Python 三種網頁抓取方法
阿新 • • 發佈:2019-01-28
摘要:本文講的是利用Python實現網頁資料抓取的三種方法;分別為正則表示式(re)、BeautifulSoup模組和lxml模組。本文所有程式碼均是在python3.5中執行的。
本文抓取的是[中央氣象臺](http://www.nmc.cn/)首頁頭條資訊:
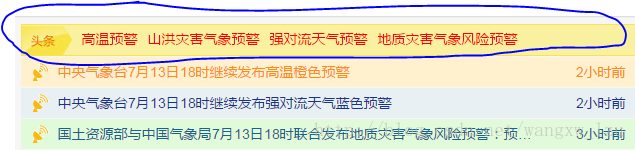
其HTML層次結構為:

抓取其中href、title和標籤的內容。
一、正則表示式
copy outerHTML:
<a target="_blank" href="/publish/country/warning/megatemperature.html" title="中央氣象臺7月13日18時繼續釋出高溫橙色預警" 程式碼:
# coding=utf-8
import re, urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
html = html.decode('utf-8') #python3版本中需要加入
links = re.findall('<a target="_blank" href="(.+?)" title',html)
titles = re.findall('<a target="_blank" .+? title="(.+?)">' 正則表示式符號’.’表示匹配任何字串(除\n之外);‘+’表示匹配0次或者多次前面出現的正則表示式;‘?’表示匹配0次或者1次前面出現的正則表示式。更多內容可以參考Python中的正則表示式教程
輸出結果如下:
高溫預警 http://www.nmc.cn/publish/country/warning/megatemperature.html 二、BeautifulSoup 模組
Beautiful Soup是一個非常流行的Python模組。該模組可以解析網頁,並提供定位內容的便捷介面。
copy selector:
#alarmtip > ul > li.waring > a:nth-child(1)因為這裡我們抓取的是多個數據,不單單是第一條,所以需要改成:
#alarmtip > ul > li.waring > a程式碼:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)輸出結果同上。
三、lxml 模組
Lxml是基於libxml2這一XML解析庫的Python封裝。該模組使用C語言編寫,解析速度比Beautiful Soup更快,不過安裝過程也更為複雜。
程式碼:
import urllib.request,lxml.html
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
tree = lxml.html.fromstring(html)
content = tree.cssselect('li.waring > a')
for n in content:
link = n.get('href')
title = n.get('title')
tag = n.text
print(tag, url + link, title)輸出結果同上。
四、將抓取的資料儲存到列表或者字典中
以BeautifulSoup 模組為例:
from bs4 import BeautifulSoup
import urllib.request
url = 'http://www.nmc.cn'
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'lxml')
content = soup.select('#alarmtip > ul > li.waring > a')
######### 新增到列表中
link = []
title = []
tag = []
for n in content:
link.append(url+n.get('href'))
title.append(n.get('title'))
tag.append(n.text)
######## 新增到字典中
for n in content:
data = {
'tag' : n.text,
'link' : url+n.get('href'),
'title' : n.get('title')
}五、總結
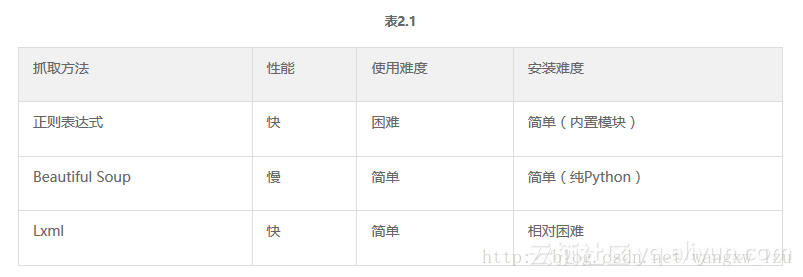
表2.1總結了每種抓取方法的優缺點。