Hive 內建函式及自定義函式
1.內建函式
使用如下命令檢視當前hive版本支援的所有內建函式
show functions;部分截圖:
可以使用如下命令檢視某個函式的使用方法及作用,比如檢視 upper函式
desc function upper;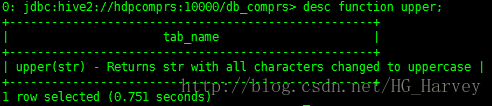
如果想要檢視更為詳細的資訊加上extended引數
desc function extended upper;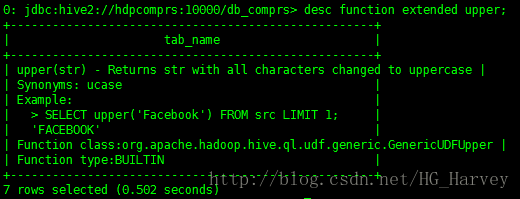
內建函式使用
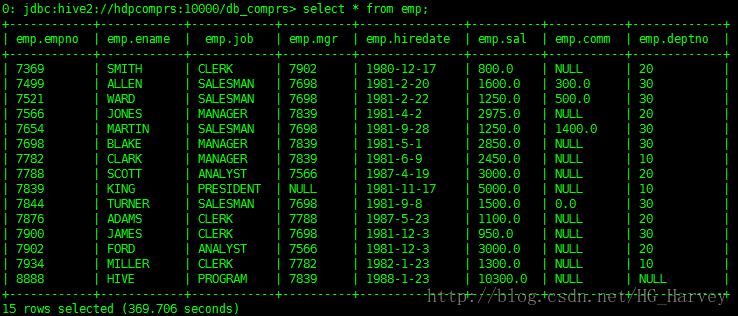
員工表emp,資料如下
- lower():轉換為小寫
查詢emp表中員工姓名,員工姓名小寫顯示
select empno,ename,lower(ename) from emp;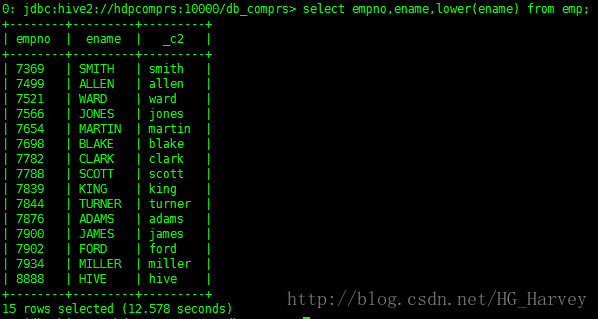
- 字串連線:concat()
查詢emp表,將員工姓名追加到員工編號後
select empno,ename,concat(empno,ename) from emp;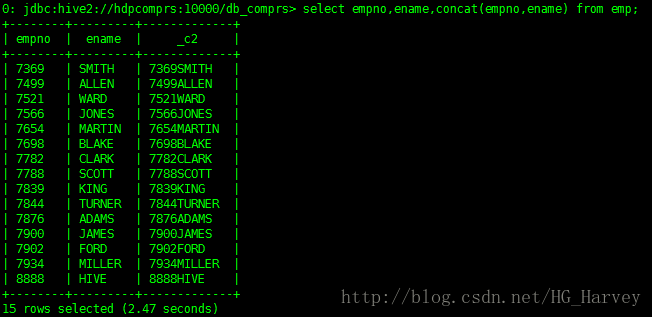
2.自定義函式
雖然hive中為我們提供了很多的內建函式,但是在實際工作中,有些情況下hive提供的內建函式無法滿足我們的需求,就需要我們自己來手動編寫,所以就有了自定義函式 UDF。
UDF分為三種,分別如下
(1).UDF(User-Defined-Function),一進一出(輸入一行,輸出一行),比如:upper()、lowser()等。
(2).UDAF(User-Defined Aggregation Funcation),多進一出(輸入多行,輸出一行),比如:avg()、sum()等。
(3).UDTF(User-Defined Table-Generating Functions),一進多出(輸入一行,輸出多行),比如:collect_set()、collect_list()等。
使用自定義函式需要引入hive-exec的依賴
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.0</version>
</dependency 1.自定義UDF函式
UDF程式設計模型:
(1).繼承 org.apache.hadoop.hive.ql.exec.UDF
(2).實現 evaluate() 方法
實現需求:自定義UDF函式,給指定的字串前加上字串hello:
比如:輸入zhangsan,輸出hello:zhangsan
程式碼:
package com.bigdata.hadoop.hive;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
/**
* 自定義UDF函式
* 輸入:Tom
* 輸出:hello:Tom
*/
@Description(
name = "say_hello,ucase",
value = "_FUNC_(str) - Returns str start with hello:",
extended = "Example:\n > SELECT _FUNC_(\'Facebook\') FROM src LIMIT 1;\n \'hello:Facebook\'"
)
public class GenericUDFHello extends UDF {
public String evaluate (final Text s){
if (s == null) {
return null;
}
return "hello:" + s.toString();
}
public static void main(String[] args) {
System.out.println(new GenericUDFHello().evaluate(new Text("Tom")));
}
}自定義函式有4種使用方式,下面筆者分別來介紹
- 方式一(臨時函式,只能在當前客戶端使用)
將我們剛剛編寫完成的程式碼,打成jar
將jar包上傳到hive
add jar /home/hadoop/libs/hive-1.0-SNAPSHOT.jar;建立函式
create temporary function say_hello as 'com.bigdata.hadoop.hive.GenericUDFHello';檢視建立的函式say_hello
show functions;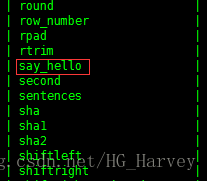
檢視函式say_hello的詳細資訊
desc function extended say_hello;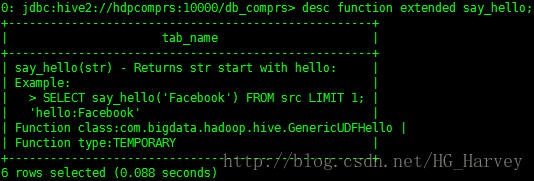
使用函式
select ename,say_hello(ename) from emp;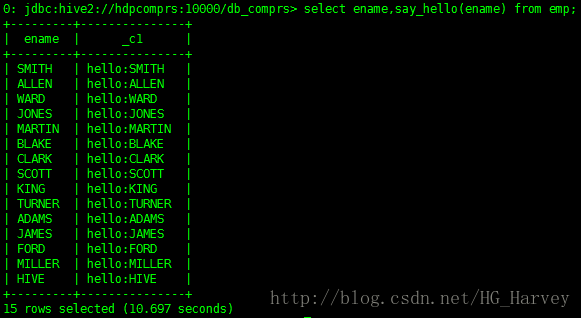
- 方式二(臨時函式,只能在當前客戶端使用)
在$HIVE_HOME下新建目錄auxlib,將jar拷貝到該目錄下,重啟hadoop
$ cd $HIVE_HOME
$ mkdir auxlib
$ cd auxlib/
$ cp /home/hadoop/libs/hive-1.0-SNAPSHOT.jar .建立函式say_hello2
create temporary function say_hello2 as 'com.bigdata.hadoop.hive.GenericUDFHello';檢視建立的函式,同上
使用函式,效果同上
select ename,say_hello2(ename) from emp;- 方式三(永久函式,建立後可以在任意客戶端使用,建議使用)
上傳jar到hdfs
$ hadoop fs -put hive-1.0-SNAPSHOT.jar /libs建立函式 say_hello3
create function say_hello3 as 'com.bigdata.hadoop.hive.GenericUDFHello' using jar 'hdfs://hdpcomprs:9000/libs/hive-1.0-SNAPSHOT.jar';注意:建立完function之後,通過show functions並沒有看到我們自定義的函式say_hello3,但是可以使用
使用函式,效果同上
select ename,say_hello3(ename) from emp;- 方式四(永久函式,將自定義函式整合到hive原始碼中)
使用這種方式需要修改hive的原始碼,整合到hive原始碼後,hive啟動後就可以使用,不用再向hive中註冊函式,相當於一個hive的內建函式。如果公司有自己的大資料框架版本,建議使用這種方式。
下載後解壓
$ tar -zxvf apache-hive-2.3.0-src.tar.gz將自定義UDF函式繼承到Hive原始碼中,需要如下三個步驟
(1).上傳檔案
把GenericUDFHello.java類上傳到如下目錄,並修改包名
$ cd apache-hive-2.3.0-src/ql/src/java/org/apache/hadoop/hive/ql/udf
$ rz
$ vim GenericUDFHello.java
package org.apache.hadoop.hive.ql.udf;
(2).配置FunctionRegistry類
hive 中有一個非常重要的類FunctionRegistry,我們需要將自己自定義的函式在這個類中配置,引入我們自定義函式類GenericUDFHello
$ cd apache-hive-2.3.0-src/ql/src/java/org/apache/hadoop/hive/ql/exec
$ vim FunctionRegistry.java
import org.apache.hadoop.hive.ql.udf.GenericUDFHello;註冊自定義函式類GenericUDFHello,輸入static { 搜尋,在靜態程式碼塊中註冊我們編寫的自定義函式,這裡面都是hive的所有內建函式,新增如下程式碼
system.registerUDF("hello", GenericUDFHello.class, false);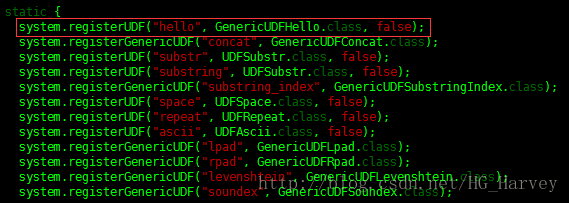
(3).編譯 Hive 原始碼
$ cd apache-hive-2.3.0-src
$ mvn clean package -Phadoop-2,dist -DskipTests
-Phadoop-2表示使用的hadoop版本為2,如果為1,則寫-Phadoop-1編譯過程教程,請耐心等待,編譯完成後,hive會生成一個壓縮包,解壓配置後就可以使用,hive壓縮包存放的路徑是apache-hive-2.3.0-src/packaging/target
使用函式hello(效果同上)
select empno,ename,hello(ename) from emp;2.自定義UDAF函式
UDAF程式設計模型
(1).繼承 org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
(2).實現 evaluate() 方法
(3).編寫靜態內部類(函式的計算邏輯),繼承GenericUDAFEvaluator,必須重寫如下方法
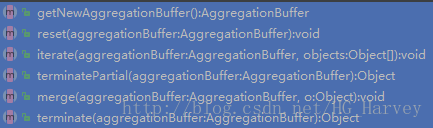
UDAF同樣有四種使用方式(參照自定義函式UDF中的介紹)
實現需求:計算表中某列字母的個數
程式碼:
package com.bigdata.hadoop.hive;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
/**
* 自定義UDAF函式
* 計算表中某列字母的個數
*/
@Description(
name = "numofletters",
value = "_FUNC_(x) - Returns the total number of characters of all the strings in that column"
)
public class GenericUDAFTotalNumOfLetters extends AbstractGenericUDAFResolver {
// 返回聚合函式在經過map combiner reduce 的階段時使用的計算器
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
return new TotalNumOfLettersEvaluator();
}
// 靜態內部類,聚合函式的計算邏輯
public static class TotalNumOfLettersEvaluator extends GenericUDAFEvaluator{
//兩個輸入型別一個輸出型別
ObjectInspector out;
PrimitiveObjectInspector text,num;
// map combiner reduce 的階段都會執行的方法
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m, parameters);// 註釋掉則整個程式將無法執行
// 表示正在執行 map 階段
if(m == Mode.PARTIAL1 || m==Mode.COMPLETE){
//儲存計算map輸入的資料型別,即sql型別
text= (PrimitiveObjectInspector) parameters[0];
}else { //表示正在執行 combiner 或者 reduce
//儲存計算的 combiner 或者 reduce 階段的輸入資料型別
num = (PrimitiveObjectInspector) parameters[0];
}
out= ObjectInspectorFactory.getReflectionObjectInspector(Integer.class,
ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
return out;
}
// 會根據mode決定呼叫merge還是iterate
@Override
public void aggregate(AggregationBuffer agg, Object[] parameters) throws HiveException {
super.aggregate(agg, parameters);
}
// 儲存當前字元總數的靜態內部類
static class LetterSumAgg implements AggregationBuffer{
int sum;
public void add(int num){
sum+=num;
}
}
//計算器在階段處理中用來獲取一個新的中間儲存物件
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
LetterSumAgg letterSumAgg = new LetterSumAgg();
return letterSumAgg;
}
// 重置階段中儲存的資料,清除
public void reset(AggregationBuffer aggregationBuffer) throws HiveException {
LetterSumAgg letterSumAgg = new LetterSumAgg();
}
// map計算階段迭代統計字元個數
public void iterate(AggregationBuffer aggregationBuffer, Object[] parameters) throws HiveException {
if (parameters[0] != null) {
LetterSumAgg letterSumAgg = (LetterSumAgg) aggregationBuffer;
Object p1 = text.getPrimitiveJavaObject(parameters[0]);
letterSumAgg.add(String.valueOf(p1).length());
}
}
// 返回一個map或combiner階段計算器統計的結果,即map或combiner的輸出
public Object terminatePartial(AggregationBuffer aggregationBuffer) throws HiveException {
return ((LetterSumAgg)aggregationBuffer).sum;
}
// 計算器在被combiner或者reduce階段執行時呼叫,合併之前階段的部分統計結果
public void merge(AggregationBuffer aggregationBuffer, Object partial) throws HiveException {
if (partial != null) {
LetterSumAgg letterSumAgg = (LetterSumAgg) aggregationBuffer;
Integer partialSum = (Integer) num.getPrimitiveJavaObject(partial);
letterSumAgg.add(partialSum);
}
}
// 計算器在被reduce階段執行時呼叫,合併之前階段的部分統計結果,最終返回確定的結果輸出
public Object terminate(AggregationBuffer aggregationBuffer) throws HiveException {
return ((LetterSumAgg) aggregationBuffer).sum;
}
}
}上傳jar到hive
add jar /home/hadoop/libs/hive-1.0-SNAPSHOT.jar;建立臨時函式
create function numofletters as 'com.bigdata.hadoop.hive.GenericUDAFTotalNumOfLetters';檢視建立的臨時函式
show functions;
檢視函式的詳細資訊
desc function numofletters;
使用函式
tb_test 表中資料如下
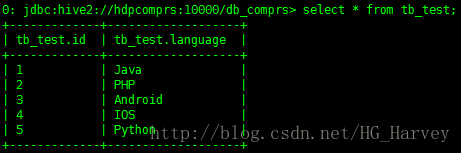
計算emp表中ename列字母個數(會執行mapreduce作業)
select numofletters(language) from tb_test;
3.自定義UDTF函式
(1).繼承 org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
(2).實現三個方法 initialize()、process()、close()
UDTF也有四種使用方式(參照自定義函式UDF中的介紹)
實現需求:切分map
輸入:key1:value1;key2:value2;
輸出:key1 value1 key2 value2
程式碼:
package com.bigdata.hadoop.hive;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
/**
* 自定義UDTF函式
* 切分map
* 輸入:math:80;chinese:89;english:95;
* 輸出:math,80 chinese,89 english,95
*/
@Description(
name = "split_map",
value = "_FUNC_(x) - input key1:value1;key2:value2; output key1,value1 key2,value2"
)
public class GenericUDTFSplitMap extends GenericUDTF {
// 初始化校驗引數是否正確
@Override
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
if (args.length != 1) {
throw new UDFArgumentLengthException("ExplodeMap takes only one argument");
}
if (args[0].getCategory() != ObjectInspector.Category.PRIMITIVE) {
throw new UDFArgumentException("ExplodeMap takes string as a parameter");
}
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("col1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNames.add("col2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);
}
// 函式邏輯處理,並將結果返回(forward)
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
// 按分號分隔
String[] strings = input.split(";");
for(int i=0; i<strings.length; i++) {
try {
// 按冒號分隔
String[] result = strings[i].split(":");
forward(result);
} catch (Exception e) {
continue;
}
}
}
// 對需要清理的方法進行清理
@Override
public void close() throws HiveException {
}
}上傳jar到hive中
add jar /home/hadoop/libs/hive-1.0-SNAPSHOT.jar;建立函式
create function split_map as 'com.bigdata.hadoop.hive.GenericUDTFSplitMap';使用函式
tb_udtf表中資料如下
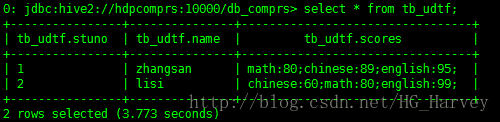
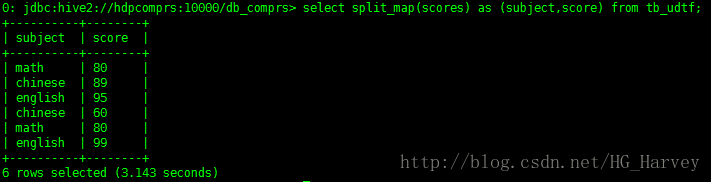
select split_map(scores) as (subject,score) from tb_udtf;