
分類、迴歸、聚類、降維的區別
機器學習的類別
機器學習分為四大塊,如下圖所示,分別是:
classification (分類),regression (迴歸), clustering (聚類), dimensionality reduction (降維)。
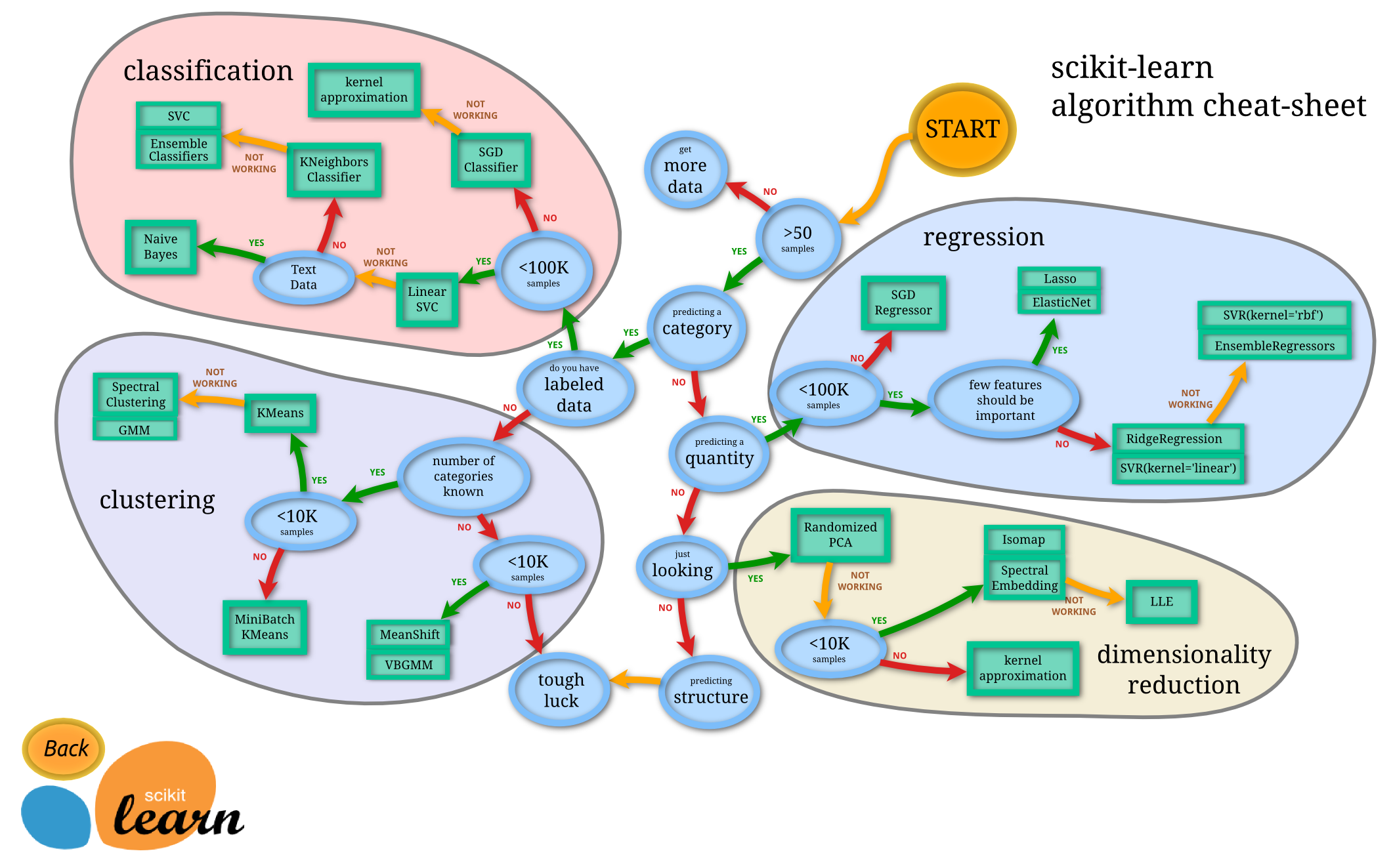
區分方式
給定一個樣本特徵 , 我們希望預測其對應的屬性值 , 如果 是離散的, 那麼這就是一個分類問題,反之,如果 是連續的實數, 這就是一個迴歸問題。
給定一組樣本特徵, 我們沒有對應的屬性值 , 而是想發掘這組樣本在多維空間的分佈, 比如分析哪些樣本靠的更近,哪些樣本之間離得很遠, 這就是屬於聚類問題。
如果我們想用維數更低的子空間來表示原來高維的特徵空間
詳解
1.classification & regression
無論是分類還是迴歸,都是想建立一個預測模型 ,給定一個輸入 , 可以得到一個輸出;不同的只是在分類問題中,預測結果是離散的; 而在迴歸問題中預測結果是連續的。所以總得來說,兩種問題的學習演算法都很類似。所以在這個圖譜上,我們看到在分類問題中用到的學習演算法,在迴歸問題中也能使用。分類問題最常用的學習演算法包括 SVM (支援向量機) , SGD (隨機梯度下降演算法), Bayes (貝葉斯估計), Ensemble(整合), KNN 等。而迴歸問題也能使用 SVR, SGD, Ensemble 等算
2.clustering
聚類也是分析樣本的屬性, 有點類似classification, 不同的就是classification 在預測之前是知道結果屬性的範圍, 或者說知道到底有幾個類別, 而聚類是不知道屬性的範圍的。所以classification 也常常被稱為 supervised learning, 而clustering就被稱為unsupervised learning。
clustering 事先不知道樣本的屬性範圍,只能憑藉樣本在特徵空間的分佈來分析樣本的屬性。這種問題一般更復雜。而常用的演算法包括 k-means (K-均值), GMM (高斯混合模型) 等。
3.dimensionality reduction
降維是機器學習另一個重要的領域, 降維有很多重要的應用, 特徵的維數過高, 會增加訓練的負擔與儲存空間, 降維就是希望去除特徵的冗餘, 用更加少的維數來表示特徵.降維演算法最基礎的就是PCA了, 後面的很多演算法都是以PCA為基礎演化而來。