Redis複製與可擴充套件叢集搭建
Redis複製流程概述
Redis的複製功能是完全建立在之前我們討論過的基於記憶體快照的持久化策略基礎上的,也就是說無論你的持久化策略選擇的是什麼,只要用到了Redis的複製功能,就一定會有記憶體快照發生,那麼首先要注意你的系統記憶體容量規劃,原因可參見文章最後一節的“Redis持久化磁碟IO方式及其帶來的問題”。
Redis複製流程在Slave和Master端各自是一套狀態機流轉,涉及的狀態資訊是:
Slave 端: REDIS_REPL_NONE REDIS_REPL_CONNECT REDIS_REPL_CONNECTED Master端: REDIS_REPL_WAIT_BGSAVE_START REDIS_REPL_WAIT_BGSAVE_END REDIS_REPL_SEND_BULK REDIS_REPL_ONLINE
整個狀態機流程過程如下:
Slave端在配置檔案中添加了slave of指令,於是Slave啟動時讀取配置檔案,初始狀態為REDIS_REPL_CONNECT。
Slave端在定時任務serverCron(Redis內部的定時器觸發事件)中連線Master,傳送sync命令,然後阻塞等待master傳送回其記憶體快照檔案(最新版的Redis已經不需要讓Slave阻塞)。
Master端收到sync命令簡單判斷是否有正在進行的記憶體快照子程序,沒有則立即開始記憶體快照,有則等待其結束,當快照完成後會將該檔案傳送給Slave端。
Slave端接收Master發來的記憶體快照檔案,儲存到本地,待接收完成後,清空記憶體表,重新讀取Master發來的記憶體快照檔案,重建整個記憶體表資料結構,並最終狀態置位為 REDIS_REPL_CONNECTED狀態,Slave狀態機流轉完成。
Master端在傳送快照檔案過程中,接收的任何會改變資料集的命令都會暫時先儲存在Slave網路連線的傳送快取佇列裡(list資料結構),待快照完成後,依次發給Slave,之後收到的命令相同處理,並將狀態置位為 REDIS_REPL_ONLINE。
整個複製過程完成,流程如下圖所示:

Redis複製機制的缺陷
從上面的流程可以看出,Slave從庫在連線Master主庫時,Master會進行記憶體快照,然後把整個快照檔案發給Slave,也就是沒有象MySQL那樣有複製位置的概念,即無增量複製,這會給整個叢集搭建帶來非常多的問題。
比如一臺線上正在執行的Master主庫配置了一臺從庫進行簡單讀寫分離,這時Slave由於網路或者其它原因與Master斷開了連線,那麼當Slave進行重新連線時,需要重新獲取整個Master的記憶體快照,Slave所有資料跟著全部清除,然後重新建立整個記憶體表,一方面Slave恢復的時間會非常慢,另一方面也會給主庫帶來壓力。
所以基於上述原因,如果你的Redis叢集需要主從複製,那麼最好事先配置好所有的從庫,避免中途再去增加從庫。
Cache還是Storage
在我們分析過了Redis的複製與持久化功能後,我們不難得出一個結論,實際上Redis目前釋出的版本還都是一個單機版的思路,主要的問題集中在,持久化方式不夠成熟,複製機制存在比較大的缺陷,這時我們又開始重新思考Redis的定位:Cache還是Storage?
如果作為Cache的話,似乎除了有些非常特殊的業務場景,必須要使用Redis的某種資料結構之外,我們使用Memcached可能更合適,畢竟Memcached無論客戶端包和伺服器本身更久經考驗。
如果是作為儲存Storage的話,我們面臨的最大的問題是無論是持久化還是複製都沒有辦法解決Redis單點問題,即一臺Redis掛掉了,沒有太好的辦法能夠快速的恢復,通常幾十G的持久化資料,Redis重啟載入需要幾個小時的時間,而複製又有缺陷,如何解決呢?
