
mycat分表分庫的原理是什麼
當初寫這篇文章的初衷只是想提醒自己在用一個開源產品前不僅要了解其提供的功能,更要了解其功能和場景邊界。
1.非分片欄位查詢
Mycat中的路由結果是通過分片欄位和分片方法來確定的。例如下圖中的一個Mycat分庫方案:
- 根據 tt_waybill 表的 id 欄位來進行分片
- 分片方法為 id 值取 3 的模,根據模值確定在DB1,DB2,DB3中的某個分片
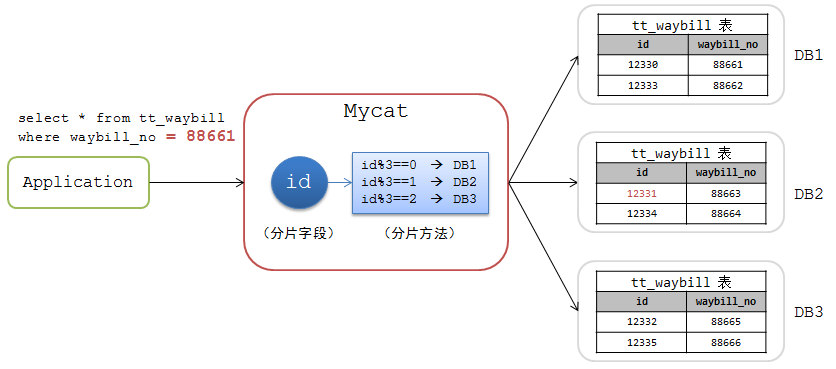
如果查詢條件中有 id 欄位的情況還好,查詢將會落到某個具體的分片。例如:
mysql>select * from tt_waybill where id = 12330;
此時Mycat會計算路由結果
12330 % 3 = 0 –> DB1
並將該請求路由到DB1上去執行。
如果查詢條件中沒有 分片欄位
mysql>select * from tt_waybill where waybill_no =88661;
此時Mycat無法計算路由,便傳送到所有節點上執行:
DB1 –> select * from tt_waybill where waybill_no =88661;
DB2 –> select * from tt_waybill where waybill_no =88661;
DB3 –> select * from tt_waybill where waybill_no =88661;
如果該分片欄位選擇度高,也是業務常用的查詢維度,一般只有一個或極少數個DB節點命中(返回結果集)。示例中只有3個DB節點,而實際應用中的DB節點數遠超過這個,假如有50個,那麼前端的一個查詢,落到MySQL資料庫上則變成50個查詢,會極大消耗Mycat和MySQL資料庫資源。
如果設計使用Mycat時有非分片欄位查詢,請考慮放棄!
2.分頁排序
先看一下Mycat是如何處理分頁操作的,假如有如下Mycat分庫方案:
一張表有30份資料分佈在3個分片DB上,具體資料分佈如下
DB1:[0,1,2,3,4,10,11,12,13,14]
DB2:[5,6,7,8,9,16,17,18,19]
DB3:[20,21,22,23,24,25,26,27,28,29]
(這個示例的場景中沒有查詢條件,所以都是全分片查詢,也就沒有假定該表的分片欄位和分片方法)
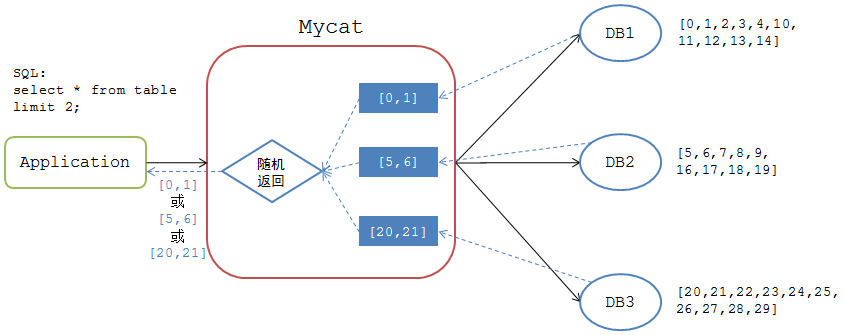
當應用執行如下分頁查詢時
mysql>select * from table limit 2;
Mycat將該SQL請求分發到各個DB節點去執行,並接收各個DB節點的返回結果
DB1: [0,1]
DB2: [5,6]
DB3: [20,21]
但Mycat嚮應用返回的結果集取決於哪個DB節點最先返回結果給Mycat。如果Mycat最先收到DB1節點的結果集,那麼Mycat返回給應用端的結果集為 [0,1],如果Mycat最先收到DB2節點的結果集,那麼返回給應用端的結果集為 [5,6]。也就是說,相同情況下,同一個SQL,在Mycat上執行時會有不同的返回結果。
在Mycat中執行分頁操作時必須顯示加上排序條件才能保證結果的正確性,下面看一下Mycat對排序分頁的處理邏輯。
假如在前面的分頁查詢中加上了排序條件(假如表資料的列名為id)
mysql>select * from table order by id limit 2;
Mycat的處理邏輯如下圖:
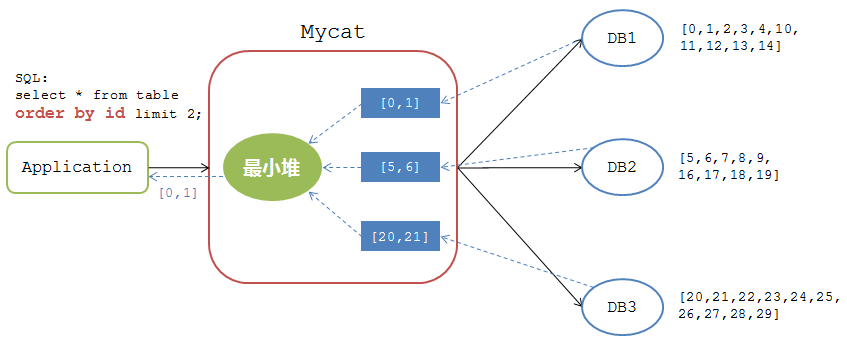
在有排序呢條件的情況下,Mycat接收到各個DB節點的返回結果後,對其進行最小堆運算,計算出所有結果集中最小的兩條記錄 [0,1] 返回給應用。
但是,當排序分頁中有 偏移量 (offset)時,處理邏輯又有不同。假如應用的查詢SQL如下:
mysql>select * from table order by id limit 5,2;
如果按照上述排序分頁邏輯來處理,那麼處理結果如下圖:
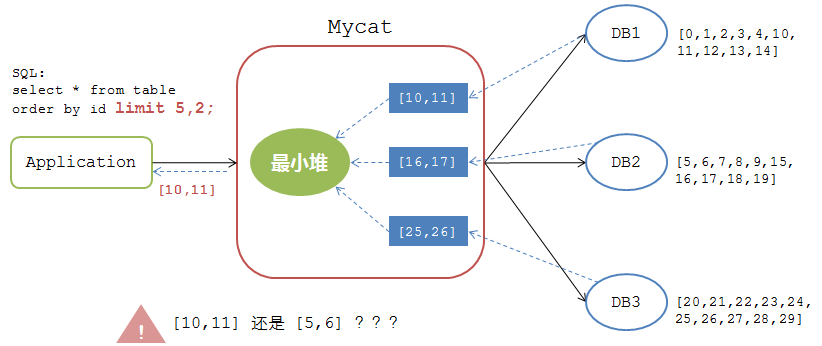
Mycat將各個DB節點返回的資料 [10,11], [16,17], [20,21] 經過最小堆計算後返回給應用的結果集是 [10,11]。可是,對於應用而言,該表的所有資料明明是 0-29 這30個數據的集合,limit 5,2 操作返回的結果集應該是 [5,6],如果返回 [10,11] 則是錯誤的處理邏輯。
所以Mycat在處理 有偏移量的排序分頁 時是另外一套邏輯——改寫SQL 。如下圖:
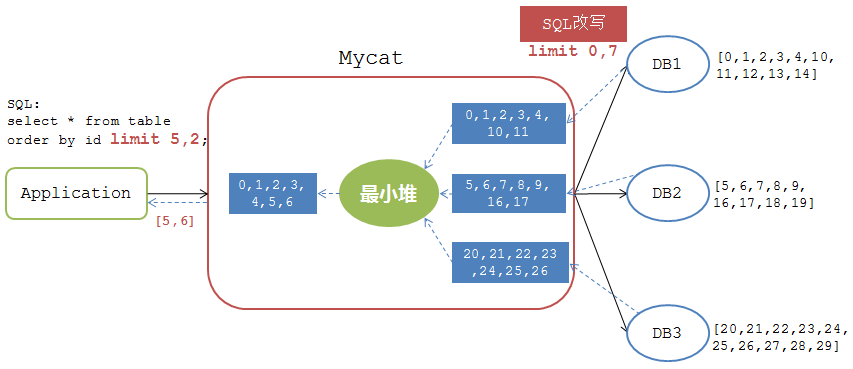
