
Discuz驗證碼識別(編碼篇)-寫給程式設計師的TensorFlow教程
歡迎大家回到《寫給程式設計師的TensorFlow教程》系列中來,本系列希望能給廣大想轉型機器學習的程式設計師帶來一些不一樣的內容,我們不講公式,只調方法,不聊文獻,只說程式碼。不求最好,只求有用。帶大家迅速上手TensorFlow(以下簡稱TF。我是強迫症患者,每次都敲駝峰太累了)。
下面正式要開始了我們真正的TensorFlow程式設計,這篇文章主要內容分為兩部分,一部分是介紹TF的基礎知識和一些常用介面;第二部分是接著上節課的內容繼續執行我們的解題思路。
我們先進入第一部分
Part 1、TF基礎知識
雖然我們機器學習的基礎概念可以先不深究,但是TF還是得講一講的,不然咱們就算抄再多程式碼也是天書,完全達不到滲透法的學習目的,所以我們先給大家講一講TF的基本程式碼結構。
對於開發網頁或者移動應用來說,程式是沿著我們寫出來的程式碼邏輯一步一步執行的,因此我們一般都是可以在程式碼中任意地方插入print來列印我們需要了解的變數的值。但是在TF中卻不是這樣,TF中我們的程式碼一般會被分為兩個模組:
1.先預定義一張圖
注意:這個圖不是圖片的圖,而是一個節點之間相互連線的結構,為了能打擊大家的學習積極性,我先放一張簡單的圖給大家看看:
2.再迴圈把資料扔進這張圖中執行
舉一個不恰當的比方:
機器學習任務類似與起房子,一條一條的資料就是一塊一塊的磚,最終訓練出來的模型就是房子本身,那麼相對應的起房子的流程就是:
1.先畫一個設計的圖紙
2.根據這個設計的圖紙,用磚一點一點把房子造出來

這裡稍微有些不恰當的細節,不過初學者不用在意這些細節。
那麼接著我們就要認識到TF中的一個最重要的概念,那就是Session,這個Session就可以理解為施工隊,Session的具體用法如下:
#建立一個施工隊
sess = tf.Session()
#把圖紙和磚交給施工隊並讓他們開始幹活
sess.run(...)
是不是很簡單呢?掌握了TF程式碼結構中這個最大的不一樣,剩下的相對來說就比較直觀了。
前面提到,TF程式碼結構主要分為兩個部分。那麼在真實的專案中,實際上會更加複雜一些,一般來說我們會把程式碼分為四個部分:
1.圖定義模組
2.資料讀取處理模組
3.訓練執行模組
4.模型儲存模組
也就是比基本流程多 "資料讀取處理" 和 "模型儲存" 兩個模組,由於篇幅限制,今天我們不打算去討論模型的儲存,我們就把前三項完成即可。
Part 2、繼續完成上篇文章的解題思路
好了,大家看完了上面的部分,起碼應該對TF有了一個基本的認知,而且還學會了兩個函式呼叫,恭喜大家,離學會TF只剩下十萬八千里的距離,我們繼續努力。
說完TF基礎知識,我們回顧一下我們上篇文章裡的問題和解題思路,我們的要解決的問題是識別Discuz系統中的驗證碼:

我們打算用TF來解決這個問題,那麼我們的解題思路如下:
第一步:將問題分解成輸入(x)到輸出(y)這樣的結構,如Discuz驗證碼的輸入是圖片,輸出是四個字元的字串
第二步:找到很多同時包含輸入輸出的資料,比如很多有識別結果的驗證碼圖片
第三步:針對不同問題,找到演算法大神們的已經定義好的演算法並實現成程式碼
第四步:嘗試使用這個演算法訓練這些資料,如果效果不好,演算法中有一些引數可以手動調整,至於怎麼調,可以參考前人經驗,也可以自己瞎調積累經驗。
第五步:寫一個程式載入模型,接受一個新的輸入值,通過模型計算出新的輸出值。
粗體部分是我們上篇文章已經完成了的步驟,這篇文章主要來完成第三步。這裡我們結合本文Part 1討論的內容,我們將第三步繼續分解一下:
1.圖定義模組
- 針對影象識別問題,我們決定使用CNN。
- 大神們定義了很多CNN。但是因為我們是菜鳥,所以我們打算用最簡單的那種。
- 我們還不會寫TF程式碼,所以得先抄一個CNN的實現
2.資料讀取模組(如果是本地的TF,請自行解決這個部分)
- 我們的資料在哪裡? - 神箭手爬下來的資料
- 我們怎麼讀取到這些資料?- 通過官方定義的介面
- 讀入資料怎麼傳給TF -抄官方的Demo
3.訓練執行模組
- 這個我們已經會了,建立一個施工隊,並讓他們幹活
好了,思路已經很清晰了,大家可以按照這個思路去抄程式碼了...

