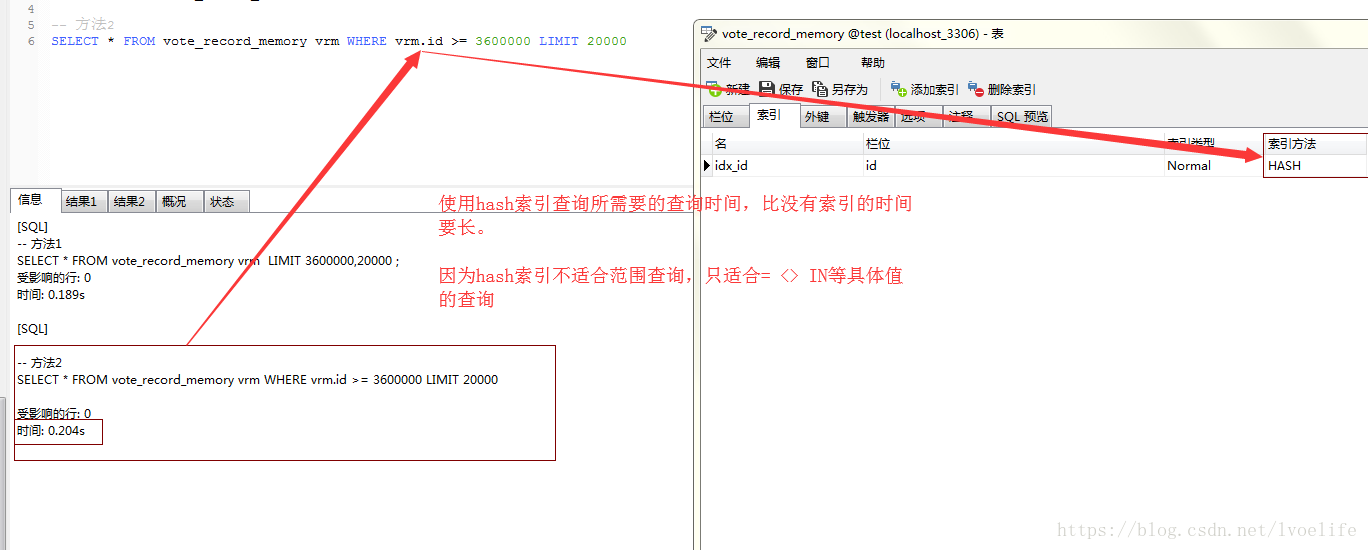
如果是範圍查詢,我們為什麼用BTREE索引的原因。BTREE索引就是二叉樹索引,學過資料結構的應該都清楚,這裡就不贅述了。
limit物理分頁
我們都知道limit一般有兩個引數,X和Y,X表示跳過X個數據,讀取Y個數據,我們就此來查詢資料

| 頁數 | 每頁顯示的行數 | limit語句 | 計算方式 |
|---|---|---|---|
| 第一頁 | 20 | limit 0,20 | limit 0*20,20 |
| 第二頁 | 20 | limit 20,20 | limit 1*20,20 |
| 第三頁 | 20 | limit 40,20 | limit 2*20,20 |
| 第四頁 | 20 | limit 60,20 | limit 3*20,20 |
如果是SQL語句來進行分頁的話,我們可以看到的是:
-- 首頁
SELECT * from vote_record_memory LIMIT 0,20;
-- 第二頁
SELECT * from vote_record_memory LIMIT 20,20;
-- 第三頁
SELECT * from vote_record_memory LIMIT 40,20;
-- 第四頁
SELECT * from vote_record_memory LIMIT 60,20;
-- n頁
SELECT * from vote_record_memory LIMIT (n-1)*20,20;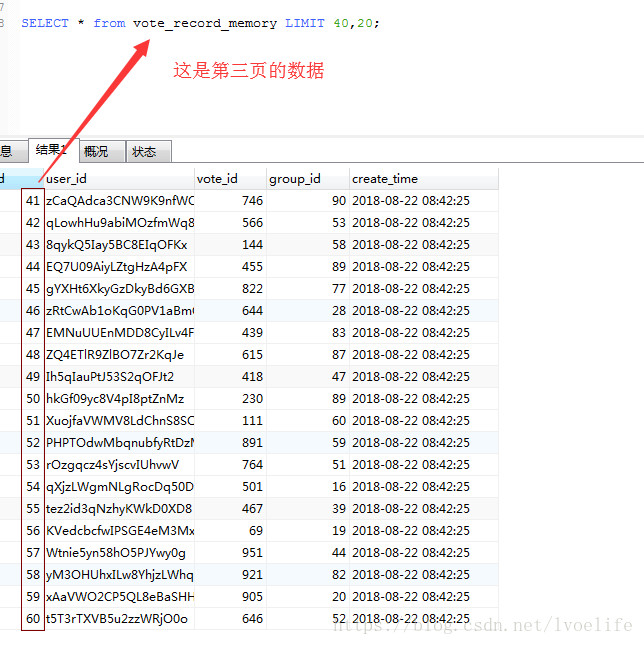
因而,如果是用java的話,我們就可以寫一個方法,有兩個引數,一個是頁數,一個每頁顯示的行數
/**
* @description 簡單的模擬分頁雛形
* @author zby
* @param currentPage 當前頁
* @param lines 每頁顯示的多少條
* @return 資料的集合
*/
public List<Object> listObjects(int currentPage, int lines) {
String sql = "SELECT * from vote_record_memory LIMIT " + (currentPage - 1) * lines + "," + lines;
return null;
}