Redis可擴充套件叢集搭建
1. 主動複製避開Redis複製缺陷。
既然Redis的複製功能有缺陷,那麼我們不妨放棄Redis本身提供的複製功能,我們可以採用主動複製的方式來搭建我們的叢集環境。
所謂主動複製是指由業務端或者通過代理中介軟體對Redis儲存的資料進行雙寫或多寫,通過資料的多份儲存來達到與複製相同的目的,主動複製不僅限於用在Redis叢集上,目前很多公司採用主動複製的技術來解決MySQL主從之間複製的延遲問題,比如Twitter還專門開發了用於複製和分割槽的中介軟體gizzard(https://github.com/twitter/gizzard) 。
主動複製雖然解決了被動複製的延遲問題,但也帶來了新的問題,就是資料的一致性問題,資料寫2次或多次,如何保證多份資料的一致性呢?如果你的應用對資料一致性要求不高,允許最終一致性的話,那麼通常簡單的解決方案是可以通過時間戳或者vector clock等方式,讓客戶端同時取到多份資料並進行校驗,如果你的應用對資料一致性要求非常高,那麼就需要引入一些複雜的一致性演算法比如Paxos來保證資料的一致性,但是寫入效能也會相應下降很多。
通過主動複製,資料多份儲存我們也就不再擔心Redis單點故障的問題了,如果一組Redis叢集掛掉,我們可以讓業務快速切換到另一組Redis上,降低業務風險。
2. 通過presharding進行Redis線上擴容。
通過主動複製我們解決了Redis單點故障問題,那麼還有一個重要的問題需要解決:容量規劃與線上擴容問題。
我們前面分析過Redis的適用場景是全部資料儲存在記憶體中,而記憶體容量有限,那麼首先需要根據業務資料量進行初步的容量規劃,比如你的業務資料需要100G儲存空間,假設伺服器記憶體是48G,那麼根據上一篇我們討論的Redis磁碟IO的問題,我們大約需要3~4臺伺服器來儲存。這個實際是對現有業務情況所做的一個容量規劃,假如業務增長很快,很快就會發現當前的容量已經不夠了,Redis裡面儲存的資料很快就會超過實體記憶體大小,那麼如何進行Redis的線上擴容呢?
Redis的作者提出了一種叫做presharding的方案來解決動態擴容和資料分割槽的問題,實際就是在同一臺機器上部署多個Redis例項的方式,當容量不夠時將多個例項拆分到不同的機器上,這樣實際就達到了擴容的效果。
拆分過程如下:
在新機器上啟動好對應埠的Redis例項。
配置新埠為待遷移埠的從庫。
待複製完成,與主庫完成同步後,切換所有客戶端配置到新的從庫的埠。
配置從庫為新的主庫。
移除老的埠例項。
重複上述過程遷移好所有的埠到指定伺服器上。
以上拆分流程是Redis作者提出的一個平滑遷移的過程,不過該拆分方法還是很依賴Redis本身的複製功能的,如果主庫快照資料檔案過大,這個複製的過程也會很久,同時會給主庫帶來壓力。所以做這個拆分的過程最好選擇為業務訪問低峰時段進行。
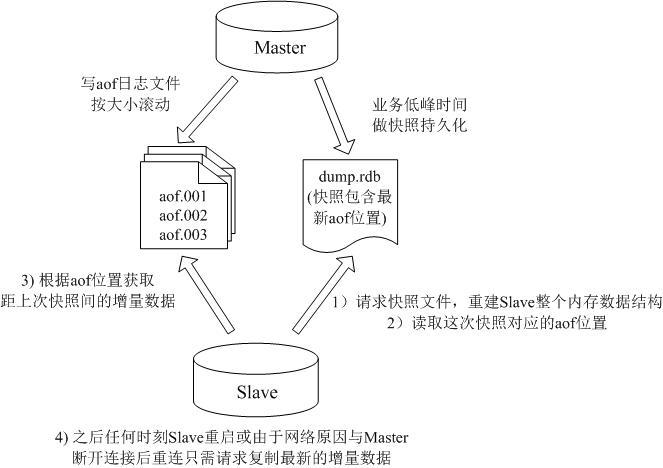
Redis複製的改進思路
我們線上的系統使用了我們自己改進版的Redis,主要解決了Redis沒有增量複製的缺陷,能夠完成類似Mysql Binlog那樣可以通過從庫請求日誌位置進行增量複製。
我們的持久化方案是首先寫Redis的AOF檔案,並對這個AOF檔案按檔案大小進行自動分割滾動,同時關閉Redis的Rewrite命令,然後會在業務低峰時間進行記憶體快照儲存,並把當前的AOF檔案位置一起寫入到快照檔案中,這樣我們可以使快照檔案與AOF檔案的位置保持一致性,這樣我們得到了系統某一時刻的記憶體快照,並且同時也能知道這一時刻對應的AOF檔案的位置,那麼當從庫傳送同步命令時,我們首先會把快照檔案傳送給從庫,然後從庫會取出該快照檔案中儲存的AOF檔案位置,並將該位置發給主庫,主庫會隨後傳送該位置之後的所有命令,以後的複製就都是這個位置之後的增量資訊了。
Redis與MySQL的結合
目前大部分網際網路公司使用MySQL作為資料的主要持久化儲存,那麼如何讓Redis與MySQL很好的結合在一起呢?我們主要使用了一種基於MySQL作為主庫,Redis作為高速資料查詢從庫的異構讀寫分離的方案。
為此我們專門開發了自己的MySQL複製工具,可以方便的實時同步MySQL中的資料到Redis上。
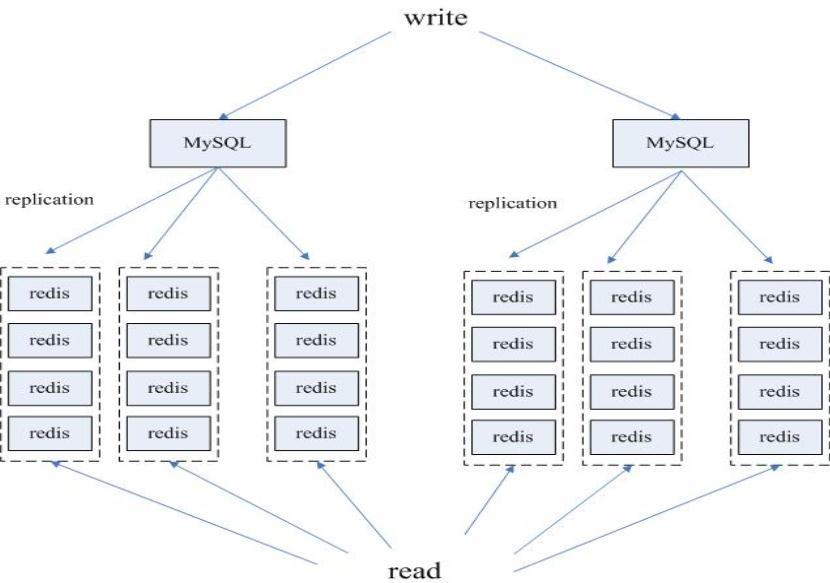
(MySQL-Redis 異構讀寫分離)
總結:
Redis的複製功能沒有增量複製,每次重連都會把主庫整個記憶體快照發給從庫,所以需要避免向線上服務的壓力較大的主庫上增加從庫。
Redis的複製由於會使用快照持久化方式,所以如果你的Redis持久化方式選擇的是日誌追加方式(aof),那麼系統有可能在同一時刻既做aof日誌檔案的同步刷寫磁碟,又做快照寫磁碟操作,這個時候Redis的響應能力會受到影響。所以如果選用aof持久化,則加從庫需要更加謹慎。
可以使用主動複製和presharding方法進行Redis叢集搭建與線上擴容。
Redis持久化磁碟IO方式及其帶來的問題
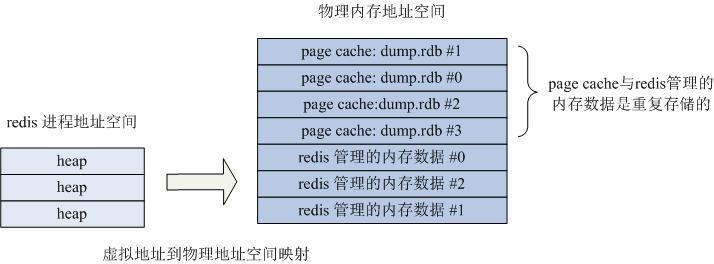
有Redis線上運維經驗的人會發現Redis在實體記憶體使用比較多,但還沒有超過實際實體記憶體總容量時就會發生不穩定甚至崩潰的問題,有人認為是基於快照方式持久化的fork系統呼叫造成記憶體佔用加倍而導致的,這種觀點是不準確的,因為fork 呼叫的copy-on-write機制是基於作業系統頁這個單位的,也就是隻有有寫入的髒頁會被複制,但是一般你的系統不會在短時間內所有的頁都發生了寫入而導致複製,那麼是什麼原因導致Redis崩潰的呢?
答案是Redis的持久化使用了Buffer IO造成的,所謂Buffer IO是指Redis對持久化檔案的寫入和讀取操作都會使用實體記憶體的Page Cache,而大多數資料庫系統會使用Direct IO來繞過這層Page Cache並自行維護一個數據的Cache,而當Redis的持久化檔案過大(尤其是快照檔案),並對其進行讀寫時,磁碟檔案中的資料都會被載入到實體記憶體中作為作業系統對該檔案的一層Cache,而這層Cache的資料與Redis記憶體中管理的資料實際是重複儲存的,雖然核心在實體記憶體緊張時會做Page Cache的剔除工作,但核心很可能認為某塊Page Cache更重要,而讓你的程序開始Swap ,這時你的系統就會開始出現不穩定或者崩潰了。我們的經驗是當你的Redis實體記憶體使用超過記憶體總容量的3/5時就會開始比較危險了。
下圖是Redis在讀取或者寫入快照檔案dump.rdb後的記憶體資料圖: