
Sharding-JDBC 讀寫分離
環境概覽
| 框架 | 版本號 |
| Spring Boot | 1.5.12.RELEASE |
| Sharding-JDBC | 2.0.3 |
| MyBatis-Plus | 2.2.0 |
前言介紹
Sharding-JDBC是噹噹網的一個開源專案,只需引入jar即可輕鬆實現讀寫分離與分庫分表。與MyCat不同的是,Sharding-JDBC致力於提供輕量級的服務框架,無需額外部署,底層是對JDBC進行增強,相容各種連線池和ORM框架。不僅如此還提供分散式事務及分散式治理功能,即將出世的3.X版本可能會提供更加全面的功能。有興趣的小夥伴們,可以去了解下,這裡提供官方文件、GitHub地址
讀寫分離
引自Sharding-JDBC官方文件
面對日益增加的系統訪問量,資料庫的吞吐量面臨著巨大瓶頸。 對於同一時間有大量併發讀操作和較少寫操作型別的應用系統來說,將單一的資料庫拆分為主庫和從庫,主庫負責處理事務性的增刪改操作,從庫負責處理查詢操作,能夠有效的避免由資料更新導致的行鎖,使得整個系統的查詢效能得到極大的改善。 通過一主多從的配置方式,可以將查詢請求均勻的分散到多個數據副本,能夠進一步的提升系統的處理能力。 使用多主多從的方式,不但能夠提升系統的吞吐量,還能夠提升系統的可用性,可以達到在任何一個數據庫宕機,甚至磁碟物理損壞的情況下仍然不影響系統的正常執行。
雖然讀寫分離可以提升系統的吞吐量和可用性,但同時也帶來了資料不一致的問題,這包括多個主庫之間的資料一致性,以及主庫與從庫之間的資料一致性的問題。並且,讀寫分離也帶來了與資料分片同樣的問題,它同樣會使得應用開發和運維人員對資料庫的操作和運維變得更加複雜。透明化讀寫分離所帶來的影響,讓使用方儘量像使用一個數據庫一樣使用主從資料庫,是讀寫分離中介軟體的主要功能。
讀寫分離,簡單來說,就是將DML交給主資料庫去執行,將更新結果同步至各個從資料庫保持主從資料一致,DQL分發給從資料庫去查詢,從資料庫只提供讀取查詢操作。讀寫分離特別適用於讀多寫少的場景下,通過分散讀寫到不同的資料庫例項上來提高效能,緩解單機資料庫的壓力。
這裡解釋一下什麼是DML和DQL?SQL語言四大分類:DQL、DML、DDL、DCL。
- DQL(Data QueryLanguage):資料查詢語言,比如select查詢語句
- DML(Data Manipulation Language):資料操縱語言,比如insert、delete、update更新語句
- DDL():資料定義語言,比如create/drop/alter等語句
- DCL():資料控制語言,比如grant/rollback/commit等語句
實現步驟
實現步驟非常簡單,僅需兩步,即可在程式碼上實現讀寫分離功能,感覺非常帶勁。
1.引入jar包
<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core-spring-boot-starter</artifactId>
<version>2.0.3</version>
</dependency>2.配置讀寫分離
sharding:
jdbc:
# 配置真實資料來源
datasource:
names: ds_master_0,ds_slave_0_1,ds_slave_0_2
# 配置主庫
ds_master_0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://ip:3306/test?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true
username: username
password: password
maxPoolSize: 20
# 配置第一個從庫
ds_slave_0_1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://ip:3307/test?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true
username: username
password: password
maxPoolSize: 20
# 配置第二個從庫
ds_slave_0_2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://ip:3308/test?useSSL=false&useUnicode=true&characterEncoding=utf8&autoReconnect=true
username: username
password: password
maxPoolSize: 20
# 配置讀寫分離
config:
masterslave:
# 配置從庫選擇策略,提供輪詢與隨機,這裡選擇用輪詢
load-balance-algorithm-type: round_robin
name: ds_m_1_s_2
master-data-source-name: ds_master_0
slave-data-source-names: ds_slave_0_1,ds_slave_0_2
sharding:
props:
# 開啟SQL顯示,預設值: false,注意:僅配置讀寫分離時不會列印日誌!!!
sql:
show: true準備測試
在測試開始之前,我們先明確一點,由於只配置了讀寫分離,即使上文中配置了sql.show=true也不會有日誌打印出來(如果配置了分庫/分表就不會有這種情況),那麼我們怎麼知道資料庫操作到底是走的主庫還是主庫呢?怎麼知道如果走從庫有沒有遵循輪詢演算法走的具體是哪個從庫呢?
帶著上述的疑問,追溯原始碼進入MasterSlaveDataSource這個類中(友情提示:IDEA連續按兩次shift在彈框中輸入MasterSlaveDataSource即可檢視該類),主要關注其中的getDataSource()方法。下面貼出關鍵原始碼。
/**
* Get data source from master-slave data source.
*
* @param sqlType SQL type
* @return data source from master-slave data source
*/
public NamedDataSource getDataSource(final SQLType sqlType) {
if (isMasterRoute(sqlType)) {
DML_FLAG.set(true);
return new NamedDataSource(masterSlaveRule.getMasterDataSourceName(), masterSlaveRule.getMasterDataSource());
}
String selectedSourceName = masterSlaveRule.getStrategy().getDataSource(masterSlaveRule.getName(),
masterSlaveRule.getMasterDataSourceName(), new ArrayList<>(masterSlaveRule.getSlaveDataSourceMap().keySet()));
DataSource selectedSource = selectedSourceName.equals(masterSlaveRule.getMasterDataSourceName())
? masterSlaveRule.getMasterDataSource() : masterSlaveRule.getSlaveDataSourceMap().get(selectedSourceName);
Preconditions.checkNotNull(selectedSource, "");
return new NamedDataSource(selectedSourceName, selectedSource);
}
private boolean isMasterRoute(final SQLType sqlType) {
return SQLType.DQL != sqlType || DML_FLAG.get() || HintManagerHolder.isMasterRouteOnly();
