
【DirectX11】第二篇 DirectX11渲染管線(2016.05.09更新)
本系列文章主要翻譯和參考自《Real-Time 3D Rendering with DirectX and HLSL》一書(感謝原書作者),同時會加上一點個人理解和拓展,文章中如有錯誤,歡迎指正。
這裡是書中的程式碼和資源。
本文索引:
DirectX11 渲染管線
一般計算機中共有兩個處理器是你可能會對其進行程式設計的,一個是central processing unit(CPU),一個是GPU。這兩個元件有著截然不同的硬體結構和指令集。在圖形程式設計領域,你編寫的軟體可能兩方面都要涉及,對於CPU,你可能會使用到例如C++這樣的程式語言,而對於GPU則需要使用諸如HLSL這樣的語言。大部分關於圖形程式設計的文章要麼集中於CPU方面要麼是GPU方面,這些內容其實都是有緊密聯絡的。在本書中,你將可以同時瞭解到兩方面的內容。
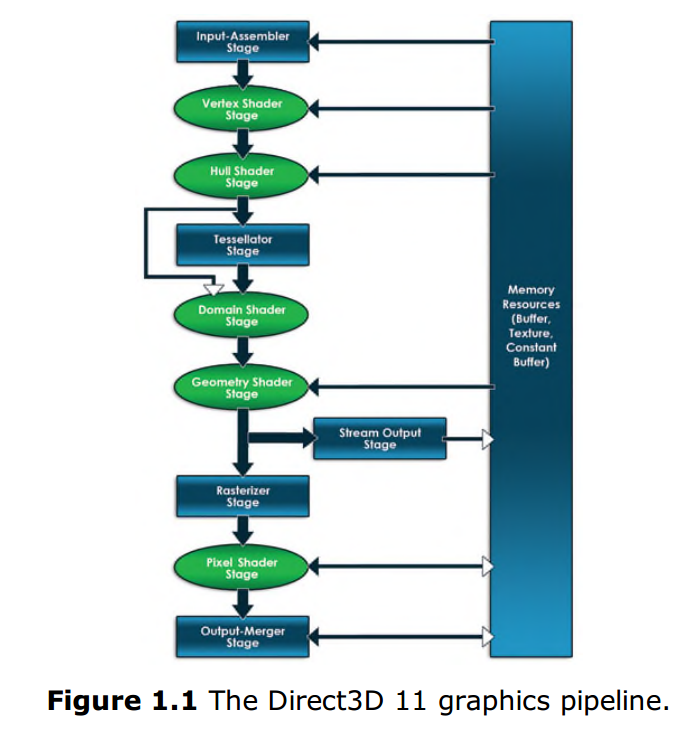
DirectX當中的DirectX 3D API是本書著重關注的部分。Direct3D是用來繪製3D圖形的系統介面,他還定義了怎樣將實時圖形渲染到螢幕的一系列步驟。這些步驟就被稱之為DirectX3D圖形渲染管線(詳見圖1.1)。在這張圖中,單向箭頭標識了資料是怎樣從一個階段傳輸到下一個,雙向箭頭則標識了資源和哪些渲染階段間可以進行資料讀寫。那些可以用HLSL程式設計的模組已經用橢圓形標識出來。接下來的內容將會詳細介紹渲染管線中的各個模組。
一、 輸入裝配階段:The Input-Assembler Stage(IA)
輸入裝配階段是渲染管線的入口,也是第一個階段,在這個階段裡你需要提供待渲染物件的頂點和索引資料。輸入裝配階段將這些資料“裝配”成基本型別資料(例如:點列表,線條帶,三角列表)並根據需要將資料輸出給頂點著色渲染階段。
(1) Vertex Buffers頂點快取
一個頂點至少包含了在3D空間中的一個位置。之所以說至少是因為頂點還可以包含顏色資訊,法線資訊(用於計算光照),紋理座標資訊等等。所有這些資料都可以在輸入裝配階段進行頂點快取。Direct3D中定義的這些頂點資訊完全可以由程式設計師進行操作。你可以定義頂點所要包含的資訊並通過input-layout物件定義頂點快取資料如何流入IA階段。之後的文章(原書Part III,Rendering with DirectX)中將會介紹如何定義頂點快取以及input layout物件,現在只是大概的介紹一下這些術語。
