
十分鐘快速上手結巴分詞
一.特點
1、支援三種分詞模式
精確模式,試圖將句子最精確的切開;
全模式,把句子中所有的可以成詞的詞語都掃描出來,速度非常快,但是不能解決歧義;
搜尋引擎模式,在精確模式的基礎上,對長詞再次切分,提高召回率,適合用於搜尋引擎分詞。
2、支援繁體分詞
3、支援自定義詞典
4、MIT授權協議
二.安裝說明
程式碼對Python 2/3 均相容
- 全自動安裝:easy_install jieba 或者 pip install jieba / pip3 install jieba
- 手動安裝:將jieba目錄放置於當前目錄或者site-packages目錄
- 通過import jieba 來引用
三.演算法
- 基於字首詞典實現高效的詞圖掃描,生成了句子中漢字所有可能成詞情況所構成的有向無環圖(DAG)
- 採用了動態規劃查詢最大路徑概率,找出基於詞頻的最大切分組合
- 對於未登入詞,採用了基於漢字成詞能力的HMM模型,使用了Viterbi演算法
四.主要功能
1.分詞
- jieba.cut方法接受三個輸入引數:需要分詞的字串;cut_all引數用來控制是否採用全模式;HMM引數用來控制是否使用HMM模型
- jieba.cut_for_search方法接受兩個引數:需要分詞的字串;是否使用HMM模型。該方法適用於搜尋引擎構建倒排索引的分詞,粒度比較細
- 待分詞的字串可以是unicode或UTF-8字串、GBK字串
- jieba.cut以及jieba.cut_for_search返回的結構都是一個可迭代的generator,可以使用for迴圈來獲得分詞後得到的每一個詞語(Unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回list
- jieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定義分詞器,可用於同時使用不同詞典。jieba.dt為預設分詞器,所有全域性分詞相關函式都是該分詞器的對映
相關函式原型:
def cut(self, sentence, cut_all=False, HMM=True): ''' The main function that segments an entire sentence that contains Chinese characters into seperated words. Parameter: - sentence: The str(unicode) to be segmented. - cut_all: Model type. True for full pattern, False for accurate pattern. - HMM: Whether to use the Hidden Markov Model. ''' def cut_for_search(self, sentence, HMM=True): """ Finer segmentation for search engines. """ def lcut(self, *args, **kwargs): return list(self.cut(*args, **kwargs)) def lcut_for_search(self, *args, **kwargs): return list(self.cut_for_search(*args, **kwargs))
程式碼示例:
#_*_coding:utf-8_*_
import jieba
if __name__ == '__main__':
seg_list = jieba.cut("我來到北京清華大學", cut_all=True) #全模式
print("Full Mode:" + "/".join(seg_list))
seg_list = jieba.cut("我來到北京清華大學", cut_all=False) #精確模式
print("Default Mode:" + "/".join(seg_list))
seg_list = jieba.cut("他來到了網易杭研大廈", HMM=False) #不使用HMM模型
print("/".join(seg_list))
seg_list = jieba.cut("他來到了網易杭研大廈", HMM=True) #使用HMM模型
print("/".join(seg_list))
seg_list = jieba.cut_for_search("小明碩士畢業於中國科學院計算所,後在日本京都大學深造", HMM=False) #搜尋引擎模式
print("/".join(seg_list))
seg_list = jieba.lcut_for_search("小明碩士畢業於中國科學院計算所,後在日本京都大學深造", HMM=True)
print(seg_list)執行結果:

2.新增自定義詞典
載入詞典:
- 開發者可以指定自己定義的詞典,以便包含jieba詞庫裡沒有的詞。雖然jieba有新詞識別能力,但是自行新增新詞可以保證更高的正確率。
- 用法:jieba.load_userdict(file_name) file_name為檔案類物件或自定義詞典的路徑
- 詞典格式和dict.txt一樣,一個詞佔一行;每一行分三個部分:詞語、詞頻(可省略)、詞性(可省略),用空格隔開,順序不可顛倒。file_name若為路徑或二進位制方式開啟的檔案,則檔案必須為UTF-8編碼。
- 詞頻省略時使用自動計算的能保證分出該次的詞頻。
例子:
import jieba
if __name__ == '__main__':
test_sent = (
"李小福是創新辦主任也是雲端計算方面的專家; 什麼是八一雙鹿\n"
"例如我輸入一個帶“韓玉賞鑑”的標題,在自定義詞庫中也增加了此詞為N類\n"
"「臺中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent) #在使用自定義詞典或新增詞條前的切割測試
print("/".join(words))
jieba.load_userdict("userdict.txt") #載入使用者自定義詞典
print("=" * 100)
words = jieba.cut(test_sent) #使用者自定義詞典中出現的詞條被正確劃分
print("/".join(words))
jieba.add_word("石墨烯") #新增詞條石墨烯和凱特琳
jieba.add_word("凱特琳")
jieba.del_word("自定義詞") #刪除詞條自定義詞
print("=" * 100)
words = jieba.cut(test_sent) #再次進行測試
print("/".join(words))更改分詞器(預設為jieba.dt)的tem_dir和catch_file屬性,可分別指定快取檔案所在的資料夾以及檔名,用於受限的檔案系統。
調整詞典:
- 使用add_word(word, freq = None, tag = None)和del_word(word)可在程式中動態修改詞典。(在前面的程式例項中已經講到)
- 使用suggest_freq(segment, tune = True)可調節單個詞語的詞頻,使其能(或不能)被分出來
- 注意:自動計算的詞頻在使用HMM新詞發現功能時可能無效。
程式碼例項:
import jieba
if __name__ == '__main__':
print("/".join(jieba.cut("如果放到post中將出錯。", HMM=False)))
jieba.suggest_freq(("中", "將"), True) #可以print檢視
print("/".join(jieba.cut("如果放到post中將出錯。", HMM=False)))
print("/".join(jieba.cut("臺中正確應該不會被切開", HMM=False)))
jieba.suggest_freq("臺中", True)
print("/".join(jieba.cut("臺中正確應該不會被切開", HMM=False)))3.關鍵詞提取
基於TF-IDF演算法的關鍵詞提取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK = 20,withWeight = False, allowPOS = ())
- sentence為待提取文字
- topK為返回幾個TF-IDF權重最大的關鍵詞,預設值為20
- withWeight為是否一併返回關鍵詞權重值,預設值為FALSE
- allowPOS僅包括指定詞性的詞,預設值為空,即不篩選
jieba.analyse.TFIDF(idf_path = None)新建TFIDF例項,idf_path為IDF頻率檔案
程式碼例項(關鍵詞提取):
import jieba
import jieba.analyse
file_name = "testfile"
content = open(file_name, "r").read()
tags = jieba.analyse.extract_tags(content, topK=10)
print("/".join(tags))關鍵詞提取所使用逆向檔案頻率(IDF)文字語料庫可以切換成自定義語料庫的路徑
用法示例:
import jieba
import jieba.analyse
file_name = "testfile"
content = open(file_name, "r").read()
jieba.analyse.set_idf_path("path")
tags = jieba.analyse.extract_tags(content, topK=10)
print("/".join(tags))關鍵詞提取所使用的停用詞文字語料庫可以切換成自定義語料庫的路徑
用法示例:
import jieba
import jieba.analyse
file_name = "testfile"
content = open(file_name, "r").read()
jieba.analyse.set_idf_path("path")
jieba.analyse.set_idf_path("path")
tags = jieba.analyse.extract_tags(content, topK=10)
print("/".join(tags))關鍵詞一併返回關鍵詞權重示例:
import jieba
import jieba.analyse
file_name = "testfile"
content = open(file_name, "r").read()
jieba.analyse.set_idf_path("path")
jieba.analyse.set_idf_path("path")
tags = jieba.analyse.extract_tags(content, topK=10, withWeight=True)
for tag in tags:
print("tag:%s\t\t weight:%f" % (tag[0], tag[1]))基於TextRank演算法的關鍵詞抽取
- jieba.analyse.textrank(sentence, topK = 20, withWeight = False, allowPOS = ('ns', 'n', 'vn', 'v'))直接使用,介面相同,注意預設過濾詞性
- jieba.analyse.TextRank()新建自定義TextRank示例
基本思想:
- 將待抽取關鍵詞的文字進行分詞
- 以固定視窗大小(預設為5,通過span屬性調整),詞之間的共現關係,構建圖
- 計算圖中節點的pagerank,注意是無向帶權圖
使用示例:
import jieba
import jieba.analyse
import jieba.posseg
s = "此外,公司擬對全資子公司吉林歐亞置業有限公司增資4.3億元,增資後,吉林歐亞置業註冊資本由7000萬元增加到5億元。吉林歐亞置業主要經營範圍為房地產開發及百貨零售等業務。目前在建吉林歐亞城市商業綜合體專案。2013年,實現營業收入0萬元,實現淨利潤-139.13萬元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print("%s %s" % (x, w))4.詞性標註
jieba.posseg.POSTokenizer(tokenizer = None)新建自定義分詞器,tokenizer引數可指定內部使用的jieba.Tokenizer。標註句子分詞後每個詞的詞性,採用和ictclas相容的標記法。
用法示例:
import jieba.posseg as pseg
words = pseg.cut("我愛北京天安門")
for word, flag in words:
print("%s %s" % (word, flag))5.Tokenize:返回詞語在原文的起止位置
注意,輸入引數只接受Unicode
預設模式:
import jieba
result = jieba.tokenize("永和服裝飾品有限公司")
for tk in result:
print("word %s\t\t start:%d\t\t end:%d" % (tk[0],tk[1],tk[2]))搜尋模式:
import jieba
result = jieba.tokenize("永和服裝飾品有限公司",mode="search")
for tk in result:
print("word %s\t\t start:%d\t\t end:%d" % (tk[0],tk[1],tk[2]))6.命令列分詞
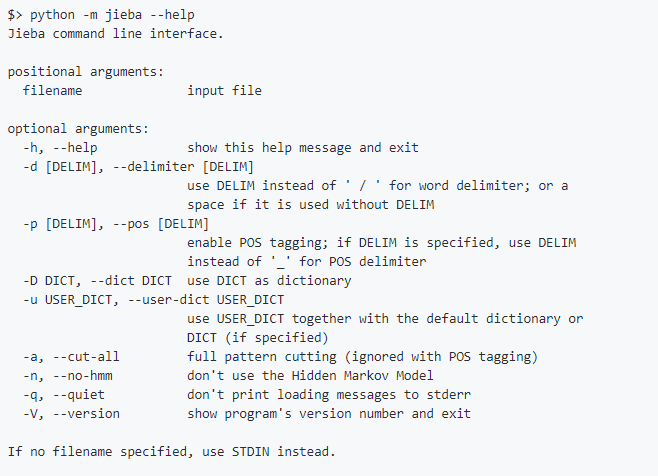
使用示例:Python -m jieba news.txt > cut_result.txt
命令列選項:

--help選項輸出:
以上就是雞巴分詞...呸,結巴分詞的基本用法,關於並行分詞和延遲載入機制請檢視官方文件。
博主只是學生黨一枚,為了做問答系統瞭解了一下結巴分詞,有什麼不對的地方還請指出。