Celery 框架學習筆記
在學習Celery之前,我先簡單的去了解了一下什麼是生產者消費者模式。
生產者消費者模式
在實際的軟體開發過程中,經常會碰到如下場景:某個模組負責產生資料,這些資料由另一個模組來負責處理(此處的模組是廣義的,可以是類、函式、執行緒、程序等)。產生資料的模組,就形象地稱為生產者;而處理資料的模組,就稱為消費者。
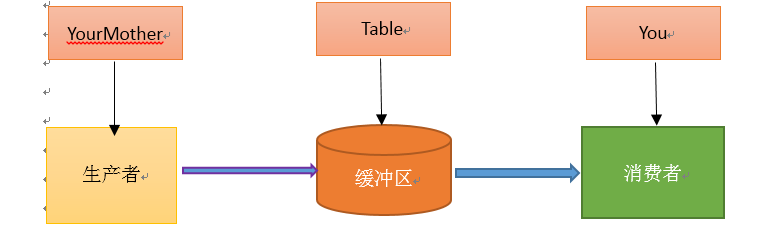
單單抽象出生產者和消費者,還夠不上是生產者消費者模式。該模式還需要有一個緩衝區處於生產者和消費者之間,作為一箇中介。生產者把資料放入緩衝區,而消費者從緩衝區取出資料,如下圖所示:

生產者消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通訊,而通過訊息佇列(緩衝區)來進行通訊,所以生產者生產完資料之後不用等待消費者處理,直接扔給訊息佇列,消費者不找生產者要資料,而是直接從訊息佇列裡取,訊息佇列就相當於一個緩衝區,平衡了生產者和消費者的處理能力。這個訊息佇列就是用來給生產者和消費者解耦的。------------->這裡又有一個問題,什麼叫做解耦?
解耦:假設生產者和消費者分別是兩個類。如果讓生產者直接呼叫消費者的某個方法,那麼生產者對於消費者就會產生依賴(也就是耦合)。將來如果消費者的程式碼發生變化,可能會影響到生產者。而如果兩者都依賴於某個緩衝區,兩者之間不直接依賴,耦合也就相應降低了。生產者直接呼叫消費者的某個方法,還有另一個弊端。由於函式呼叫是同步的(或者叫阻塞的),在消費者的方法沒有返回之前,生產者只好一直等在那邊。萬一消費者處理資料很慢,生產者就會白白糟蹋大好時光。緩衝區還有另一個好處。如果製造資料的速度時快時慢,緩衝區的好處就體現出來了。當資料製造快的時候,消費者來不及處理,未處理的資料可以暫時存在緩衝區中。等生產者的製造速度慢下來,消費者再慢慢處理掉。
因為太抽象,看過網上的說明之後,通過我的理解,我舉了個例子:吃包子。
假如你非常喜歡吃包子(吃起來根本停不下來),今天,你媽媽(生產者)在蒸包子,廚房有張桌子(緩衝區),你媽媽將蒸熟的包子盛在盤子(訊息)裡,然後放到桌子上,你正在看巴西奧運會,看到蒸熟的包子放在廚房桌子上的盤子裡,你就把盤子取走,一邊吃包子一邊看奧運。在這個過程中,你和你媽媽使用同一個桌子放置盤子和取走盤子,這裡桌子就是一個共享物件。生產者新增食物,消費者取走食物。桌子的好處是,你媽媽不用直接把盤子給你,只是負責把包子裝在盤子裡放到桌子上,如果桌子滿了,就不再放了,等待。而且生產者還有其他事情要做,消費者吃包子比較慢,生產者不能一直等消費者吃完包子把盤子放回去再去生產,因為吃包子的人有很多,如果這期間你好朋友來了,和你一起吃包子,生產者不用關注是哪個消費者去桌子上拿盤子,而消費者只去關注桌子上有沒有放盤子,如果有,就端過來吃盤子中的包子,沒有的話就等待。對應關係如下圖:
考察了一下,原來當初設計這個模式,主要就是用來處理併發問題的,而Celery就是一個用python寫的並行分散式框架。
然後我接著去學習Celery
Celery的定義
Celery(芹菜)是一個簡單、靈活且可靠的,處理大量訊息的分散式系統,並且提供維護這樣一個系統的必需工具。
我比較喜歡的一點是:Celery支援使用任務佇列的方式在分佈的機器、程序、執行緒上執行任務排程。然後我接著去理解什麼是任務佇列。
任務佇列
任務佇列是一種線上程或機器間分發任務的機制。
訊息佇列
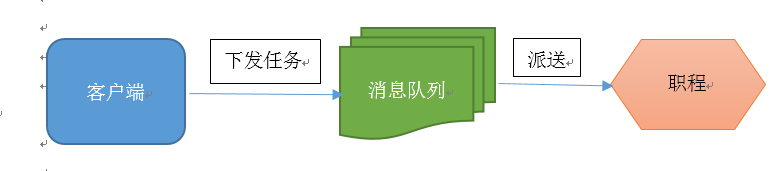
訊息佇列的輸入是工作的一個單元,稱為任務,獨立的職程(Worker)程序持續監視佇列中是否有需要處理的新任務。
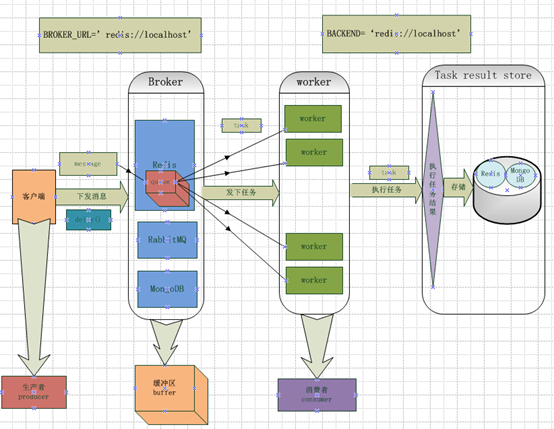
Celery 用訊息通訊,通常使用中間人(Broker)在客戶端和職程間斡旋。這個過程從客戶端向佇列新增訊息開始,之後中間人把訊息派送給職程,職程對訊息進行處理。如下圖所示:
Celery 系統可包含多個職程和中間人,以此獲得高可用性和橫向擴充套件能力。
Celery的架構
Celery的架構由三部分組成,訊息中介軟體(message broker),任務執行單元(worker)和任務執行結果儲存(task result store)組成。
訊息中介軟體
Celery本身不提供訊息服務,但是可以方便的和第三方提供的訊息中介軟體整合,包括,RabbitMQ,Redis,MongoDB等,這裡我先去了解RabbitMQ,Redis。
任務執行單元
Worker是Celery提供的任務執行的單元,worker併發的執行在分散式的系統節點中
任務結果儲存
Task result store用來儲存Worker執行的任務的結果,Celery支援以不同方式儲存任務的結果,包括Redis,MongoDB,Django ORM,AMQP等,這裡我先不去看它是如何儲存的,就先選用Redis來儲存任務執行結果。
然後我接著去安裝Celery,在安裝Celery之前,我已經在自己虛擬機器上安裝好了Python,版本是2.7,是為了更好的支援Celery的3.0以上的版本。

因為涉及到訊息中介軟體,所以我先去選擇一個在我工作中要用到的訊息中介軟體(在Celery幫助文件中稱呼為中間人<broker>),為了更好的去理解文件中的例子,我安裝了兩個中介軟體,一個是RabbitMQ,一個redis。
在這裡我就先根據Celery3.1的幫助文件安裝和設定RabbitMQ, 要使用 Celery,我們需要建立一個 RabbitMQ 使用者、一個虛擬主機,並且允許這個使用者訪問這個虛擬主機。下面是我在個人虛擬機器Ubuntu14.04上的設定:
$ sudo rabbitmqctl add_user forward password
#建立了一個RabbitMQ使用者,使用者名稱為forward,密碼是password
$ sudo rabbitmqctl add_vhost ubuntu
#建立了一個虛擬主機,主機名為ubuntu
$ sudo rabbitmqctl set_permissions -p ubuntu forward ".*" ".*" ".*"
#允許使用者forward訪問虛擬主機ubuntu,因為RabbitMQ通過主機名來與節點通訊
$ sudo rabbitmq-server
之後我啟用RabbitMQ伺服器,結果如下,成功執行:
之後我安裝Redis,它的安裝比較簡單,如下:
$ sudo pip install redis
然後進行簡單的配置,只需要設定 Redis 資料庫的位置:
BROKER_URL = 'redis://localhost:6379/0'
URL的格式為:
redis://:password@hostname:port/db_number
URL Scheme 後的所有欄位都是可選的,並且預設為 localhost 的 6379 埠,使用資料庫 0。我的配置是:
redis://:password@ubuntu:6379/5
之後安裝Celery,我是用標準的Python工具pip安裝的,如下:
$ sudo pip install celery
為了測試Celery能否工作,我運行了一個最簡單的任務,編寫tasks.py,如下圖所示:
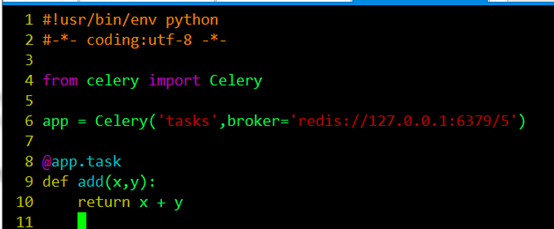
編輯儲存退出後,我在當前目錄下執行如下命令:
$ celery -A tasks worker --loglevel=info
#查詢文件,瞭解到該命令中-A引數表示的是Celery APP的名稱,這個例項中指的就是tasks.py,後面的tasks就是APP的名稱,worker是一個執行任務角色,後面的loglevel=info記錄日誌型別預設是info,這個命令啟動了一個worker,用來執行程式中add這個加法任務(task)。
然後看到介面顯示結果如下:
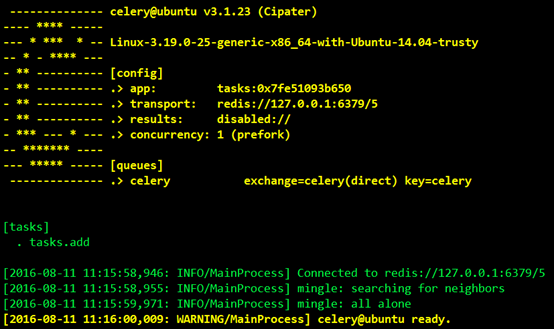
我們可以看到Celery正常工作在名稱ubuntu的虛擬主機上,版本為3.1.23,在下面的[config]中我們可以看到當前APP的名稱tasks,運輸工具transport就是我們在程式中設定的中間人redis://127.0.0.1:6379/5,result我們沒有設定,暫時顯示為disabled,然後我們也可以看到worker預設使用perfork來執行併發,當前併發數顯示為1,然後可以看到下面的[queues]就是我們說的佇列,當前預設的佇列是celery,然後我們看到下面的[tasks]中有一個任務tasks.add.
瞭解了這些之後,根據文件我重新開啟一個terminal,然後執行Python,進入Python互動介面,用delay()方法呼叫任務,執行如下操作:
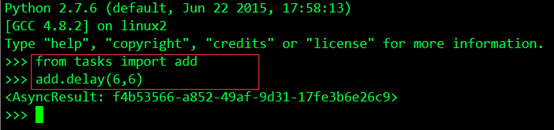
這個任務已經由之前啟動的Worker非同步執行了,然後我開啟之前啟動的worker的控制檯,對輸出進行檢視驗證,結果如下:

綠色部分第一行說明worker收到了一個任務:tasks.add,這裡我們和之前傳送任務返回的AsyncResult對比我們發現,每個task都有一個唯一的ID,第二行說明了這個任務執行succeed,執行結果為12。
檢視資料說呼叫任務後會返回一個AsyncResult例項,可用於檢查任務的狀態,等待任務完成或獲取返回值(如果任務失敗,則為異常和回溯)。但這個功能預設是不開啟的,需要設定一個 Celery 的結果後端(backend),這塊我在下一個例子中進行了學習。
通過這個例子後我對Celery有了初步的瞭解,然後我在這個例子的基礎上去進一步的學習。
因為Celery是用Python編寫的,所以為了讓程式碼結構化一些,就像一個應用,我使用python包,建立了一個celery服務,命名為pj。檔案目錄如下:

celery.py
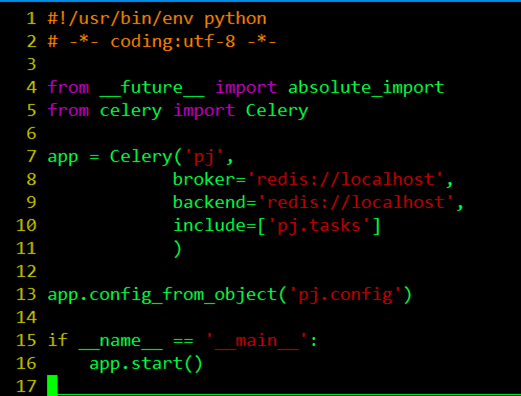
from __future __ import absolute_import
#定義未來檔案的絕對進口,而且絕對進口必須在每個模組的頂部啟用。
from celery import Celery
#從celery匯入Celery的應用程式介面
App.config_from_object(‘pj.config’)
#從config.py中匯入配置檔案
if __name__ == ‘__main__’:
app.start()
#執行當前檔案,執行celery
app = Celery(‘pj’,
broker=‘redis://localhost’,
backend=‘redis://localhost’,
include=[‘pj.tasks’]
)
#首先建立了一個celery例項app,例項化的過程中,制定了任務名pj(與當前檔案的名字相同),Celery的第一個引數是當前模組的名稱,在這個例子中就是pj,後面的引數可以在這裡直接指定,也可以寫在配置檔案中,我們可以呼叫config_from_object()來讓Celery例項載入配置模組,我的例子中的配置檔案起名為config.py,配置檔案如下:
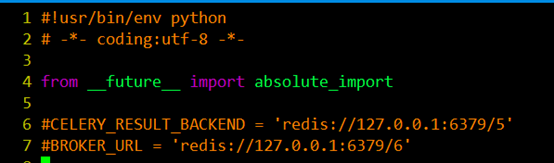
在配置檔案中我們可以對任務的執行等進行管理,比如說我們可能有很多的任務,但是我希望有些優先順序比較高的任務先被執行,而不希望先進先出的等待。那麼需要引入一個佇列的問題. 也就是說在我的broker的訊息儲存裡面有一些佇列,他們並行執行,但是worker只從對應 的佇列裡面取任務。在這裡我們希望tasks.py中的add先被執行。task中我設定了兩個任務:
所以我通過from celery import group引入group,用來建立並行執行的一組任務。然後這塊現需要理解的就是這個@app.task,@符號在python中用作函式修飾符,到這塊我又回頭去看python的裝飾器(在程式碼執行期間動態增加功能的方式)到底是如何實現的,在這裡的作用就是通過task()裝飾器在可呼叫的物件(app)上建立一個任務。
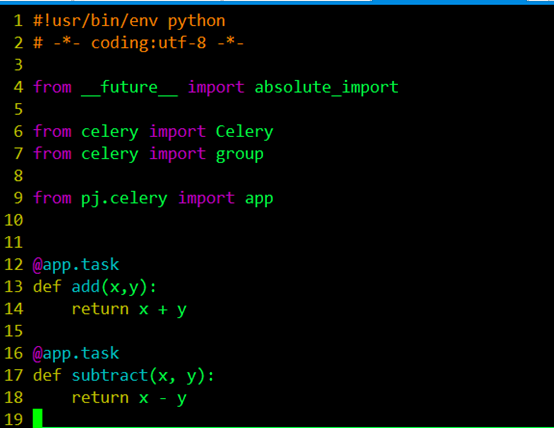
瞭解完裝飾器後,我回過頭去整理配置的問題,前面提到任務的優先順序問題,在這個例子中如果我們想讓add這個加法任務優先於subtract減法任務被執行,我們可以將兩個任務放到不同的佇列中,由我們決定先執行哪個任務,我們可以在配置檔案中這樣配置:

先了解了幾個常用的引數的含義:
Exchange:交換機,決定了訊息路由規則;
Queue:訊息佇列;
Channel:進行訊息讀寫的通道;
Bind:綁定了Queue和Exchange,意即為符合什麼樣路由規則的訊息,將會放置入哪一個訊息佇列;
我將add這個函式任務放在了一個叫做for_add的佇列裡面,將subtract這個函式任務放在了一個叫做for_subtract的佇列裡面,然後我在當前應用目錄下執行命令:

這個worker就只負責處理for_add這個佇列的任務,執行這個任務:

任務已經被執行,我在worker控制檯檢視結果:

可以看到worker收到任務,並且執行了任務。
在這裡我們還是在互動模式下手動去執行,我們想要crontab的定時生成和執行,我們可以用celery的beat去週期的生成任務和執行任務,在這個例子中我希望每10秒鐘產生一個任務,然後去執行這個任務,我可以這樣配置:
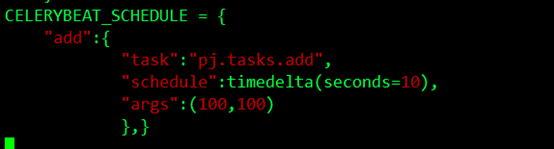
使用了scheduler,要制定時區:CELERY_TIMEZONE = 'Asia/Shanghai',啟動celery加上-B的引數:

並且要在config.py中加入from datetime import timedelta。
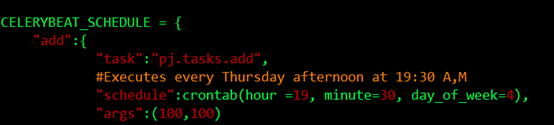
更近一步,如果我希望在每週四的19點30分生成任務,分發任務,讓worker取走執行,可以這樣配置:
看完這些基礎的東西,我回過頭對celery在回顧了一下,用圖把它的框架大致畫出來,如下圖: