
【Lucene】全文搜尋技術
大綱
1、需求分析
1.1 資料分類
我們生活中的資料總體分為兩種:結構化資料和非結構化資料。
結構化資料:指具有固定格式或有限長度的資料,如資料庫,元資料等。
非結構化資料:指不定長或無固定格式的資料,如郵件,word文件等磁碟上的檔案
1.2 非結構化資料查詢方法
1.2.1順序掃描法(Serial Scanning)
所謂順序掃描,比如要找內容包含某一個字串的檔案,就是一個文件一個文件的看,對於每一個文件,從頭看到尾,如果此文件包含此字串,則此文件為我們要找的檔案,接著看下一個檔案,直到掃描完所有的檔案。如利用
1.2.2 全文檢索(Full-text Search)
將非結構化資料中的一部分資訊提取出來,重新組織,使其變得有一定結構,然後對此有一定結構的資料進行搜尋,從而達到搜尋相對較快的目的。這部分從非結構化資料中提取出的然後重新組織的資訊,我們稱之索引。
例如:字典。字典的拼音表和部首檢字表就相當於字典的索引,對每一個字的解釋是非結構化的,如果字典沒有音節表和部首檢字表,在茫茫辭海中找一個字只能順序掃描。然而字的某些資訊可以提取出來進行結構化處理,比如讀音,就比較結構化,分聲母和韻母,分別只有幾種可以一一列舉,於是將讀音拿出來按一定的順序排列,每一項讀音都指向此字的詳細解釋的頁數。我們搜尋時按結構化的拼音搜到讀音,然後按其指向的頁數,便可找到我們的非結構化資料
這種先建立索引,再對索引進行搜尋的過程就叫全文檢索(Full-text Search)。
1.3如何實現全文檢索
可以使用Lucene實現全文檢索。Lucene是apache下的一個開放原始碼的全文檢索引擎工具包。提供了完整的查詢引擎和索引引擎,部分文字分析引擎。Lucene的目的是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實現全文檢索的功能。
1.4 全文檢索的應用場景
對於資料量大、資料結構不固定的資料可採用全文檢索方式搜尋,比如百度、Google等搜尋引擎、論壇站內搜尋、電商網站站內搜尋等。
(1)網際網路全文檢索引擎(比如百度, 谷歌, 必應)
(2)站內全文檢索引擎(淘寶, 京東搜尋功能)
(3)優化資料庫查詢(因為資料庫中使用like關鍵字是全表掃描也就是順序掃描演算法,查詢慢)
2、Lucene shix實現全文檢索的流程
2.1 索引和搜尋的流程圖
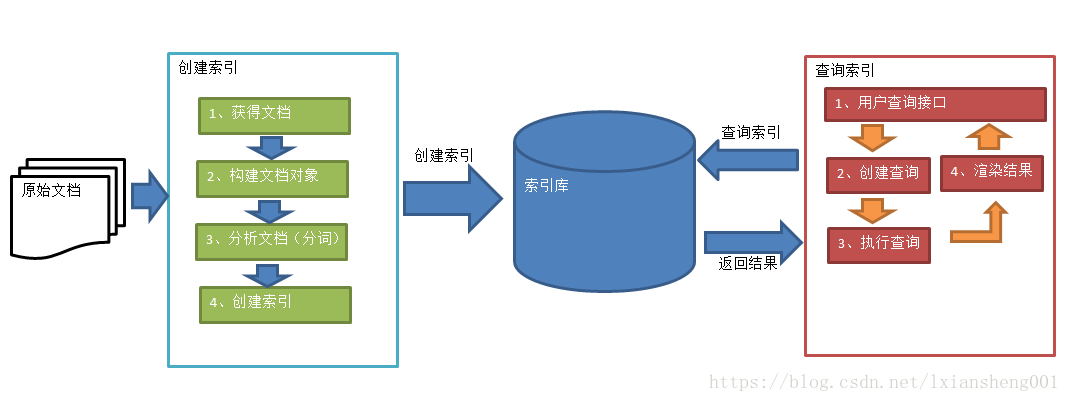
1、綠色表示索引過程,對要搜尋的原始內容進行索引構建一個索引庫,索引過程包括:
確定原始內容即要搜尋的內容-->採集文件--->建立文件--->分析文件--->索引文件
2、紅色表示搜尋過程,從索引庫中搜索內容,搜尋過程包括:
使用者通過搜尋介面--->建立查詢--->執行搜尋,從索引庫搜尋--->渲染搜尋結果
3、獲取原始wend文件
建立文件物件
分析文件
建立索引
2 Lucene 結構

2.3 索引
域名:詞 這樣的形式,
它裡面有指標執行這個詞來源的文件
索引庫: 放索引的資料夾(這個資料夾可以自己隨意建立,在裡面放索引就是索引庫)
Term詞元: 就是一個詞, 是lucene中詞的最小單位
2.4 wend文件
Document物件,一個Document中可以有多個Field域物件,Field域物件中是key value鍵值對的形式:有域名和域值,
一個document就是資料庫表中的一條記錄, 一個Filed域物件就是資料庫表中的一行一列
這是一個通用的儲存結構.
建立索引和所有時所用的分詞器必須一致
2.5 域的詳細介紹
是否分詞:
分詞的作用是為了索引
需要分詞: 檔名稱, 檔案內容
不需要分詞: 不需要索引的域不需要分詞,還有就是分詞後無意義的域不需要分詞
比如: id, 身份證號
是否索引:
索引的的目的是為了搜尋.
需要搜尋的域就一定要建立索引,只有建立了索引才能被搜尋出來
不需要搜尋的域可以不建立索引
需要索引: 檔名稱, 檔案內容, id, 身份證號等
不需要索引: 比如圖片地址不需要建立索引, e:\\xxx.jpg
因為根據圖片地址搜尋無意義
是否儲存:
儲存的目的是為了顯示.
是否儲存看個人需要,儲存就是將內容放入Document文件物件中儲存出來,會額外佔用磁碟空間, 如果搜尋的時候需要馬上顯示出來可以放入document中也就是要儲存,這樣查詢顯示速度快, 如果不是馬上立刻需要顯示出來,則不需要儲存,因為額外佔用磁碟空間不划算.
2.6 域的各種型別
|
Field類 |
資料型別 |
Analyzed 是否分析 |
Indexed 是否索引 |
Stored 是否儲存 |
說明 |
|
StringField(FieldName, FieldValue,Store.YES)) |
字串 |
N |
Y |
Y或N |
這個Field用來構建一個字串Field,但是不會進行分析,會將整個串儲存在索引中,比如(訂單號,姓名等) 是否儲存在文件中用Store.YES或Store.NO決定 |
|
LongField(FieldName, FieldValue,Store.YES) |
Long型 |
Y |
Y |
Y或N |
這個Field用來構建一個Long數字型Field,進行分析和索引,比如(價格) 是否儲存在文件中用Store.YES或Store.NO決定 |
|
StoredField(FieldName, FieldValue) |
過載方法,支援多種型別 |
N |
N |
Y |
這個Field用來構建不同型別Field 不分析,不索引,但要Field儲存在文件中 |
|
TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) |
字串 或 流 |
Y |
Y |
Y或N |
如果是一個Reader, lucene猜測內容比較多,會採用Unstored的策略. |
注意:lucene底層的演算法,錢數是要分詞的,因為要根據價錢進行對比
例如: 大於12.5元的小於100元的商品搜尋出來
3、 索引庫的維護
3.1 索引庫的新增
3.2 索引庫的修改
3.3 索引庫的刪除
4、 索引庫的查詢(重點)
4.1 使用query的子類查詢
4.1.1 termQuery
4.1.2 BumericRangeQuery
4.1.3 BooleanQuery
4.1.4 MatchAllDocsQuery
4.2 使用queryparser查詢
4.2.1 QueryParser
4.2.2 MultiFieldQueryParser