
Lucene 原始碼剖析 二 索引檔案結構(1)
2 索引檔案
為了使用Lucene來索引資料,首先你得把它轉換成一個純文字(plain-text)tokens的資料流(stream),並通過它創建出Document物件,其包含的Fields成員容納這些文字資料。一旦你準備好些Document物件,你就可以呼叫IndexWriter類的addDocument(Document)方法來傳遞這些物件到Lucene並寫入索引中。當你做這些的時候,Lucene首先分析(analyzer)這些資料來使得它們更適合索引。詳見《Lucene In Action》
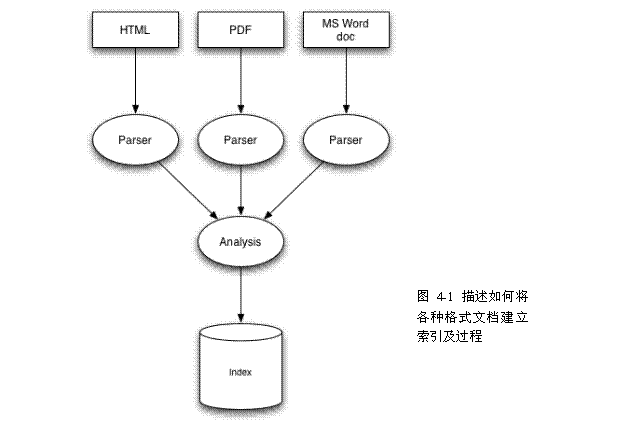
下面先了解一下索引結構的一些術語。
2.1
2.1.1 術語定義
Lucene中基本的概念(fundamental concepts)是index、Document、Field和term。
1 一條索引(index)包含(contains)了一連串(a sequence of)文件(documents)。
2 一個文件(document)是由一連串fields組成。
3 一個field是由一連串命名了(a named sequence of)的terms組成。
4 一個term是一個string(字串)。
相同的字串(same string)但是在兩個不同的fields中被認為(considered
2.1.2 倒排索引(inverted indexing)
索引(index)儲存terms的統計資料(statistics about terms),為了使得基於term的檢索(term-based search)效率更高(more efficient)。Lucene的索引分成(fall into)被廣為熟悉的(
2.1.3 Fields的種類
在Lucene中,fields可以被儲存(stored),在這種情況(in which case)下它們的文字被逐字地(literally)以一種非倒排的方式(in non-inverted manner)儲存進index中。那些被倒排的fields(that are inverted)稱為(called)被索引(indexed)。一個field可以都被儲存(stored)並且被索引(indexed)。
一個field的文字可以被分解為(be tokenized into)terms以便被索引(indexed),或者field的文字可以被逐字地使用為(used literally as)一個term來被索引(be indexed)。大多數fields被分解(be tokenized),但是有時候對某種唯一性(certain identifier)的field來逐字地索引(be indexed literally)又是非常有用的,如url。
2.1.4 片斷(segments)
Lucene的索引可以由多個複合的子索引(multiple sub-indexes)或者片斷(segments)組成(be composed of)。每一個segment都是一個完全獨立的索引(fully independent index),它能夠被分離地進行檢索(be searched seperately)。索引按如下方式進行演化(evolve):
1. 為新新增的文件(newly added documents)建立新的片斷(segments)。
2. 合併已存在的片斷(merging existing segments)。
檢索可以涉及(involve)多個複合(multiple)的segments,並且/或者多個複合(multiple)的indexes。每一個index潛在地(potentially)包含(composed of)一套(a set of)segments。
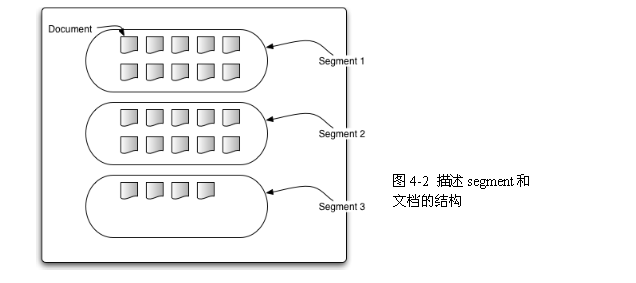
2.1.5 文件編號(document numbers)
在內部(internally),Lucene通過一個整數的(interger)文件編號(document number)來表示文件。第一篇被新增到索引中的文件編號為0(be numbered zero),每一篇隨後(subsequent)被新增的document獲得一個比前一篇更大的數字(a number one greater than the previous)。
需要注意的是一篇文件的編號(document’s number)可以更改,所以在Lucene之外(outside of)儲存這些編號時需要特別小心(caution should be taken)。詳細地說(in particular),編號在如下的情況(following situations)可以更改:
1 儲存在每個segment中的編號僅僅是在所在的segment中是唯一的(unique),在它能夠被使用在(be used in)一個更大的上下文(a larger context)中前必須被轉變(converted)。標準的技術(standard technique)是給每一個segment分配(allocate)一個範圍的值(a range of values),基於該segment所使用的編號的範圍(the range of numbers)。為了將一篇文件的編號從一個segment轉變為一個擴充套件的值(an external value),該片斷的基礎的文件編號(base document number)被新增(is added)。為了將一個擴充套件的值(external value)轉變回一個segment的特定的值(specific value),該segment將該擴充套件的值所在的範圍標識出來(be indentified),並且該segment的基礎值(base value)將被減少(substracted)。例如,兩個包含5篇文件的segments可能會被合併(combined),所以第一個segment有一個基礎的值(base value)為0,第二個segment則為5。在第二個segment中的第3篇文件(document three from the second segment)將有一個擴充套件的值為8。
2 當文件被刪除的時候,在編號序列中(in the numbering)將產生(created)間隔段(gaps)。這些最後(eventually)在索引通過合併演進時(index evolves through merging)將會被清除(removed)。當segments被合併後(merged),已刪除的文件將會被丟棄(dropped),一個剛被合併的(freshly-merged)segment因此在它的編號序列中(in its numbering)不再有間隔段(gaps)。
2.1.6 索引結構概述
每一個片斷的索引(segment index)管理(maintains)如下的資料:
1 Fields名稱:這包含了(contains)在索引中使用的一系列fields的名稱(the set of field names)。
2 已儲存的field的值:它包含了,對每篇文件來說,一個屬性-值資料對(attribute-value pairs)的清單(a list of),其中屬性即為field的名字。這些被用來儲存關於文件的備用資訊(auxiliary information),比如它的標題(title)、url、或者一個訪問一個數據庫(database)的唯一標識(identifier)。這套儲存的fields就是那些在檢索時對每一個命中的(hits)文件所返回的(returned)資訊。這些是通過文件編號(document number)來做為key得到的。
3 Term字典(dictionary):一個包含(contains)所有terms的字典,被使用在所有文件中所有被索引的fields中。它還包含了該term所在的文件的數目(the number of documents which contains the term),並且指向了(pointer to)term的頻率(frequency)和接近度(proximity)的資料(data)。
4 Term頻率資料(frequency data):對字典中的每一個term來說,所有包含該term(contains the term)的文件的編號(numbers of all documents),以及該term出現在該文件中的頻率(frequency)。
5 Term接近度資料(proximity data):對字典中的每一個term來說,該term出現在(occur)每一篇文件中的位置(positions)。
6 調整因子(normalization factors):對每一篇文件的每一個field來說,為一個儲存的值(a value is stored)用來加入到(multiply into)命中該field的分數(score for hits on that field)中。
7 Term向量(vectors):對每一篇文件的每一個field來說,term向量(有時候被稱做文件向量)可以被儲存。一個term向量由term文字和term的頻率(frequency)組成(consists of)。怎麼新增term向量到你的索引中請參考Field類的構造方法(constructors)。
8 刪除的文件(deleted documents):一個可選的(optional)檔案標示(indicating)哪一篇文件被刪除。
關於這些項的詳細資訊在隨後的章節(subsequent sections)中逐一介紹。
2.1.7 索引檔案中定義的資料型別
|
資料型別 |
所佔位元組長度(位元組) |
說明 |
|||||||||||||||||||||||||||||||||
|
Byte |
1 |
基本資料型別,其他資料型別以此為基礎定義 |
|||||||||||||||||||||||||||||||||
|
UInt32 |
4 |
32位無符號整數,高位優先 |
|||||||||||||||||||||||||||||||||
|
UInt64 |
8 |
64位無符號整數,高位優先 |
|||||||||||||||||||||||||||||||||
|
VInt |
不定,最少1位元組 |
動態長度整數,每位元組的最高位表明還剩多少位元組,每位元組的低七位表明整數的值,高位優先。可以認為值可以為無限大。其示例如下
|
|||||||||||||||||||||||||||||||||
|
Chars |
不定,最少1位元組 |
採用UTF-8編碼[20]的Unicode字元序列 |
|||||||||||||||||||||||||||||||||
|
String |
不定,最少2位元組 |
由VInt和Chars組成的字串型別,VInt表示Chars的長度,Chars則表示了String的值 |
3.1索引檔案結構
Lucene使用副檔名標識不同的索引檔案,檔名標識不同版本或者代(generation)的索引片段(segment)。如.fnm檔案儲存域Fields名稱及其屬性,.fdt儲存文件各項域資料,.fdx儲存文件在fdt中的偏移位置即其索引檔案,.frq儲存文件中term位置資料,.tii檔案儲存term字典,.tis檔案儲存term頻率資料,.prx儲存term接近度資料,.nrm儲存調節因子資料,另外segments_X檔案儲存當前最新索引片段的資訊,其中X為其最新修改版本,segments.gen儲存當前版本即X值,這些檔案的詳細介紹上節已說過了。
下面的圖描述了一個典型的lucene索引檔案列表:
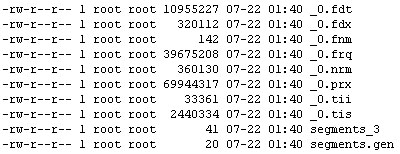
如果將它們的關係劃成圖則如下所示
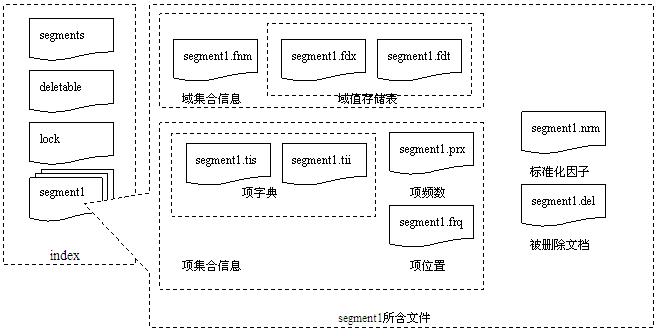
這些檔案中儲存資料的詳細結構是怎樣的呢,下面幾個小節逐一介紹它們,熟悉它們的結構非常有助於優化Lucene的查詢和索引效率和儲存空間等。
3.2 每個Index包含的單個檔案
下面幾節介紹的檔案存在於每個索引index中,並且只有一份。
3.2.1Segments檔案
索引中活動(active)的Segments被儲存在segment info檔案中,segments_N,在索引中可能會包含一個或多個segments_N檔案。然而,最大一代的那個檔案(the one with largest generation)是活動的片斷檔案(這時更舊的segments_N檔案依然存在(are present)是因為它們暫時(temporarily)還不能被刪除,或者,一個writer正在處理提交請求(in the process of committing),或者一個使用者定義的(custom)IndexDeletionPolicy正被使用)。這個檔案按照名稱列舉每一個片斷(lists each segment by name),詳細描述分離的標準(seperate norm)和要刪除的檔案(deletion files),並且還包含了每一個片斷的大小。
對2.1版本來說,還有一個檔案segments.gen。這個檔案包含了該索引中當前生成的代(current generation)(segments_N中的_N)。這個檔案僅用於一個後退處理(fallback)以防止(in case)當前代(current generation)不能被準確地(accurately)通過單獨地目錄檔案列舉(by directory listing alone)來確定(determened)(由於某些NFS客戶端因為基於時間的目錄(time-based directory)的快取終止(cache expiration)而引起)。這個檔案簡單地包含了一個int32的版本頭(version header)(SegmentInfos.FORMAT_LOCKLESS=-2),遵照代的記錄(followed by the generation recorded)規則,對int64來說會寫兩次(write twice)。
|
版本 |
包含的項 |
數目 |
型別 |
描述 |
|
2.1之前版本 |
Format |
1 |
Int32 |
在Lucene1.4中為-1,而在Lucene 2.1中為-3(SegmentsInfos.FORMAT_SINGLE_NORM_FILE) |
|
Version |
1 |
Int64 |
統計在刪除和新增文件時,索引被更改了多少次。 |
|
|
NameCounter |
1 |
Int32 |
用於為新的片斷檔案生成新的名字。 |
|
|
SegCount |
1 |
Int32 |
片斷的數目 |
|
|
SegName |
SegCount |
String |
片斷的名字,用於所有構成片斷索引的檔案的檔名字首。 |
|
|
SegSize |
SegCount |
Int32 |
包含在片斷索引中的文件的數目。 |
|
|
2.1及之後版本 |
Format |
1 |
Int32 |
在Lucene 2.1和Lucene 2.2中為-3(SegmentsInfos.FORMAT_SINGLE_NORM_FILE) |
|
Version |
1 |
Int64 |
同上 |
|
|
NameCounter |
1 |
Int32 |
同上 |
|
|
SegCount |
1 |
Int32 |
同上 |
|
|
SegName |
SegCount |
String |
同上 |
|
|
SegSize |
SegCount |
Int32 |
同上 |
|
|
DelGen |
SegCount |
Int64 |
為分離的刪除檔案的代的數目(generation count of the separate deletes file),如果值為-1,表示沒有分離的刪除檔案。如果值為0,表示這是一個
2 索引檔案
為了使用Lucene來索引資料,首先你得把它轉換成一個純文字(plain-text)tokens的資料流(stream),並通過它創建出Document物件,其包含的Fields成員容納這些文字資料。一旦你準備好些Document物件,你就
Lucene的索引結構是有層次結構。
每個層次都儲存了本層次的資訊以及下一層次的元資訊。
1) 索引Index
在Lucene中,一個索引是放在一個資料夾中的
2) 段Segment
一個索引可以包含多個段,段與段之間是獨立的。
新增新文件可以生成新的段,不同的段
一、codis-proxy啟動http服務接受叢集命令
func newApiServer(p *Proxy) http.Handler {
m := martini.New() //go-martini web開發框架
1,nginx的記憶體池介紹
為了方便系統模組對記憶體的使用,方便記憶體的管理,nginx自己實現了程序池的機制來進行記憶體的分配和釋放, 首先nginx會在特定的生命週期幫你
統一建立記憶體池,當需要進行記憶體分配的時候統一通過記憶體池中的記憶體進行分配,最
4索引是如何建立的
為了使用Lucene來索引資料,首先你比把它轉換成一個純文字(plain-text)tokens的資料流(stream),並通過它創建出Document物件,其包含的Fields成員容納這些文字資料。一旦你準備好些Document物件,你就可以呼叫Inde
平臺:Android 4.4.2
原始碼路徑:/system/core/mkbootimg
/*
** +-----------------+
** | boot header | 1 page
** +-----------------+
** | kernel
6.5 讀取sstable檔案
6.5.1 類層次
Sstable檔案的讀取邏輯在類Table中,其中涉及到的類還是比較多的,如圖6.5-1所示。
圖6.5-1
Table類匯出的函式只有3個,先從這三個匯出函式開始分析。其中涉及到的類(包括上圖中
一、FileInputStream
在FileInputStream中,首先我們需要進行關注的方法,就是read()方法,下面可以來看一下read()方法的原始碼:
public int read() throws IOException {
return read0()
Redis Cluster 通訊流程深入剖析
1. Redis Cluster 介紹和搭建
這篇部落格會介紹Redis Cluster的資料分割槽理論和一個三主三從叢集的搭建。
2. Redis Cluster 和 Redis Sentin 回過頭來看看我們的詞典tis,一個詞項在tis中記錄為一個TermInfo結構,而這個結構裡有一個FreqDelta欄位,通過在它之前的TermInfo,能夠加和間距得到這個Term的詞頻倒排在.frq檔案中的起始地址;然後注意到TermInfo還有一個欄位SkipDelta,能夠通過它得到這
ByteBuf
ByteBuf是Netty提供的代替jdk的ByteBuffer的一個容器,首先看一下他的具體用法:
public class ByteBufTest0 {
public static void main(String[] args) {
前文地址:https://www.cnblogs.com/tera/p/13267630.html
本系列文章主要是博主在學習spring aop的過程中瞭解到其使用了java動態代理,本著究根問底的態度,於是對java動態代理的本質原理做了一些研究,於是便有了這個系列的文章
接上文,我們需要了 最短 gpo 最大 node 優先 blog nod 特殊 OS 第7章,神奇的樹。第一節,樹的特點。 第二節,二叉樹。 第三節,優先隊列--堆(特殊的完全二叉樹) 最小堆:All node-father smaller than node-sons 最大堆:
今天花了一整天時間進行閱讀和除錯Caffe框架程式碼,單單是以Lenet網路進行測試就可見框架的大致工作原理。賈揚清在Caffe中大量使用了STL、模板、智慧指標,有些地方為了效率也犧牲了一些程式碼可讀性,處處彰顯了大牛風範。為了他人閱讀方便,現將程式碼流程簡單梳理一下。
1.LeNe
客官您終於回頭了!讓我們本著探(zuo)索(si)精神把 session.py 看完吧...
首先看看需要的庫:
pickle 一個用於序列化反序列化的庫(聽
Java編譯(二)Java前端編譯:
Java原始碼編譯成Class檔案的過程
在上篇文章《Java三種編譯方式:前端編
地址:https://www.cnblogs.com/nuanxin/p/8032743.html
Ecshop檔案結構 ecshop檔案架構說明 /* ECShop 2.5.1 的結構圖及各檔案相應功能介紹 ECShop2.5.1_Beta upload 的目
在讀HDFS檔案前,需要先open該檔案,這個呼叫的是org.apache.hadoop.fs.FileSystem類物件,但是由於實際建立的物件是org.apache.hadoop.hdfs.DistributedFileSystem類物件,後者是前者的子類,所以呼叫父類中的FSDataInput
轉載https://www.imooc.com/article/details/id/23015
與HashMap的區別
1 HashMap是非同步的,沒有對讀寫等操作進行鎖保護,所以是執行緒不安全的,在多執行緒場景下會出現資料不一致的問題。而HashTable是同步的,所有的讀寫等操作都進
歡迎大家來訪二笙的小房子,一同學習分享生活!
文章目錄
1. 寫在前面
2. SGI空間配置器
2.1 SGI標準空間配置器
2.2 SGI特殊的空間配置器,std::alloc
2.3 構造和析構基本工具
2.4 空間 |