}isMasterRoute() 方法判斷當前操作是否應該路由到主庫資料來源,如果SQL型別是DML則返回true
getDataSource() 方法根據SQL型別返回一個數據源。如果SQL型別是DQL則通過配置的演算法返回一個從庫資料來源,如果SQL型別是DML則返回主庫資料來源。
那麼瞭解了以上兩個方法後,通過打斷點DEBUG的方式,我們可以很容易的得知,執行SQL時到底走的是哪個庫。
開始測試
這邊我準備了兩個測試介面,一個用於測試讀操作,一個用於測試寫操作。
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private IUserService userService;
/**
* 查詢使用者列表
* @return
*/
@GetMapping
public List<User> getUser() {
return userService.selectList(null);
}
/**
* 建立/修改使用者資訊
* @param user
* @return
*/
@PostMapping
public User saveUser(@RequestBody User user) {
return userService.insertOrUpdate(user) ? userService.selectById(user.getId()) : null;
}
}發起GET請求/users介面,期望通過輪詢演算法去從庫中查詢獲取資料
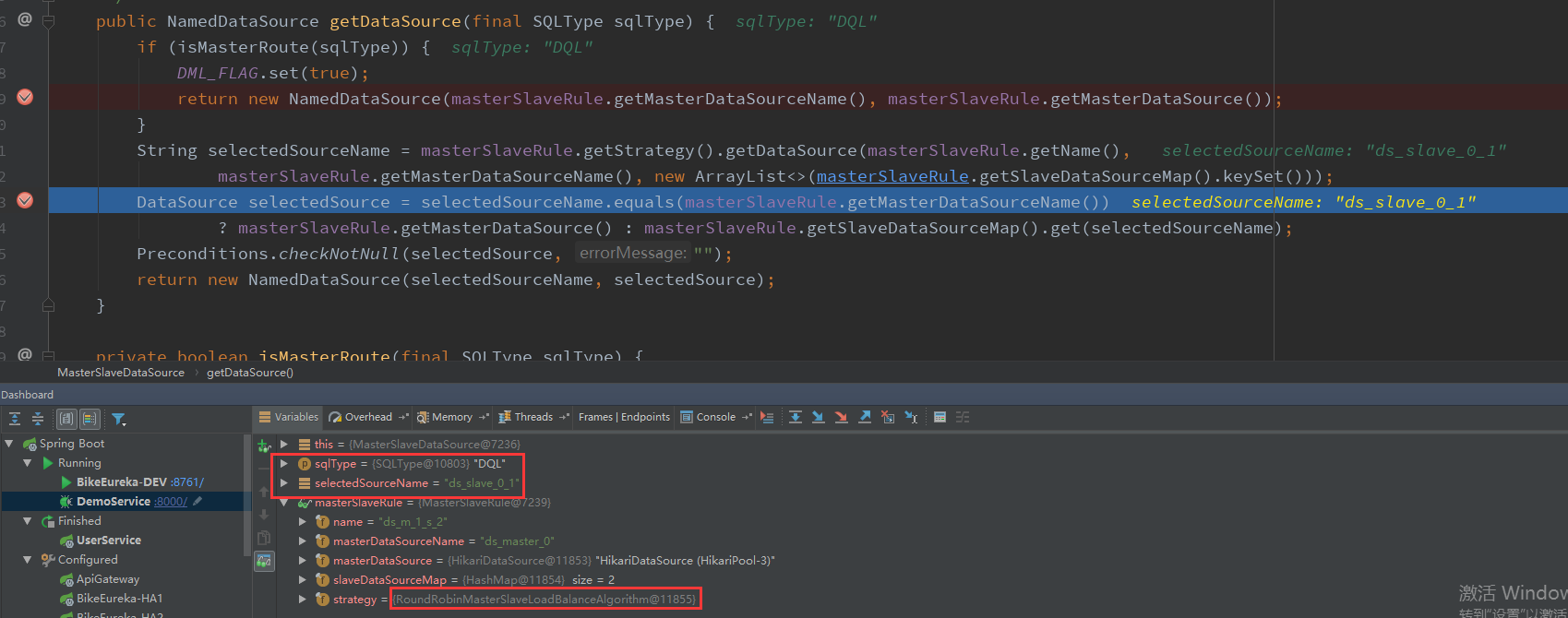
第一次,通過上圖我們可以很容易發現SQL型別是DQL,走的是ds_slave_0_1從資料庫,且策略是輪詢策略
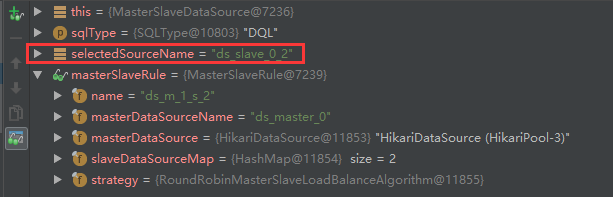
第二次,我們可以發現走的是ds_slave_0_2從資料庫,讀操作和輪詢演算法都沒毛病
發起POST請求/users介面,期望從主庫中建立或修改使用者資料。
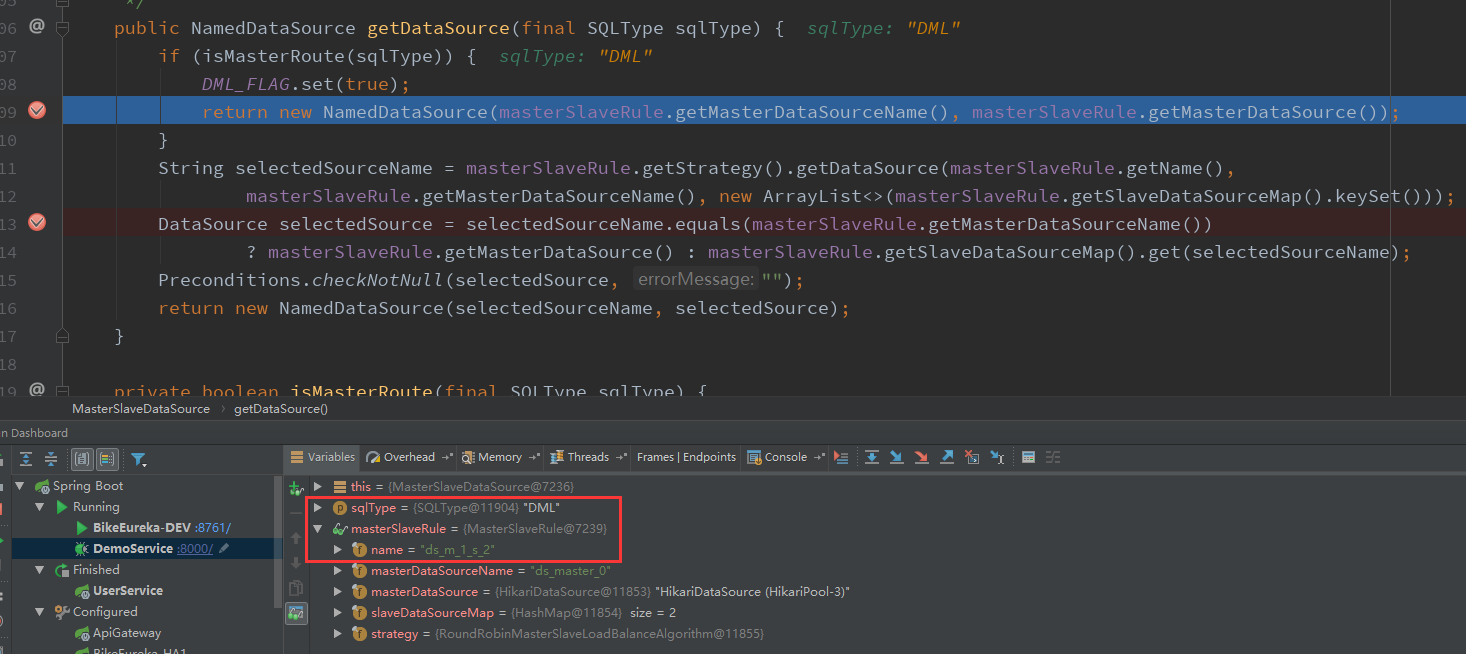

可見,寫操作時,走的是ds_master_0主資料庫。當userService.insertOrUpdate(user)執行成功返回true後,接著再執行userService.selectById(user.getId())時,又會走到ds_slave_0_1從庫讀取資料。寫操作也沒毛病,以上我們的測試階段就大功告成了。
輪詢策略
有興趣的小夥伴可以看下輪詢策略的原始碼,非常的簡單。這裡貼出輪詢策略主要原始碼
/**
* Round-robin slave database load-balance algorithm.
*
* @author zhangliang
*/
public final class RoundRobinMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
private static final ConcurrentHashMap<String, AtomicInteger> COUNT_MAP = new ConcurrentHashMap<>();
@Override
public String getDataSource(final String name, final String masterDataSourceName, final List<String> slaveDataSourceNames) {
AtomicInteger count = COUNT_MAP.containsKey(name) ? COUNT_MAP.get(name) : new AtomicInteger(0);
COUNT_MAP.putIfAbsent(name, count);
count.compareAndSet(slaveDataSourceNames.size(), 0);
return slaveDataSourceNames.get(count.getAndIncrement() % slaveDataSourceNames.size());
}
}其內部通過併發容器ConcurrentHashMap與AtomicInteger的CAS保障高併發下計數執行緒安全,使用無鎖的方式比加鎖效率更高。
靈活性
Sharding-JDBC使用簡單,容易上手且十分靈活,不僅可以使用預設策略,還可以使用自定義的策略。可以說是對Java開發者十分的友好,通過寫Java程式碼的方式就可以實現更加深度的定製化路由規則。這裡如果想要自定義輪詢策略可以使用如下配置來自定義的輪詢策略。
sharding:
jdbc:
config:
masterslave:
load-balance-algorithm-class-name: 自定義演算法類的全限定名注意點
在玩轉讀寫分離時,遇到如下幾個需要注意的地方
- Sharding-JDBC目前僅支援一主多從的結構
- Sharding-JDBC沒有提供主從同步的實現,該功能需要自己額外搭建,可參照《基於Docker搭建MySQL主從複製》簡易搭建測試使用
- 主庫和從庫的資料同步延遲導致的資料不一致問題需要自己去解決
- Sharding-JDBC雖然提供了列印SQL日誌的開關,但是如果僅配置了讀寫分離好像是沒有用的
- 文中配置使用的是HikariCP連線池,使用其他連線池時,需要將jdbc-url配置名該為url,否則可能會拋異常