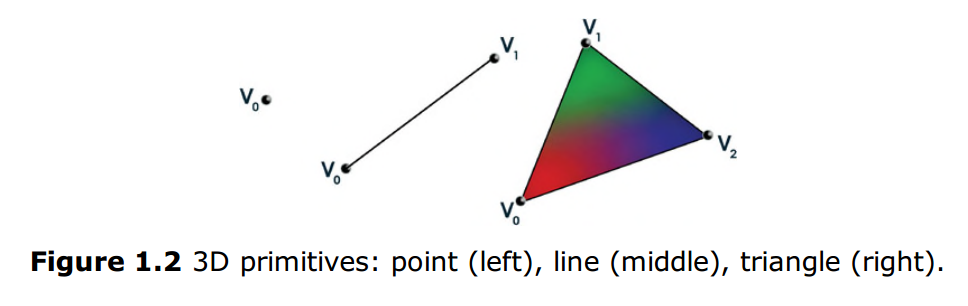
兩個頂點代表線段的兩個端點,三個頂點可以代表一個三角形(如圖1.2)。
(2) Index Buffers索引快取
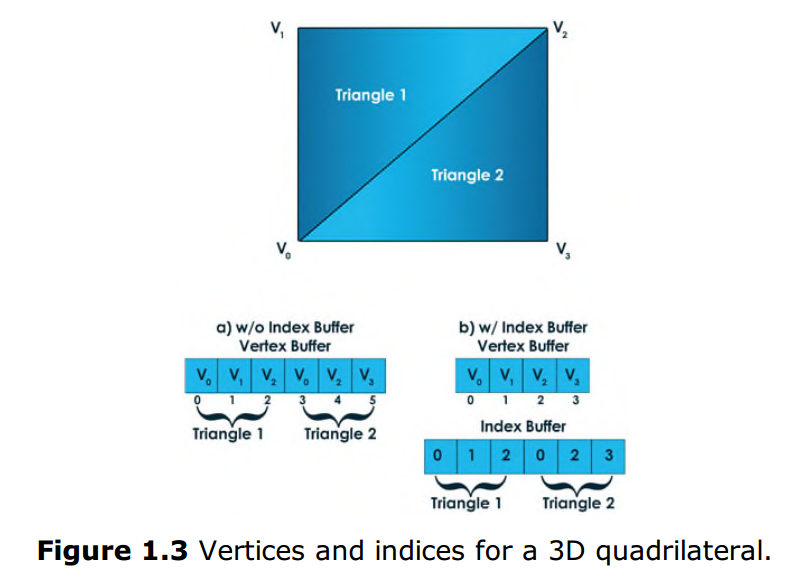
索引快取是第二種在輸入裝配階段推薦的輸入型別。索引快取的定義關聯了頂點快取中的某些頂點,可以用來減少需要多次使用到的頂點的重複。想象以下場景:你需要渲染一個矩形(或寬泛的說,四邊形)。這個四邊形至少需要定義四個頂點。但是Direct3D並不支援將四邊形作為基礎型別(因為根本沒有必要專門定義一個四邊形,所有的四邊形都可以拆分成三角形)。為了渲染這個四邊形,你需要將其拆分成兩個由三個頂點構成的三角形(如圖1.3)。所以,現在你需要總共六個頂點資訊,而不是四個,其中必然有兩個頂點資訊是重複的。但如果定義了索引快取,你就可以通過定義四個頂點資訊和六個與頂點快取相關的索引資訊來完成渲染。
現在,你可能會思考一個問題,“我怎麼通過增加索引快取來減少我所使用的整體資料大小呢?”那麼我們需要再考慮兩種情況,通過結合上面提到的四邊形進行具體資料分析:
第一種情況
你的頂點資料只包含3D位置資訊(x,y,z),每個軸向需要一個32-bit來儲存這個浮點數(每個軸向為4byte),那麼每個頂點需要12byte。所以在不包含索引快取的情況下這個四邊形只需要72位元組儲存(6 vertices * 12 bytes/vertex)。如果加上索引快取,你的頂點快取需要的空間是48byte(4 vertices * 12 bytes/vertex)。以16bit的int型別資料來儲存索引,則你需要額外12bytes(6 indices * 2 bytes/index = 12 byte)。這時,總共需要60byte來儲存這個四邊形。這麼看的話好像也沒節省很多空間。
第二種情況
當你的模型中不僅包含位置資訊,還可能包含16byte的顏色資訊,12byte的法線資訊以及8byte的紋理座標資訊。那麼每個頂點將需要多花費36byte的空間。或許當模型不是太大的時候並不會有很多影響,但如果模型具有成千上萬的點時你會發現多出來的空間佔用是相當可觀的。還有,你不僅需要考慮空間佔用的大小,還有當CPU和GPU之間進行資料傳輸時,是需要通過圖形匯流排(例如PCI Express)來傳輸的,這種匯流排的傳輸速度通常非常慢(相比於CPU向RAM傳輸,以及GPU向VRAM傳輸),所以如何減少資料對你來說將會是至關重要的。
(3) Primitive Types基本型別
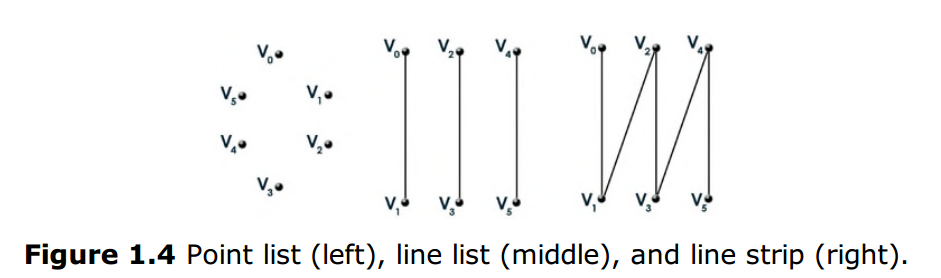
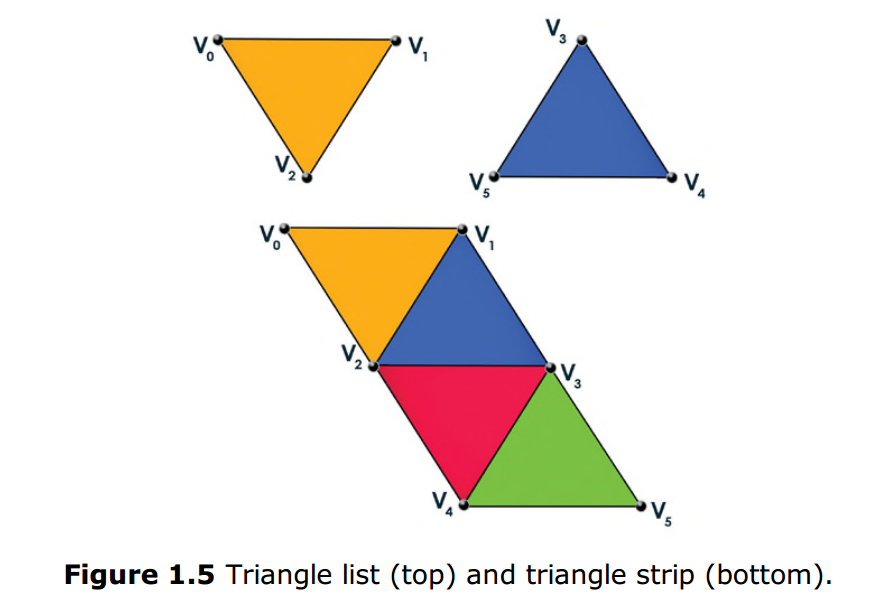
當你向IA階段提供頂點快取資料時,你也必須定義這些頂點的拓撲結構,這決定了渲染管線將如何解釋執行這些頂點。DirectX3D提供了以下幾種基本型別(如圖1.4和1.5):
- Point list 點列表:一系列單獨渲染毫無關聯的點
- Line list 線列表:一系列成對關聯的點,這些一對一對的點之間是沒有關聯的
- Line strip 線條帶:一系列成對關聯的點,但每對點的末點會和下一對點的起點有關聯
- Triangle list 三角列表:是我們最常見的拓撲結構,在三角列表中每三個頂點組成一個獨立的三角形。三角形之間公用的點將會重複出現(除非定義了索引快取)。
- Triangle strip 三角條帶:每三個頂點構成一個三角形,公用的頂點將不會重複,所以頂點間會密切的連在一起。

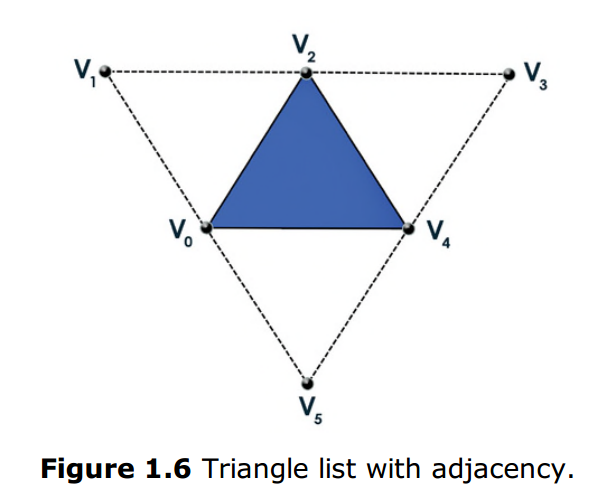
(4) Primitive with Adjacency鄰接基元
從DirectX10開始,Direct3D已經加入了包含鄰接資料的基本資料。對於鄰接基元來說,你不只要定義基本資料,還需要定義圍繞在這個基元周圍的資料。(如圖1.6)這是用來做幾何著色器的,這裡每個特定的集合著色程式需要訪問鄰接三角形。臨界三角形需要和原始三角形一起被提交給頂點/索引緩衝區,並且用D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST_ADJ這個拓撲結構。注意到鄰接三角形只是被用來作為幾何著色器的輸入,並不會被畫出來。如果沒有幾何著色器,鄰接三角形也還是不會被畫出來。
(5) Control Point Patch Lists控制點片
控制點片作為一個拓撲結構提供給細分曲面階段使用。相關內容將會在原書的第二十一章”Chapter 21, Geometry and Tessellation Shaders”中介紹。
| 參考文章:關於輸入裝配階段的詳細內容和具體實現請參考[這篇文章](http://www.aiseminar.com/bbs/home.php?mod=space&uid=3&do=blog&id=2622) |
二、 頂點著色階段:The Vertex Shader Stage(VS)
頂點著色階段主要處理從IA階段輸出的原始資料。這個階段會對每個頂點做單獨的處理。是渲染管線中第一個可程式設計的階段。實際上,不論什麼時候都需要程式設計師或軟體提供一個頂點著色器給這個階段使用。那麼到底什麼是著色器?
著色器是一段簡短的程式或者方法,你所寫的東西會直接在GPU上執行。頂點著色器會通過渲染管線在每個頂點上執行一次,在執行完一系列指令之後再輸出到下一個階段。如前一篇文章所提到的,輸入到頂點著色器的資料至少應該包含頂點位置。一般情況下,頂點著色器將頂點資料做某種形式的轉換之後再輸出成一系列新的資料。下圖是一個最簡單的頂點著色器:

三、 細分曲面階段:Tessellation Stage
這是DirectX11新加入的特性,硬體細分曲面是在GPU上直接對模型增加細節的過程。一般來說,更多的幾何細節(如更多的頂點)將會帶來更好的渲染效果。如圖1.7所示:
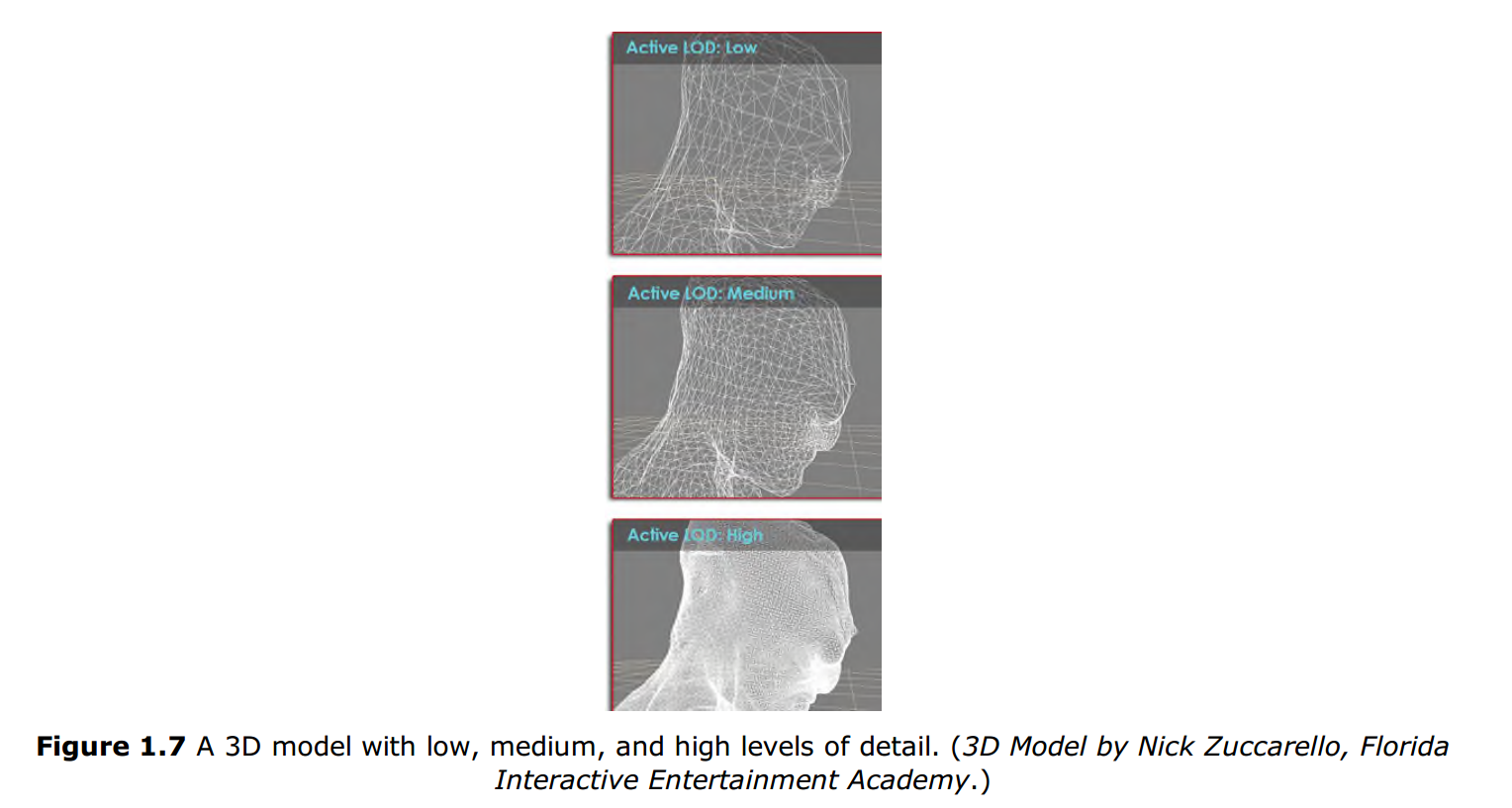
上圖展現了同一個模型使用低中高細節展示的效果。LOD模型一般是由藝術家或模型師創建出來並根據距離攝像機的大小來選擇要使用哪種細節的模型。
| 注意:如果距離攝像機視野較遠,即使是高細節的頂點數的模型也會有很多細節遺失。所以我們需要根據距離攝像機的遠近來選擇具體使用的模型——離攝像機距離越遠,細節越低。 模型細節越少,頂點著色器需要處理的資料就越少,渲染效率越高。 |
傳統的LOD系統中,你需要將你的模型修改成不同的LOD細節模型。硬體細分曲面技術使你能夠將一個模型動態的細分並且不耗費額外的多邊形資料傳輸到IA階段。這樣就可以實現動態LOD系統並且使得資料傳輸匯流排的佔用率更低。DirectX11中,以下三個階段都依賴細分曲面技術:
- The hull shader stage(HS)外殼著色器階段
- The tessellator stage
- The domain shader stage(DS)域著色器階段
HS和DS階段都是可程式設計的,但細分階段則不可以。詳細內容將會在原書的21章節介紹。更多內容瞭解可參見百科。
四、 幾何著色階段:The Geometry Shader Stage(GS)
不像頂點著色器是基於每個單獨的頂點進行運算,幾何著色器是基於完整的基本資料來運算(如點,線,三角面)。並且,幾何著色器有能力去增加或減少渲染管線中的幾何資料。這個特性可以用來實現一些很有意思的效果。例如:你可以實現一個粒子系統,這個粒子系統中的每一個頂點代表一個粒子。在幾何著色器中,你可以圍繞中心點建立很多四邊形,併為這些四邊形對映紋理。一個很有名的例子是point sprites(點精靈)。
與幾何著色階段相關的是stream-output stage(SO)輸出流階段。這個階段將會把幾何著色階段輸出的資料儲存在記憶體中。在多通道渲染中,這裡的資料可以讀回渲染管線在後面的通道中渲染,也可以提供給CPU讀取。如細分曲面階段一樣,這個階段同樣也是可選的。原書的第五部分”Part IV, Intermediate-Level Renderring Topics”中會詳細介紹這一部分。
五、 光柵化階段:The Rasterizer Stage(RS)
在之前所提到的渲染管線中,我們已經討論了頂點資料以及如何將頂點資料轉化成基本資料。光柵化階段會將這些基本資料轉化成光柵化影象,或者說點陣圖。光柵化影象使用二維陣列儲存並且顯示在電腦螢幕上。
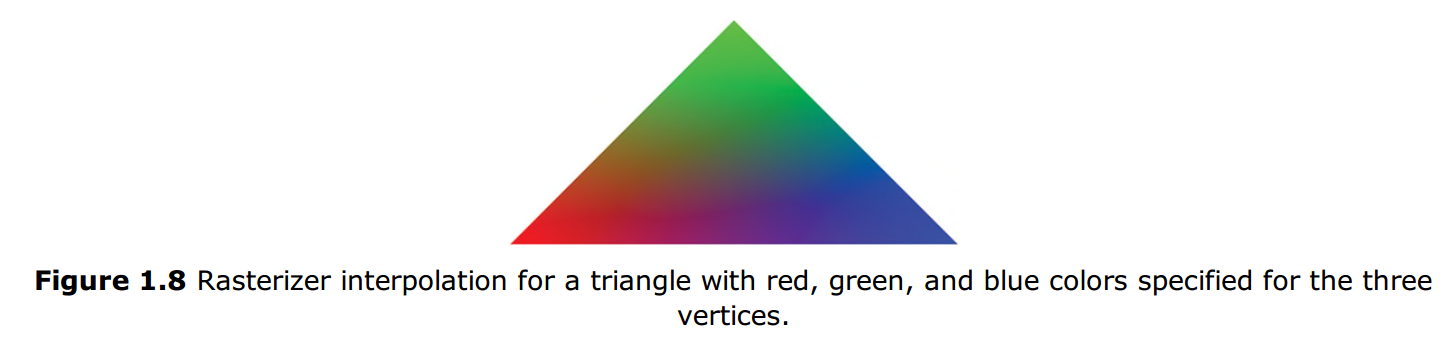
光柵化階段決定了哪些畫素將會被渲染到螢幕上並且傳遞到畫素著色器中。在光柵化階段,會將基本資料以每個頂點進行插值計算。例如,一個三角面片有三個頂點,每個至少包含了一些位置資訊,或者還包含了例如顏色,發現,紋理座標之類的資訊。光柵階段將頂點之間的那些畫素插入中間值。圖1.8展示了頂點顏色插值的概念。該圖中,三個點分別被賦予紅色,綠色和藍色。注意畫素在三角形的三個頂點間顏色是如何漸變的。
