基於PHP百度圖片網路爬蟲案例
阿新 • • 發佈:2019-01-28
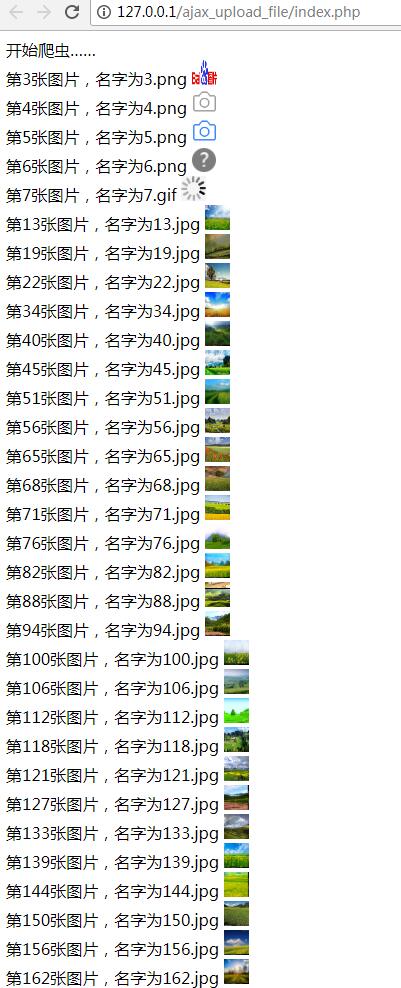
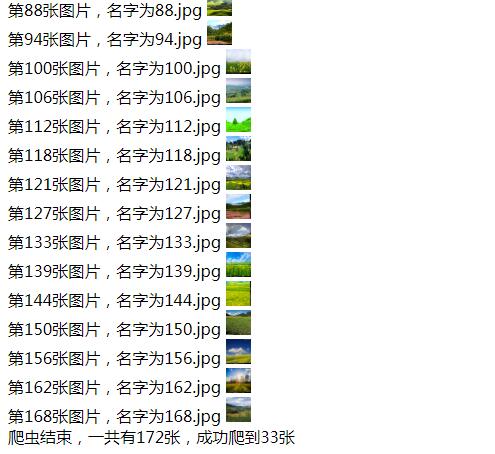
<?php header('content-type:text/html;charset=utf-8;'); $url = 'http://image.baidu.com/search/index?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs2&word=%E7%94%B0%E5%9B%AD%E8%87%AA%E7%84%B6%E9%A3%8E%E5%85%89&oriquery=%E8%87%AA%E7%84%B6%E9%A3%8E%E5%85%89&ofr=%E8%87%AA%E7%84%B6%E9%A3%8E%E5%85%89&hs=2&sensitive=0';//爬蟲目標地址 @ini_set("implicit_flush",1);//在程式碼中設定及時輸出 ob_implicit_flush(1);//開啟及時輸出開啟 @ob_end_clean();//清除快取內容 echo '開始爬蟲……<br>'; ini_set("max_execution_time", "120");//設定最大執行時間 $res = file_get_contents($url); preg_match_all('/[^>"]*\.(?:png|jpg|bmp|gif|jpeg)/',$res,$img_matches);//正則匹配圖片 $count = 0; foreach ($img_matches[0] as $key => $value) { if(strpos($value, '=') === FALSE && (strpos($value, '{') === FALSE || strpos($value, '}') === FALSE)){ $ext = substr($value, strrpos($value, '.')); if(strpos($value, 'http') === FALSE){ $value = 'http:'.$value; } $img = @file_get_contents($value); $one_level_dir = date("Y"); $two_level_dir = $one_level_dir.'/'.date("m-d"); if(!is_dir($one_level_dir)){ mkdir($one_level_dir); } if(!is_dir($two_level_dir)){ mkdir($two_level_dir); } $new_file = $two_level_dir.'/'.$key.$ext; if($img && file_put_contents($new_file, $img)){ $count++; echo '第'.$key.'張圖片,名字為'.$key.$ext.' <img src="'.$new_file.'" width="25" height="25" alt="" /><br>'; } } } echo '爬蟲結束,一共有'.count($img_matches[0]).'張,成功爬到'.$count.'張';
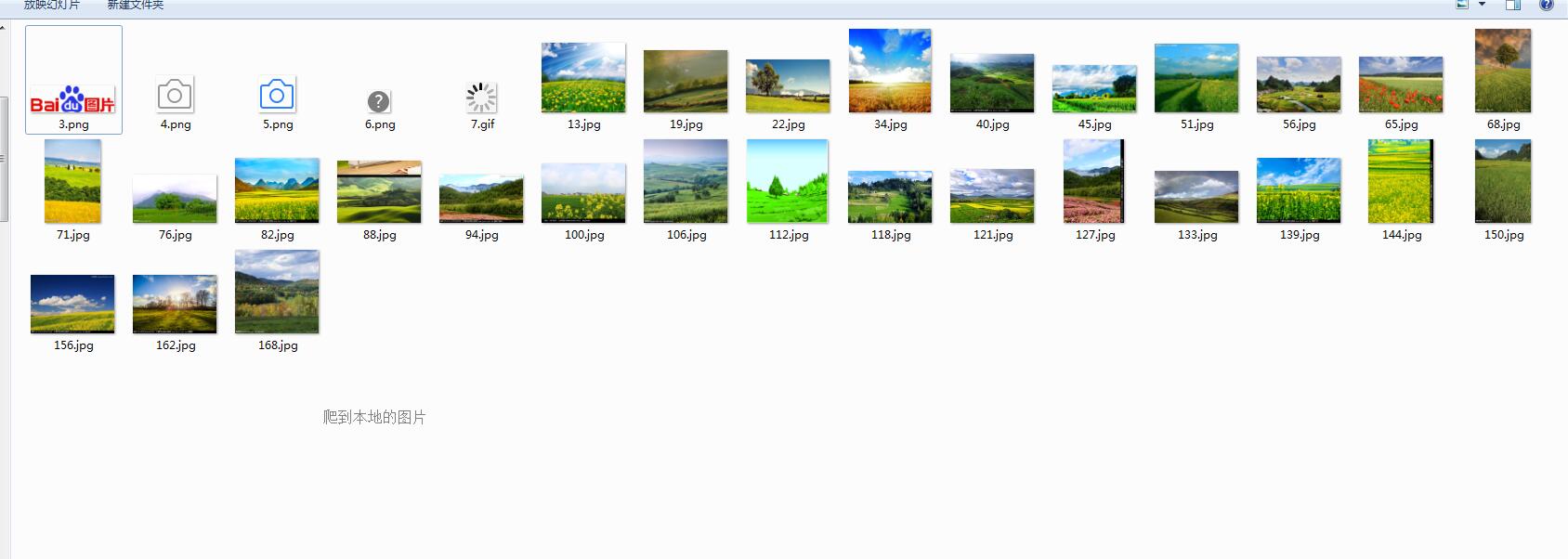
效果截圖: