
大資料叢集搭建基本配置說明
大資料發展愈演愈烈,為了快速跟上技術發展的步伐,最近在學習大資料的相關技術,當然第一步,還是要學習大資料叢集的搭建,將自己的一些小經驗分享給大家,希望對你們有幫助,當然也感謝在我學習的過程,提供資料和幫助的科多大資料的餘老師,話不多說,先上圖
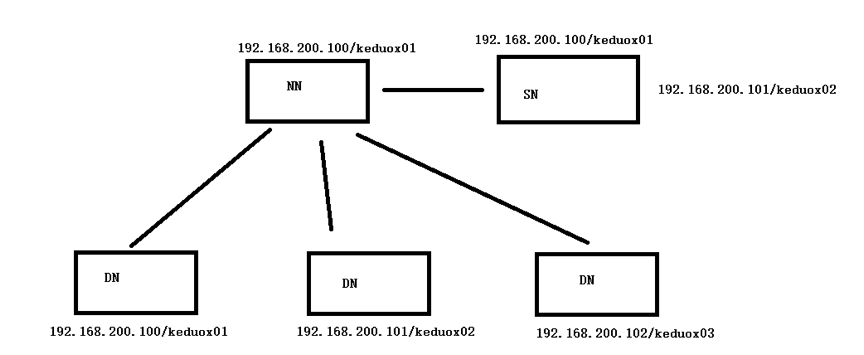
偽分佈:只有一臺主要用搭建偽分散式
準備三臺,用於叢集搭建
快照
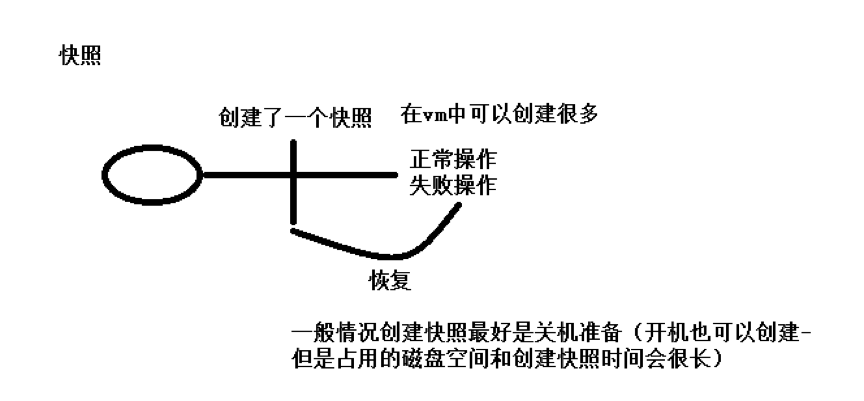
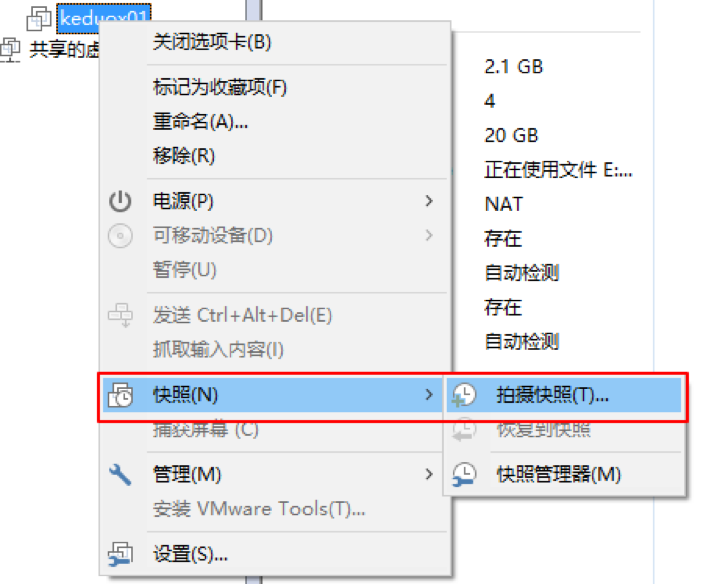
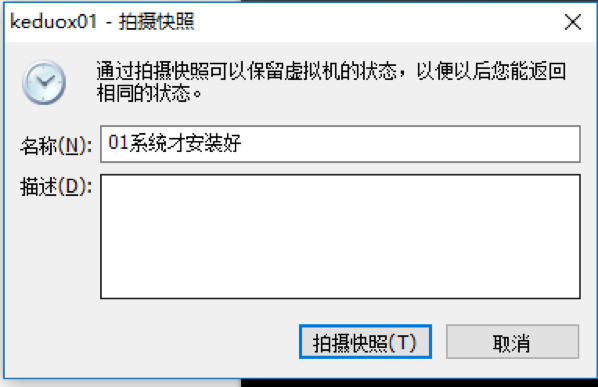
克隆
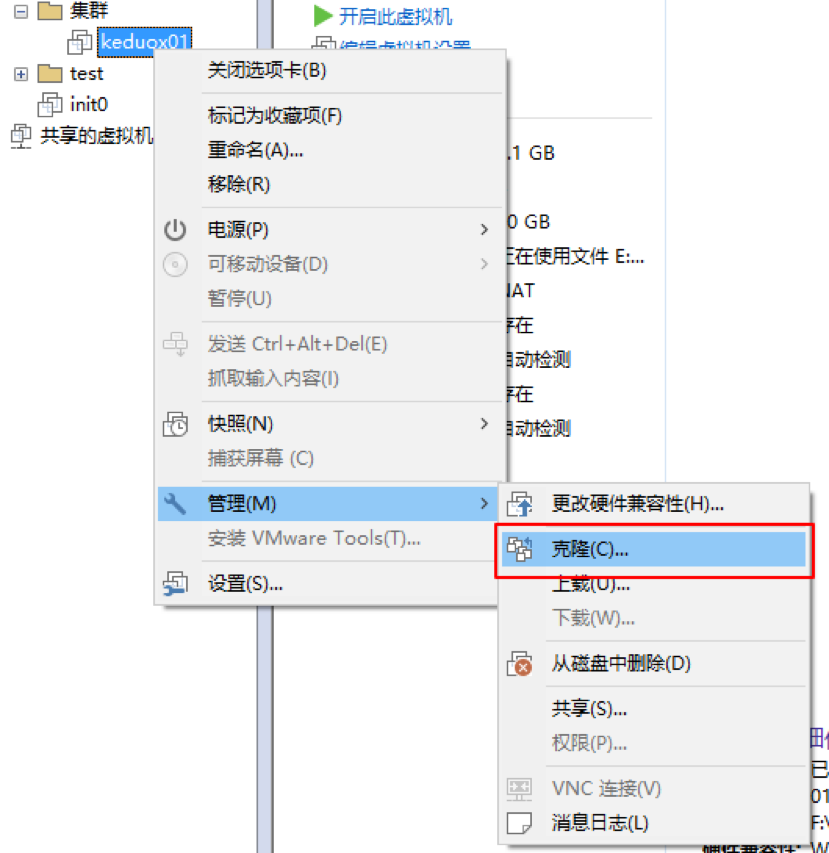
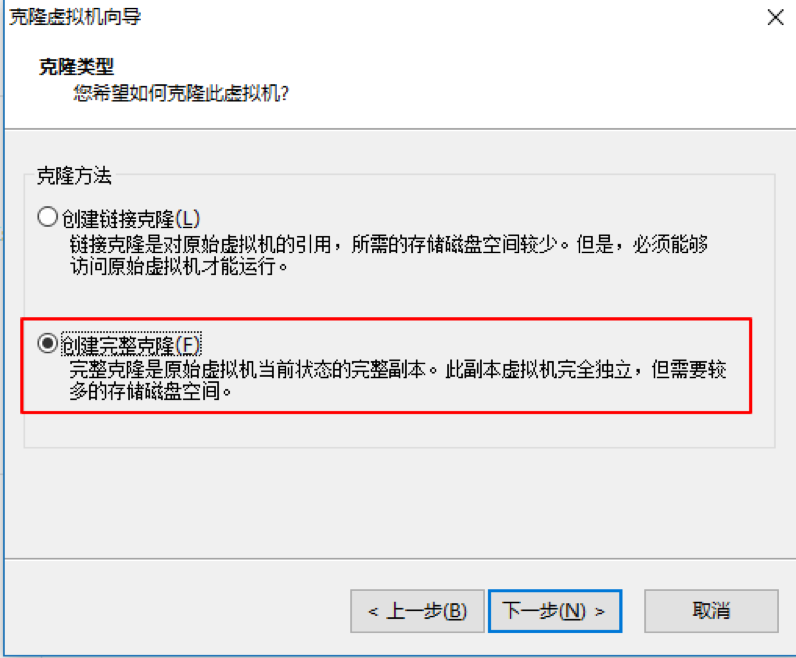
克隆出來的主機,它們的主機名、ip、MAC地址都是一樣的。所以要進行一些基本配置。修改主機名、ip、mac地址(vm中進行修改)
mac地址
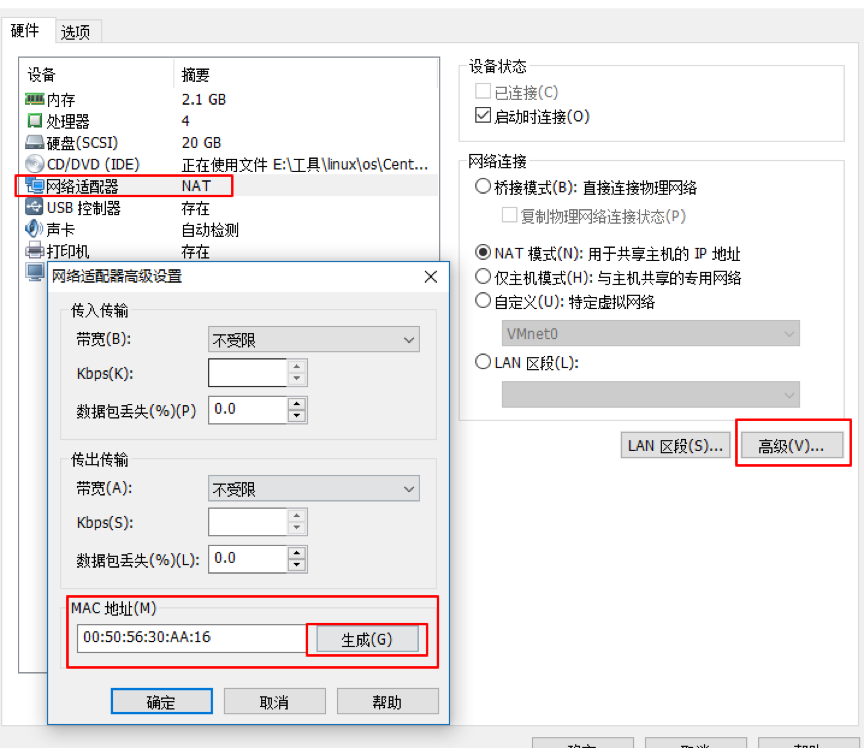
修改主機名和IP地址
主機名:hostnamectlset-hostname keduox01
修改ip地址:
進入到

檔案中修改

讓網絡卡重啟:cd/etc/init.d
./network restart
100要和自已做免密
100需要將自己的公鑰傳送到101上
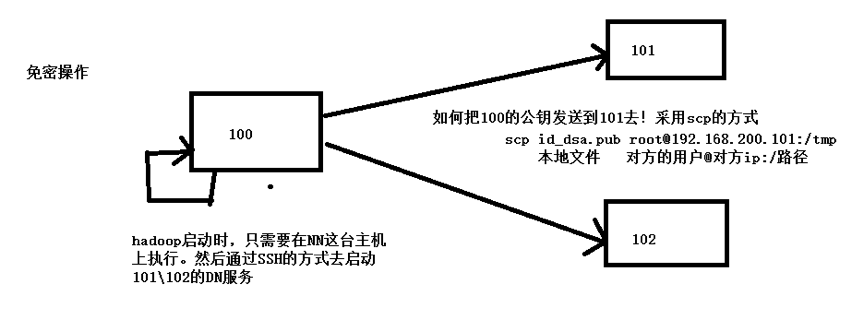
101拿到公鑰之後,需要建立.ssh目錄,所以在101上需要執行一次生成免密的檔案
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在將傳送過的公鑰加入直接的檔案中
cat /tmp/id_dsa.pub >> ~/.ssh/authorized_keys
第二種方法:ssh-copy-id -i 192.168.200.102
讓三臺主機可以通過主機名可以互相訪問
在/etc/hosts目錄下,將ip與主機名進行關聯配置,第一個關聯是一行。
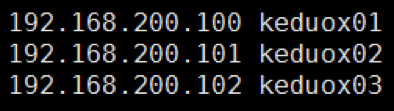
可以一臺一臺的配置,建議使用scp的方式,將/etc/hosts的內容傳送到其它2臺主機
scp /etc/hosts [email protected]:/etc/hosts
相關推薦
大資料叢集搭建基本配置說明
大資料發展愈演愈烈,為了快速跟上技術發展的步伐,最近在學習大資料的相關技術,當然第一步,還是要學習大資料叢集的搭建,將自己的一些小經驗分享給大家,希望對你們有幫助,當然也感謝在我學習的過程,提供資料和幫助的科多大資料的餘老師,話不多說,先上圖偽分佈:只有一臺主要用搭建偽分散式
大資料叢集搭建伺服器配置
剛接觸大資料的時候,首先是想辦法搭叢集,而是在伺服器配置上,總會出現很多問題,今天我將我將我在科多大資料配置伺服器的經驗分享給大家,希望對你們有幫助1、準備四臺主機ip地址 主機名192.168.200.151 kd01 2G192.168.200.152 kd
大資料叢集搭建之節點的網路配置過程(二)
緊接著上一章來設定windows的vmnet8的ip地址和虛擬機器中centos的ip地址。 NAT虛擬網路的配置圖如下圖所示: 1、這裡根據VMware中得到的閘道器地址去設定vmnet8的ip地址。 閘道器地址檢視: 2、得到的閘道器地址後去
大資料叢集搭建和使用之八——kafka配置和使用
這個系列指南使用真實叢集搭建環境,不是偽叢集,用了三臺騰訊雲伺服器 或者訪問我的個人部落格站點,連結 Kafka 配置 kafka依賴zookeeper,所以先確保叢集已經安裝zookeeper並且能夠正常啟動。 浪費了一整天的時間deb
雲端計算與大資料 叢集搭建 學習筆記
雲集群的搭建 一、虛擬機器設定: 1.開啟ESXI虛擬機器;(本人所用) 2.網路設定為橋接模式 3.按F2設定系統,輸入密碼 4.Restart Manangement Network 5.esc 退出 加硬碟: 1.開啟虛擬機器給出的ip地址,檢視VWware ES
大資料叢集搭建之環境準備(虛擬機器)
以虛擬機器環境測試的 物理機不一定適用 系統是Centos7的 1、配置靜態ip vim /etc/sysconfig/network-scripts/ifcfg-ens33 ONBOOT=yes BOOTPROTO=static IPADDR=192.168.
我的Hadoop大資料叢集搭建經歷 (Hadoop 2.6.0 & VMWare WorkStation 11)
centos 6.6 i386 dvd ; basic server installation ; not enable static ip ; not disable ipv6 vmware net model is NAT , subNet Ip : 192.168.5
大資料環境搭建------基礎環境配置
準備材料: 作業系統:Centos7(最好有網路) 軟體:JDK:jdk-8u171-linux-x64.tar.gz(最好使用JDK1.8以上) 在虛擬機器中搭建三個linux系統,分別代表三個節點 {主節點:master 從節點:slave1、slave2} 此次操作均在root使
CentOS5/6/7系統下搭建安裝Amabari大資料叢集時出現SSLError: Failed to connect. Please check openssl library versions.錯誤的解決辦法(圖文詳解)
不多說,直接上乾貨! ========================== Creating target directory... ======================
網路配置、防火牆 (大資料叢集環境)Linux防火牆
網路配置、防火牆 1.大資料叢集環境,形成叢集區域網,使用機器名替代真實IP,如何完成IP地址與機器名的對映? 1)修改機器名 在CenterOS7,使用hostname命令,修改當前機器名,如果重啟節點機器名失效;修改/etc/hostname配置檔案(內容:自定義機器名 例:p
大資料叢集架之——nginx 反向代理的安裝配置文件。
二、Nginx安裝配置 1.安裝gcc 方式1 - yum線上安裝: //yum install gcc
HA機制的大資料叢集的搭建過程
叢集規劃 說明: 1、在hadoop2.0中通常由兩個NameNode組成,一個處於active狀態,另一個處於standby狀態。Active NameNode對外提供服務,而Standby NameNode則不對外提供服務,僅同步active nameno
大資料的一些基本指令與基本配置
**一:git 命令** pwd 檢視當前所在檔案路徑 ls 檢視資料夾下檔案 mkdir 建立資料夾 touch 建立檔案 git s
D001.5 Docker搭建大資料叢集環境(基礎篇)
0x00 教程內容 0x01 Docker的安裝 1. 2. 3. 0x02 Docker的簡單操作 1. 2. 3. 0x03 Docker資料卷 Docker的資料卷與Centos的
從零開始的Hadoop大資料叢集(偽)搭建,全免費VirtualBox虛擬機器Ubuntu版,學習向,超詳細---(一)
在公司工作了一段時間了,大資料平臺都是公司的運維人員搭建維護的,自己也想親自搭建一套,純粹為了學習和提高自己,也為了以後自己研究用。公司的環境不太適合亂來,自己的就可以隨意玩了。 寫這個也是為了記錄自己學習的過程,同時給大家提供一個參考,想要學習大資料的也
Linux下基於Hadoop的大資料環境搭建步驟詳解(Hadoop,Hive,Zookeeper,Kafka,Flume,Hbase,Spark等安裝與配置)
Linux下基於Hadoop的大資料環境搭建步驟詳解(Hadoop,Hive,Zookeeper,Kafka,Flume,Hbase,Spark等安裝與配置) 系統說明 搭建步驟詳述 一、節點基礎配置 二、H
大資料叢集環境下的常用linux基礎配置
叢集環境下常用Linux基礎配置 1. 本地yum源配置 Yum全稱是Yellow dog Updater,Modified,是一個在Fedora和Redhat以及CentOS中的Shell前端軟體包管理器。基於RPM包管理,能夠從指定的伺服器自動下載RPM包並安裝,可以自動處理依賴性關
大資料_Kafka_搭建Kafka偽叢集(本地叢集)
這裡假設大家已經裝好了Kafka的環境,並對kafka的知識有基本的瞭解。 下面直接講解如何搭建一個本地的偽叢集:(裡面用到了zookeeper 偽叢集 ) 叢集配置: Step1 將配置檔案拷貝多份 cp config/server.properties co
大資料叢集的配置
為什麼要用Ambari Ambari 是 Apache Software Foundation 中的一個頂級專案。就 Ambari 的作用來說,就是建立、管理、監視 Hadoop 的整個生態圈產品(例如 Hive,Hbase,Sqoop,Zookeeper 等)。用一句話來說,Ambar
Ubuntu14.04下Ambari安裝搭建部署大資料叢集(圖文分五大步詳解)(博主強烈推薦)
不多說,直接上乾貨! 寫在前面的話 (1) 最近一段時間,因擔任我團隊實驗室的大資料環境叢集真實物理機器工作,至此,本人秉持負責、認真和細心的態度,先分別在虛擬機器上模擬搭建ambari(基於CentOS6.5版本)和cloudermanager(基於CentOS6.5或Ub