
kettle6.0原始碼編譯方法
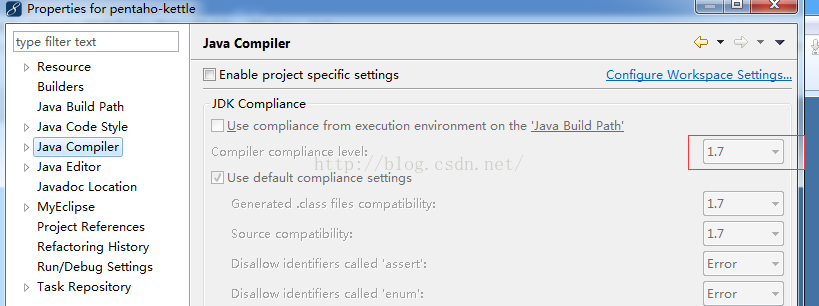
5.在myEclipse中shift+ctrl+r,找到Spoon.java,然後執行即可 6.如果在執行中報如下錯誤:
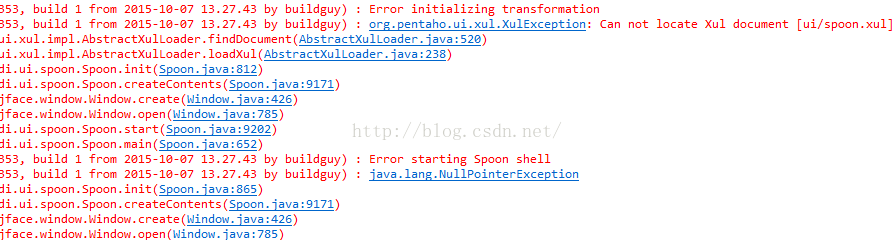
此時需要把工具中的ui資料夾拷貝過來,因為缺少spoon的執行介面
相關推薦
kettle6.0原始碼編譯方法
首先: 1.重新建立一個java project,然後把官方ui資料夾下的src裡面的原始碼拷貝到工程的src原始檔中(不拷貝src資料夾,否則報錯) 2.在工具中把lib和libswt資料夾拷貝過來 3.在工程build-path,把lib下所有的jar包匯入,然後匯
hadoop原始碼編譯方法,以及編譯問題總結
一、編譯所需的一些軟體 1.jdk1.7 2.maven 3.3.9 3.findbugs 3.0.1 4.protocolBuffer 2.5.0 5.cmake 2.6 6.zlib-devel 7.openssl-devel 8.gcc-c++ 9.autoco
kettle8.0原始碼編譯
kettle8.0原始碼編譯 kettle作為一款開源etl工具,在資料倉庫領域的應用還算是比較廣泛的,做過數倉的朋友應該都知道,在做etl開發的時候,對於引數變數的引用是時常出現的場景,對於一些公共的變數,kettle的做法是啟動的時候預設讀取使用者目錄下一個kettle.
