
windows系統作為driver遠端提交任務給spark standalone叢集demo
阿新 • • 發佈:2019-01-29
其實這個是上篇文章的升級版。
先上demo程式碼吧,其中要改的地方還挺多的,此外,如果不將模型持久化的話,煩請自行修改相關程式碼(demo比較簡單,我就不闡釋他是幹什麼的了):
from pyspark.ml.feature import Word2Vec from pyspark.sql import SparkSession from pyspark import SparkConf from pyspark.ml import Pipeline, PipelineModel import os if __name__ == "__main__": # 環境變數 # 值為linux系統中master、worker的啟動所需版本的python3命令 os.environ['PYSPARK_PYTHON'] = 'python3' # 值為linux系統中master、worker的啟動所需版本的python命令 os.environ['PYSPARK_DRIVER_PYTHON'] = 'python3' # 值為本地windows系統中spark目錄 os.environ['SPARK_HOME'] = 'D:/PyWS3/spark-2.2.1' # 值為本機IP,與建立連線時所需要的IP,防止多張網絡卡時導致連線失敗 os.environ['SPARK_LOCAL_IP'] = '192.168.xxx.xxx' os.environ['HADOOP_HOME'] = 'D:/PyWS3/spark-2.2.1/hadoop' # 工作流模型儲存地址,建議存在hdfs或者linux檔案系統中,windows系統下我個人儲存下來是有問題的 # windows系統下生成的模型metadata中不存在part檔案,導致load時會失敗,待解決 model_path = 'hdfs://ip:9000/data/word2vecmodel' sparkconf = SparkConf() sparkconf.setAppName("word2vec").setMaster("spark://ip:7077").set("spark.submit.deployMode", "client").set('spark.driver.memory', '2g').set( 'spark.executor.memory', '2g').set('spark.executor.cores', 1).set( 'spark.network.timeout', 600).set('spark.executor.heartbeatInterval', 120).set('spark.cores.max', 4) spark = SparkSession.builder.config(conf=sparkconf).getOrCreate() documentDF = spark.createDataFrame([ ("Hi I heard about Spark".split(" "),), ("I wish Java could use case classes".split(" "),), ("Logistic regression models are neat".split(" "),) ], ["text"]) word2Vec = Word2Vec(vectorSize=3, minCount=0, inputCol="text", outputCol="result") pipeline = Pipeline(stages=[word2Vec]) model = pipeline.fit(documentDF) model.write().overwrite().save(model_path) temp_model = PipelineModel.load(model_path) result = temp_model.transform(documentDF) for row in result.collect(): text, vector = row print("Text: [%s] => \nVector: %s\n" % (", ".join(text), str(vector))) spark.stop()
接著是需要下載的包與需要修改的內容:
需下載檔案列表
1. 獲取linux系統spark安裝包,兩者必需一致。下載地址:http://spark.apache.org/downloads.html
2. 不是必須。獲取與hadoop版本對應的winutils.exe和hadoop.dll。下載地址:https://github.com/steveloughran/winutils
配置內容
1. python直譯器版本需要與遠端環境中一致!
- pycharm中設定
- 系統環境變數中設定,保證cmd中使用python命令或者其他啟動python的命令時版本號與spark結點上python版本一致
2. 直譯器相關變數
-


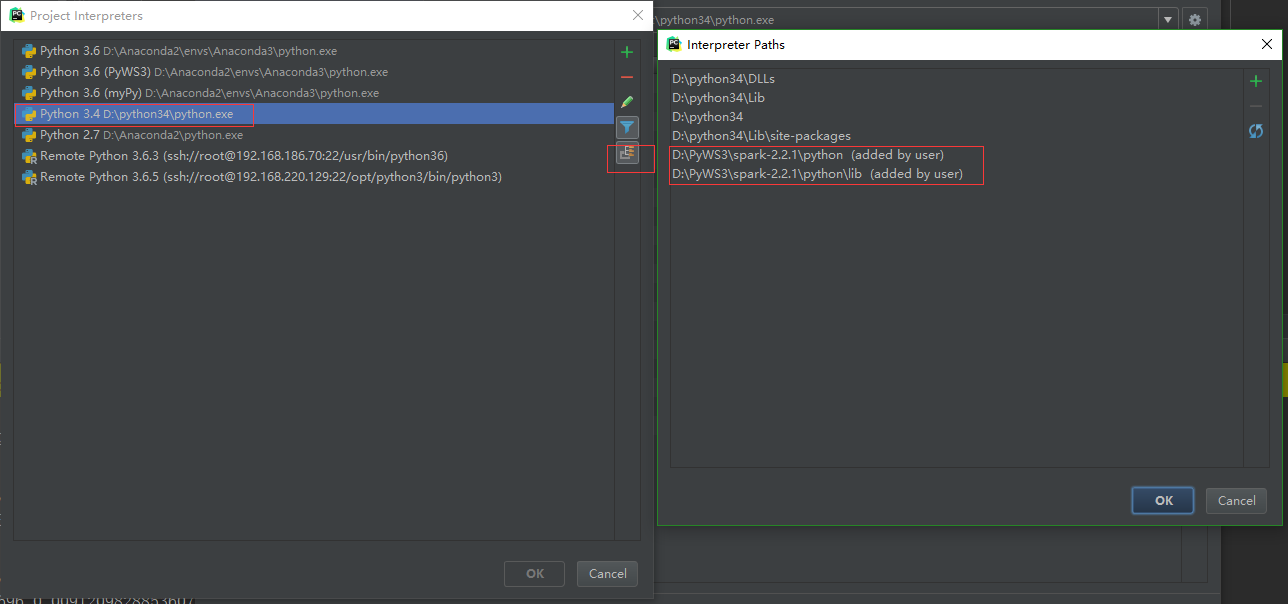
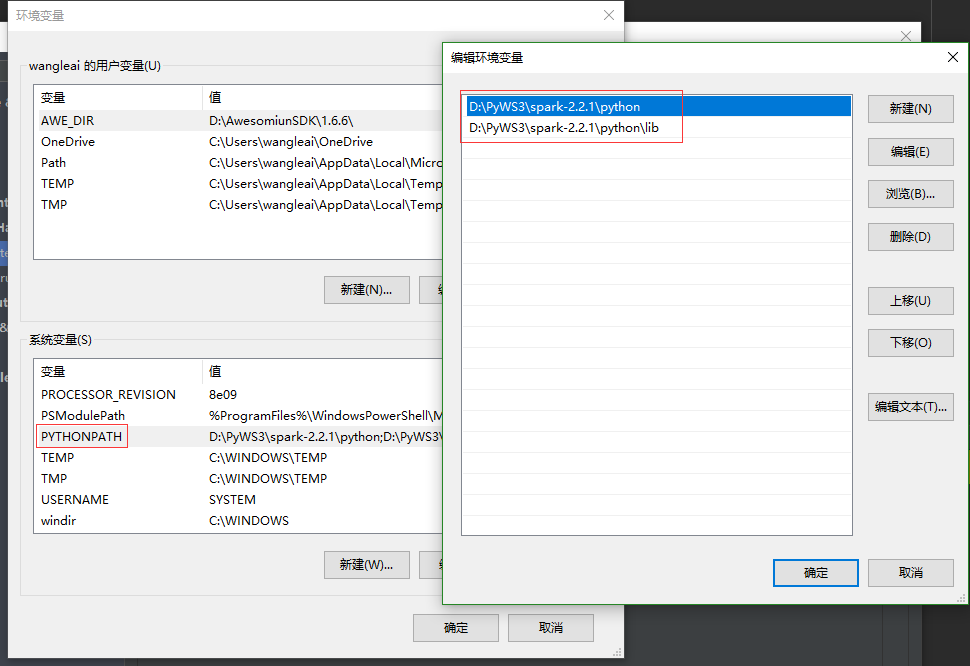
- 系統環境變數中設定,路徑根據spark安裝包解壓出來的目錄來,沒有PYTHONPATH就新建
3. 修改程式碼中相關環境變數設定的值,如何修改參看程式碼中註釋
額外內容
出現此錯誤(其實這個錯誤對程式的執行毫無影響):
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
將hadoop.dll放入C:\Windows\System32目錄下,在任意英文路徑目錄下建立bin資料夾並將winutils.exe放入。比如D:\PyWS3\spark-2.2.1\hadoop\bin\winutils.exe。最後,程式碼中加入
os.environ['HADOOP_HOME'] = 'D:/PyWS3/spark-2.2.1/hadoop'