
Tensorflow學習筆記(7)——CNN識別mnist程式設計實現
阿新 • • 發佈:2019-01-28
1.卷積神經網路構成(CNN)
卷積神經網路主要由卷積層和pooling層組成。
(1)卷積層
在CNN中的卷積層和普通神經網路的區別:
根據生物學上動物視覺上識別事物是通過區域性感知野的啟發,普通神經網路是下一層的神經元與本層神經元之間是全連結的,而卷積神經網路的下一層神經元只與本層的部分神經元之間有連結。
如下圖所示
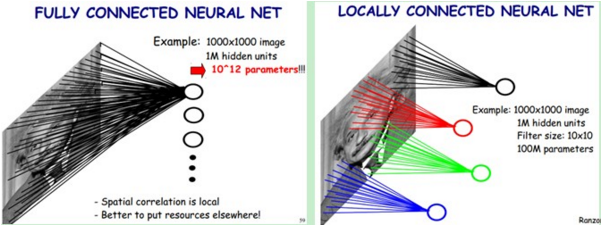
這樣能夠極大的減少連結數,即極大的減少網路的引數。
由於影象的不變形,即影象中任意區域的統計特性都是相似的特點,我們用同一個模板對影象進行卷積得到的結果即為該卷積模板對整幅影象的提取特徵。因此最終我們訓練需要的引數只有模板大小(若模板為10*10,且卷積模板只有一個時,則該層只需要100個引數)
(2)Down-pooling層
該層又被稱作池化操作、下采樣層。
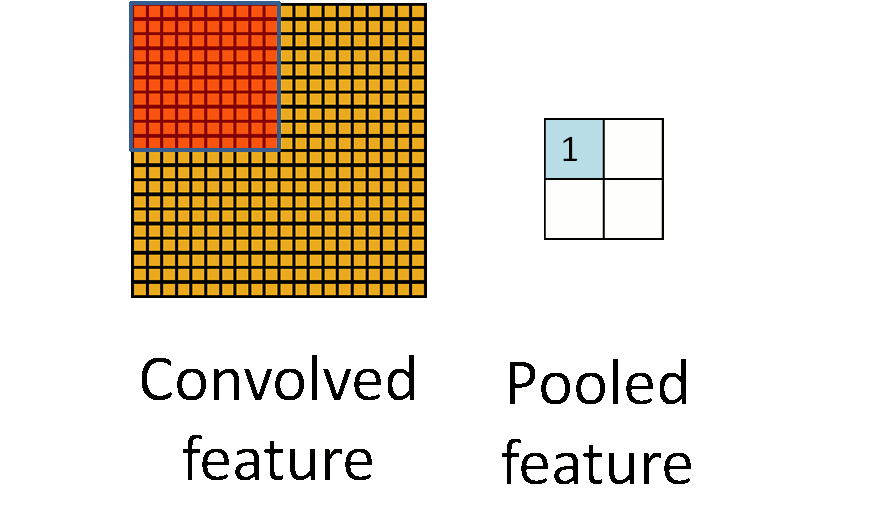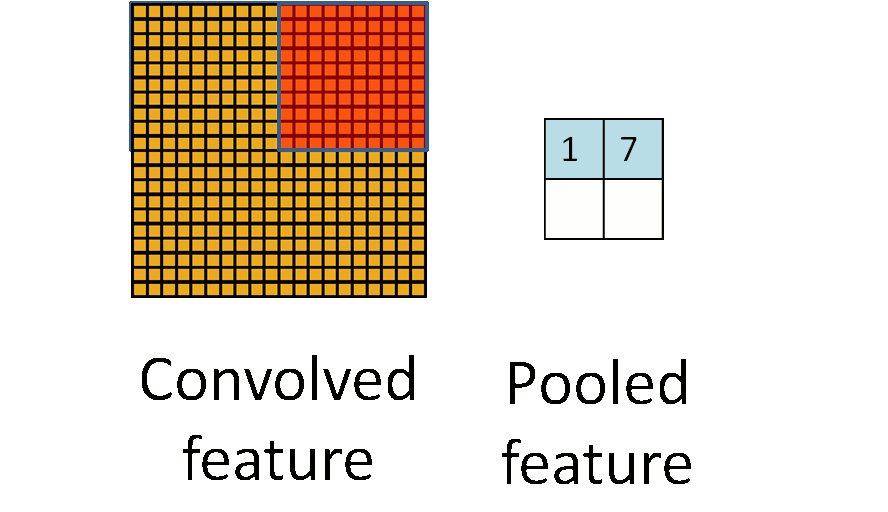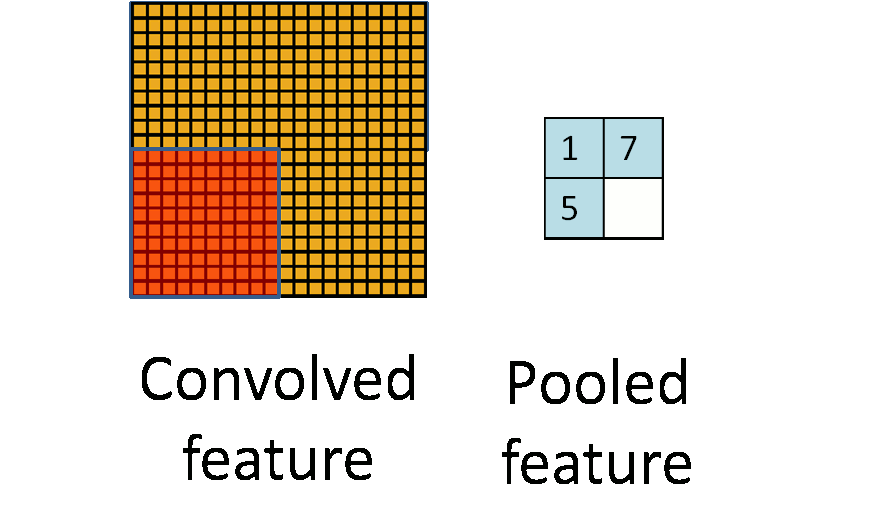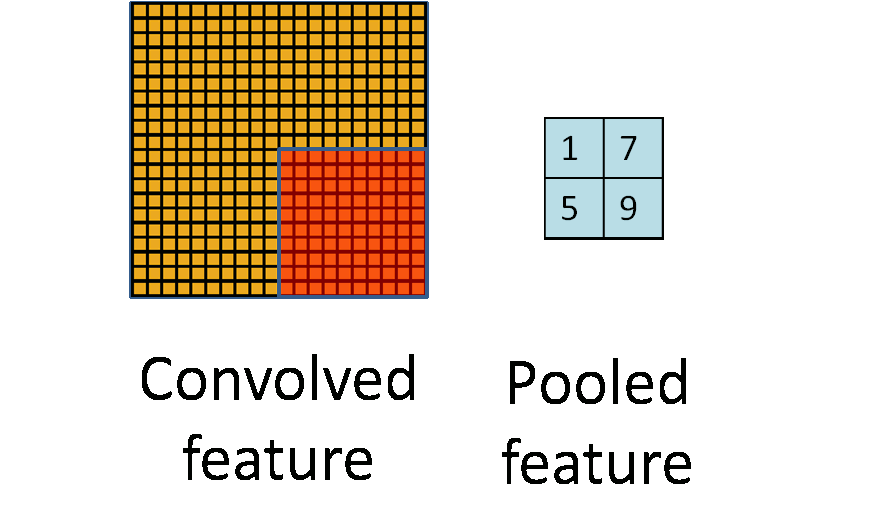
由於模板(即卷積核)在影象上進行平移,由於步長(stride)不會特別大,因此卷積得到的結果仍然會有很多的冗餘,因此需要進行pooling操作,pooling操作的形式化表示如下圖所示:
2.Tensorflow實現mnist手寫體識別演算法
具體分析已經寫在程式碼註釋中。
下面是訓練的程式碼:
#coding=utf-8
'''
Created on 2016-5-17
訓練了一個卷積神經網路,用以識別mnist資料庫
batch_size為50,迴圈執行共2000個batch,最終訓練集上測試正確率在90%
@author: hanchao
''' 下面是測試部分的程式碼:
#coding=utf-8
'''
Created on 2016-5-17
在上面訓練的網路基礎上在測試集上進行測試,提取前100個測試圖片,正確率在95%
@author: hanchao
'''
import input_data
mnist = input_data.read_data_sets('/home/hanchao/mnist', one_hot=True)
import tensorflow as tf
#構建網路部分,與訓練過程構建網路部分相同
……………
#構建網路部分,與訓練過程構建網路部分相同
#可以直接匯入train中的函式進行使用
saver = tf.train.Saver()
with tf.Session() as sess:
#讀取上面訓練好的模型引數
saver.restore(sess, '/home/hanchao/hanchaoNet.netmodel-1990')
print 'Testing accary: ',sess.run(correct_rate,feed_dict={x:mnist.test.images[:100],y:mnist.test.labels[:100],dropoutP:1.})