Mycat在下發有 limit m,n 的SQL語句時會對其進行改寫,改寫成 limit 0, m+n 來保證查詢結果的邏輯正確性。所以,Mycat傳送到後端DB上的SQL語句是
mysql>select * from table order by id limit 0,7;
各個DB返回給Mycat的結果集是
DB1: [0,1,2,3,4,10,11]
DB2: [5,6,7,8,9,16,17]
DB3: [20,21,22,23,24,25,26]
經過最小堆計算後得到最小序列 [0,1,2,3,4,5,6] ,然後返回偏移量為5的兩個結果為 [5,6] 。
雖然Mycat返回了正確的結果,但是仔細推敲發現這類操作的處理邏輯是及其消耗(浪費)資源的。應用需要的結果集為2條,Mycat中需要處理的結果數為21條。也就是說,對於有 t 個DB節點的全分片 limit m, n 操作,Mycat需要處理的資料量為 (m+n)*t 個。比如實際應用中有50個DB節點,要執行limit 1000,10操作,則Mycat處理的資料量為 50500 條,返回結果集為10,當偏移量更大時,記憶體和CPU資源的消耗則是數十倍增加。
如果設計使用Mycat時有分頁排序,請考慮放棄!
3.任意表JOIN
先看一下在單庫中JOIN中的場景。假設在某單庫中有 player 和 team 兩張表,player 表中的 team_id 欄位與 team 表中的 id 欄位相關聯。操作場景如下圖:
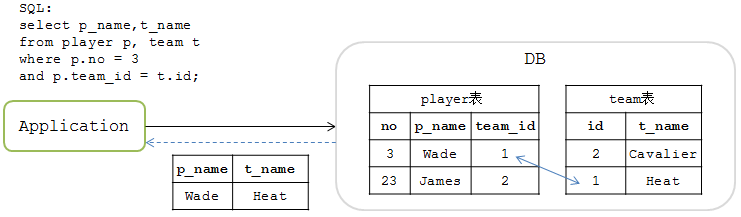
JOIN操作的SQL如下
mysql>select p_name,t_name from player p, team t where p.no = 3 and p.team_id = t.id;
此時能查詢出結果
| p_name | t_name |
|---|---|
| Wade | Heat |
如果將這兩個表的資料分庫後,相關聯的資料可能分佈在不同的DB節點上,如下圖:
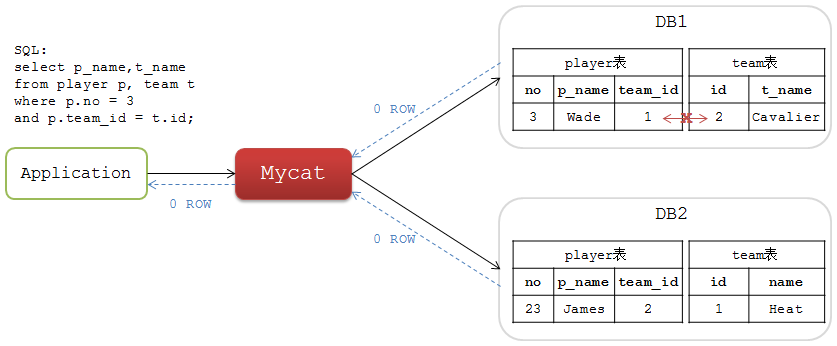
這個SQL在各個單獨的分片DB中都查不出結果,也就是說Mycat不能查詢出正確的結果集。
設計使用Mycat時如果要進行表JOIN操作,要確保兩個表的關聯欄位具有相同的資料分佈,否則請考慮放棄!
4.分散式事務
Mycat並沒有根據二階段提交協議實現 XA事務,而是隻保證 prepare 階段資料一致性的 弱XA事務 ,實現過程如下:
應用開啟事務後Mycat標識該連線為非自動提交,比如前端執行
mysql>begin;
Mycat不會立即把命令傳送到DB節點上,等後續下發SQL時,Mycat從連線池獲取非自動提交的連線去執行。
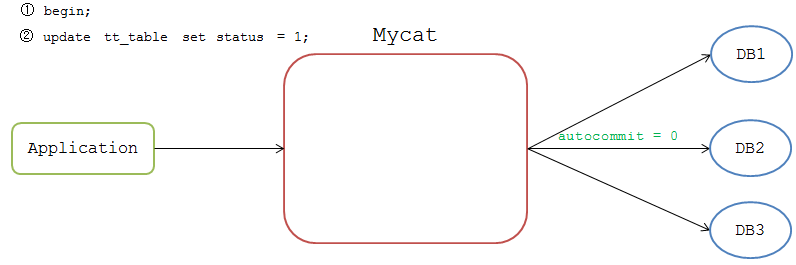
Mycat會等待各個節點的返回結果,如果都執行成功,Mycat給該連線標識為 Prepare Ready 狀態,如果有一個節點執行失敗,則標識為 Rollback 狀態。
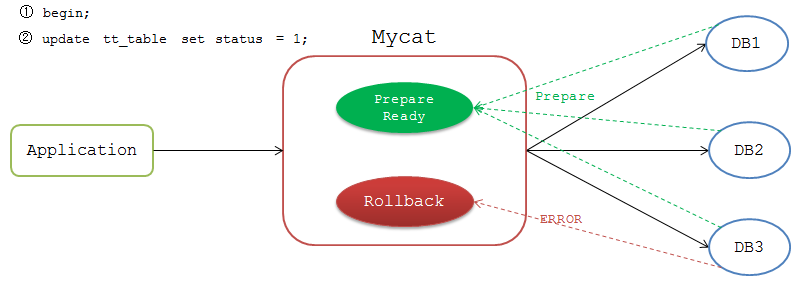
執行完成後Mycat等待前端傳送 commit 或 rollback 命令。傳送 commit 命令時,Mycat檢測當前連線是否為 Prepare Ready 狀態,若是,則將 commit 命令傳送到各個DB節點。
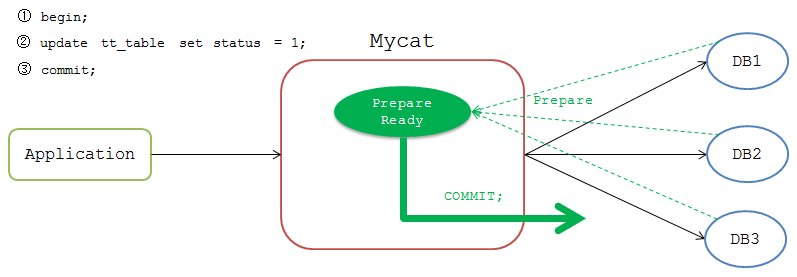
但是,這一階段是無法保證一致性的,如果一個DB節點在 commit 時故障,而其他DB節點 commit 成功,Mycat會一直等待故障DB節點返回結果。Mycat只有收到所有DB節點的成功執行結果才會向前端返回 執行成功 的包,此時Mycat只能一直 waiting 直至TIMEOUT,導致事務一致性被破壞。
設計使用Mycat時如果有分散式事務,得先看是否得保證事務得強一致性,否則請考慮放棄!