六、 畫素著色階段:The Pixel Shader Stage(PS)
從技術角度來說,你需要為畫素著色階段提供畫素著色器。這個階段將會為每個從光柵化階段輸出的畫素執行你的著色器。這使得程式設計師能夠控制每個即將輸出到螢幕的畫素點。畫素著色器使用已插值的頂點資料,全域性變數和紋理資料進行處理後輸出。如下展示了一段將每個畫素輸出成紅色的著色器。

七、 輸出混合階段:The Output-Merger Stage(OM)
輸出混合階段會產生最終需要被渲染的畫素。這個階段是不可程式設計的(意味著你不能為這個階段編寫shader),但是你可以定義這個階段在使用者自定義管線狀態時的表現 。OM階段會通過合併狀態,畫素著色器階段的輸出以及渲染目標仍然存在的內容來產生最終專案。這意味著,通過一些有趣的特效,可以產生透明物體的額顏色混合。相關內容在原書的第八章”Chapter 8, Gleaming the Cube”章節會詳細介紹。
OM階段同時也會通過深度測試(depth testing)和模板測試(stencil testing)來決定哪個畫素可以被最終渲染。
深度測試使用之前已經被寫入渲染目標(Render Target)的資料來決定哪個畫素需要被繪製。如圖1.9所示,幾個物體排成一排,一個比一個更接近攝像機,他們都存在於同一個螢幕空間中。前面的物體可能完整或者一部分遮擋了後面的物體。深度測試利用物體和相機中每個畫素的距離來決定渲染目標。通常,如果已經在渲染目標中的畫素比正在被考慮是否要渲染的畫素離攝像機的距離更近,則新的這個畫素點將被拋棄。
模板測試使用蒙版來決定每個畫素是否要被更新。這個概念類似於呈現一個具有物理表面特性的紙箱或塑料製品。詳細內容會在原書的第三部分”Part III, Rendering with DirectX.”中介紹。
| 注意:光柵化階段同樣可以決定哪些畫素將會被渲染到螢幕中,光柵化階段中的這個過程稱為裁剪(clip)。任何被光柵化階段認定為不在螢幕中的畫素都會被直接裁剪,不會再傳送到渲染管線後面的流程中進行處理。 |