好吧,前面這句是開玩笑的,就以大家現在的水準,怎麼可能能抄的出來呢。當然是我先抄下來給大家了,程式碼奉上:
import tensorflow as tf
import numpy as np
import pandas as pd
######## 圖定義模組 ########
x = tf.placeholder(tf.string,shape=[None,])
image_bin = tf.decode_base64(x)
image_bin_reshape = tf.reshape(image_bin,shape=[-1,])
images = tf.map_fn(lambda img: tf.image.decode_png(img), image_bin_reshape,dtype=tf.uint8)
image_gray = tf.image.rgb_to_grayscale(images)
image_resized = tf.image.resize_images(image_gray, [48, 48],tf.image.ResizeMethod.NEAREST_NEIGHBOR)
image_resized_float = tf.image.convert_image_dtype(image_resized, tf.float32)
y1 = tf.placeholder(tf.float32,shape=[None, 24])
y2 = tf.placeholder(tf.float32,shape=[None, 24])
y3 = tf.placeholder(tf.float32,shape=[None, 24])
y4 = tf.placeholder(tf.float32,shape=[None, 24])
image_x = tf.reshape(image_resized_float,shape=[-1,48,48,1])
conv1 = tf.layers.conv2d(image_x, filters=32, kernel_size=[5, 5], padding='same')
norm1 = tf.layers.batch_normalization(conv1)
activation1 = tf.nn.relu(conv1)
pool1 = tf.layers.max_pooling2d(activation1, pool_size=[2, 2], strides=2, padding='same')
hidden1 = pool1
conv2 = tf.layers.conv2d(hidden1, filters=64, kernel_size=[5, 5], padding='same')
norm2 = tf.layers.batch_normalization(conv2)
activation2 = tf.nn.relu(norm2)
pool2 = tf.layers.max_pooling2d(activation2, pool_size=[2, 2], strides=2, padding='same')
hidden2 = pool2
flatten = tf.reshape(hidden2, [-1, 12 * 12 * 64])
hidden3 = tf.layers.dense(flatten, units=1024, activation=tf.nn.relu)
letter1 = tf.layers.dense(hidden3, units=24)
letter2 = tf.layers.dense(hidden3, units=24)
letter3 = tf.layers.dense(hidden3, units=24)
letter4 = tf.layers.dense(hidden3, units=24)
letter1_cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y1, logits=letter1))
letter2_cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y2, logits=letter2))
letter3_cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y3, logits=letter3))
letter4_cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y4, logits=letter4))
loss = letter1_cross_entropy + letter2_cross_entropy+letter3_cross_entropy+letter4_cross_entropy
optimizer = tf.train.AdamOptimizer(1e-4)
train_op = optimizer.minimize(loss)
predict_concat = tf.stack([tf.argmax(letter1,1),
tf.argmax(letter2,1),
tf.argmax(letter3,1),
tf.argmax(letter4,1)],1)
y_concat = tf.stack([tf.argmax(y1,1),
tf.argmax(y2,1),
tf.argmax(y3,1),
tf.argmax(y4,1)],1)
accuracy_internal = tf.cast(tf.equal(predict_concat, y_concat),tf.float32),
accuracy = tf.reduce_mean(tf.reduce_min(accuracy_internal,2))
accuracy_letter = tf.reduce_mean(tf.reshape(accuracy_internal,[-1]))
initer = tf.global_variables_initializer()
sess = tf.Session()
sess.run(initer)
######## 資料讀取模組 ########
pickup = "BCEFGHJKMPQRTVWXY2346789"
reader = pd.read_source(souce_id=802522,iterator=True)
identity = np.identity(24)
for i in range(1000):
df = reader.get_chunk(100)
if df.empty:
reader = pd.read_source(souce_id=802522,iterator=True)
continue
batch_y = df["code"].values
batch_x = df["content"].values
batch_y_1 = [identity[pickup.find(code[0])] for code in batch_y]
batch_y_2 = [identity[pickup.find(code[1])] for code in batch_y]
batch_y_3 = [identity[pickup.find(code[2])] for code in batch_y]
batch_y_4 = [identity[pickup.find(code[3])] for code in batch_y]
######## 訓練執行模組 ########
if i%10 == 0:
print("step:"+str(i))
accuracy_letter_,accuracy_ = sess.run([accuracy_letter,accuracy],feed_dict={x:batch_x,y1:batch_y_1,y2:batch_y_2,y3:batch_y_3,y4:batch_y_4})
print(accuracy_letter_)
print("accuracy is ====>%f"%accuracy_)
if accuracy_ > 0.80:
break
sess.run(train_op,feed_dict={x:batch_x,y1:batch_y_1,y2:batch_y_2,y3:batch_y_3,y4:batch_y_4})
特別說明兩點!!!!!
1.這段程式碼由於有資料讀取處理模組,這個呼叫了pd.read_source這個方法,因此只能在神箭手上執行,如果希望本地執行的朋友,需要替換pd.read_source這個方法
2.pd.read_source裡面的source_id是我的資料id,大家是讀取不了了,需要用我上一篇文章中的爬蟲程式碼跑出來的資料對應的資料id替換進去即可。
好了,肯定有朋友要說了,這麼一長串,我抄下來還是不理解啊。沒關係,咱們先把程式碼跑通其實最重要,後面我們會需要不斷的改動這段程式碼,改著改著就懂了。
關於這段程式碼,我在補充以下幾點,大家可以帶著這些問題去把程式碼看一看,嘗試簡單理解下:
一、關於圖定義部分
從x到accuracy_letter都是定義圖的部分,這張圖看著很大,不過其實包含了三個部分,
1.從x到image_x是資料預處理部分(等等,圖裡面怎麼也有預處理?這個我在下一篇文章中會講到,網上一般程式碼是不會這麼寫的)
2.從image_x到train_op是核心需要訓練的圖部分,這部分圖是核心的CNN,是我根據從github中找來的程式碼簡化的,值得注意的是這裡的CNN跟傳統的CNN不一樣,因為我們要輸出4個結果(就是驗證碼的4個字元),一般的識別只輸出一個結果(比如是貓,還是狗,還是兔子),不過這個不一樣還是很簡單的,後面我們進一步過程式碼的時候,大家就會明白。(另外,由於我們資料集可以是無窮大,所以我扔掉防止過擬合的程式碼,讓訓練能快一點)
3.從train_op到accuracy_letter是我們計算我們訓練結果準確率的部分,是用來判斷目前模型的表現的,有沒有不影響核心功能。
二、關於資料處理部分
神箭手官方的介面是給python的資料清洗類庫pandas增加了一個read_source方法,通過get_chunk返回的是一個標準的pandas的dataframe物件,用過pandas的朋友應該很熟悉,沒用過的直接抄就行,這段程式碼在大部分時候都不用改。
特別注意的是,我們資料中的輸出部分y(就是驗證碼的識別結果),是一個四個字元的字串,但是這樣子是不能傳給TF的,TF需要另外一種格式的資料y(one-hot encoding),轉換程式碼就是中間一段,我單獨截取出來看下,暫時不理解的也無所謂(不過建議大家可以列印下這個one-hot encoding一般是什麼樣子的,有個更直觀的理解)。
pickup = "BCEFGHJKMPQRTVWXY2346789"
identity = np.identity(24)
batch_y_1 = [identity[pickup.find(code[0])] for code in batch_y]
batch_y_2 = [identity[pickup.find(code[1])] for code in batch_y]
batch_y_3 = [identity[pickup.find(code[2])] for code in batch_y]
batch_y_4 = [identity[pickup.find(code[3])] for code in batch_y]
三、關於訓練執行模組
傳統的話我們應該把我們的資料集分成三部分,訓練集,驗證集和測試集。是不是聽著就很麻煩,不過因為我們的資料集可以是無限大,那就不用這麼麻煩了,直接就用訓練集做驗證了。正常情況來說起碼還是得分一個驗證集,這個我們後面再討論。
我們計算了兩個準確值accuracy_letter和accuracy,accuracy_letter是計算所有字元的準確度,accuracy是計算組合成字串後的準確度,例如我們的標準答案是:5CD4,8ACF 兩個結果,而我們計算出來的答案是3CE4,8ACF,那麼我們accuracy_letter就是6/8=0.75,因為只有第一個5和第三個D算錯了,但是accuracy就是1/2=0.5,因為從字串角度來說,整個第一個字串識別錯了,只有第二個是對的。這裡我們關心的實際上是accuracy,但是由於accuracy變動很慢,我們通過觀察accuracy_letter來判斷我們的模型到底跑怎麼樣了。
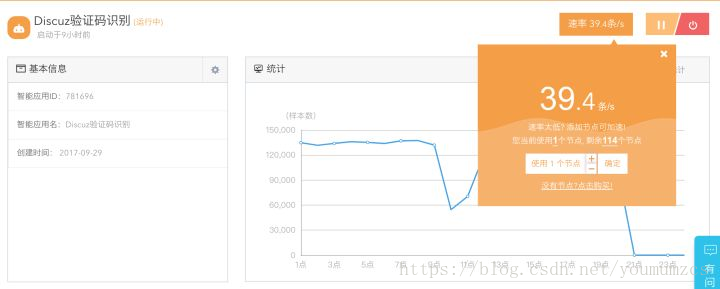
好了,如果大家之前已經把資料爬好了,那麼這個程式碼直接複製到神箭手應用中(本地朋友替換掉read_source程式碼既可直接執行),再修改資料id(source_id)就可以直接運行了,我們可以從日誌中查看準確率:
====================================================================

如果是剛入門的朋友,今天看到這麼多程式碼肯定還是很蒙的。不要緊,大家只需要掌握文章中提到的以下幾個要點既可:
1.TF的程式碼結構
2.核心類Session的使用
3.瞭解除了圖定義以外的其他程式碼的含義。程式碼不多,最大的難點是one-hot encoding的轉換,大家可以參考程式碼多寫幾次就既可,至於為什麼要轉換成這麼詭異的樣子,主要是因為這樣子更適合訓練中的向量計算,當然你也可以理解為大家都說這麼做好,所以我們也這麼做就行了,其實深度學習中有大量的這種經驗性的東西,不太用深究。
目前的程式碼雖然可以訓練模型,但是不會儲存,無法繼續訓練,更無法上線使用。下篇文章將在這篇文章的程式碼的基礎上,完成最後一棒:就是模型的部署上線。
更多大資料爬蟲,人工智慧相關應用歡迎訪問我們的官網: 神箭手雲爬蟲