CDH版hadoop2.6.0-cdh5.7.0原始碼編譯
前置要求 hadoop2.6.0-cdh5.7.0 原始碼包 下載 jdk 1.7+ 下載 maven 3.0+ 下載 protobuf 2.5+ 下載 安裝依賴庫 $>yum install -y svn ncurses-devel gcc
Spark Streaming實時流處理筆記(1)——Spark-2.2.0原始碼編譯
1 下載原始碼 https://spark.apache.org/downloads.html 解壓 2 編譯原始碼 參考 https://www.imooc.com/article/18419 https://spark.apache.org/docs/2.2.2/bu
Mac Android8.0原始碼編譯筆記
原因:記憶體不夠辦法:新增限制,輸入如下命令:export JACK_SERVER_VM_ARGUMENTS="-Dfile.encoding=UTF-8 -XX:+TieredCompilation -Xmx4g"./prebuilts/sdk/tools/jack-admin kill-server./p
TensorFlow-1.11.0 原始碼編譯&C++ API使用
『寫在前面』 關於tf,一種常見的使用方式是:線上下使用TensorFlow的Python Binding搭建和訓練模型,然後利用freeze_graph工具等工具輸出*.pb檔案(或使用tf.train.Saver儲存成*.meta檔案和checkpoint
ffmpeg4.0.2編譯方法
cd /opt/install/ffmpeg tar -xvf ffmpeg-4.0.2.tar.bz2 cd ffmpeg-4.0.2 export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH export LD_LIBRARY_
elasticsearch6.0原始碼編譯
Mac 筆記本 IntelliJ Idea,JDK1.8,gradle3.5,elasticsearch-6.0.0-rc2的發行版 gradle配置國內映象源, ~/.gradle 目錄下放置 init.gradle檔案,檔案內容如下: allprojects{ repos
spark2.4 整合 hadoop2.6.0-cdh5.7.0 原始碼編譯
1.前置要求 java 8 + maven 3.5.4 + scala 2.11 2.下載 spark2.4 原始碼包 在spark官網 下載頁面中選擇對應的spark版本和原始碼包 [[email protected] softwore
spark2.2.0 原始碼編譯安裝
1. Spark概述 Spark 是一個用來實現快速而通用的叢集計算的平臺。 在速度方面,Spark 擴充套件了廣泛使用的 MapReduce 計算模型,而且高效地支援更多計算模式,包括互動式查詢和流處理。 在處理大規模資料集時,速度是非常重要的。速度快就意
Spark-2.2.0原始碼編譯報錯
[INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] -----------------------------------------------
petaho kettle 8.1.0.0原始碼編譯過程
1 到github上去下載原始碼 https://github.com/pentaho/pentaho-kettle/tree/8.1.0.0 2 下載並配置maven的設定按照管網的指導 3 配置maven的環境變數 (這裡可以在網上百度一下) 4 配置 mav
Android7.0原始碼編譯執行指南
編譯環境:Ubuntu 16.04 映象檔案:清華大學AOSP映象 Android7.0 一、原始碼下載 1 映象地址 清華大學AOSP(Android Open Source Project) https://mirrors.tun
OpenCV安裝流程及從原始碼編譯方法 + 配置VS
本篇文章記錄了安裝OpenCV 3.4.2及配置VS2017的方法,以及利用CMake從原始碼編譯適用於老版本VS2013的OpenCV 3.4.2的編譯及配置流程。本文也可以作為其他OpenCV及VS版本安裝配置方法的參考。 1 安裝OpenCV 3.4.2
QT210 Android4.0原始碼編譯和燒錄文件整理
開發環境說明:Ubuntu 12.04 LTS 32bit原始碼檔案目錄:編譯過程說明:編譯uboot (qt210_ics_uboot.bz2)交叉編譯環境:tar jxf arm-2009q3-67-arm-none-linux-gnueabi-i686-pc-linux-gnu.tar.bz2 -C /
hadoop-2.4.0原始碼編譯過程
系統為ubuntu14.04,32bit,以前一直用官網包(官網為32bit),這次試著自己編譯了一次,大致如下: 1.下載hadoop-2.4.0-src.tar.gz原始碼包 下載完成解壓,得到hadoop原始碼資料夾:hadoop-2.4.0-src 2.安裝編譯
Android 5.0原始碼編譯問題
如果是自己通過repo和git直接從google官網上download的原始碼,請忽略這個問題,但是由於google在國內被限制登入,通過這一種方法不是每個人都能download下來原始碼,通常的做法就是從別人那拷貝,然後自己編譯,那麼通常會出現下面的錯誤: No rule to make target '
Android 7.0 原始碼編譯
一步步都是按照官網的要求做的,ubuntu的版本是16.04LTS 64bit make -j4 " ============================================ PLATFORM_VERSION_CODENAME=REL PLATFORM_V
flume1.6.0原始碼編譯
1.下載flume原始碼 http://mirrors.hust.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-src.tar.gz 2.解壓到本地 3.註釋掉hbase和hadoo的測試程式碼(如果在編譯過程中不報錯可以不註釋)