
記憶體對齊與記憶體分配原則
首先講一個概念—-記憶體對齊
一種提高記憶體訪問速度的策略,cpu在訪問未對其的記憶體需要經過兩次記憶體訪問,而經過記憶體對齊一次就可以了。(?)
打個比方就是:作業系統在訪問記憶體時,每次讀取一定的長度(這個長度是系統預設的對其係數),程式中你也可以自己設定對齊係數,告訴編譯器你想怎麼對齊,可用#pargam pack(n),指定n為對其係數。但是當沒有了記憶體對齊,cpu在訪問一個變數時候,可能會訪問兩次,為什麼呢?
32位cpu一次能最多處理的資訊是32bit位,如果你沒有指定對齊,我們假設這樣的資料結構在記憶體中存在的情況,這也是我們後面要討論的結構
typedef strutc test{
char 對應的在記憶體中存放的方式可能是這樣(假定32位下):
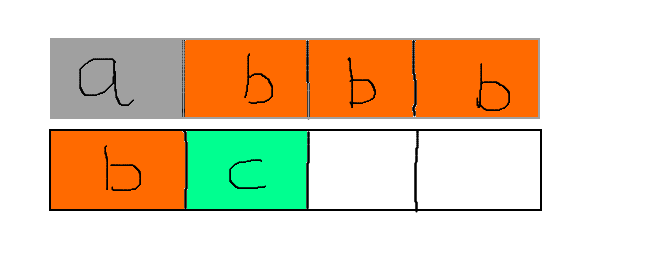
那麼,這樣一來,取得這個int型變數需要經過兩次的定址,拼湊成一個完整的4位元組的數。這個過程還涉及到cpu指令集呼叫和匯流排的讀寫操作,如果真是沒有對齊的話,效率會差到不知道哪兒去了。
所以這個記憶體對齊是必須遵守的,為了提高cpu訪問效率和速度。
繼續引入另外一個概念:記憶體的自然對齊:每一種資料型別都必須放在地址中的整數倍上
舉個例子如下:
地址4可以放char(1)型別,可以放int(4)型,可以放short(2)型,但是不能存放double(8)型,僅僅因為4不是8的整數倍。
地址3能存放char型,但是其他int,short,double都不能存放。
有一個特殊地址,就是0,它可以是任何型別的整數倍,所以可以存放任何資料。
根據這個規則,那麼在分配一大塊包含很多變數的記憶體的時候,會產生很多碎片,具體到下面分析
接下來,我們對這個結構體來進行一個分析:
#include<stdio.h>
#include<stdlib.h>
typedef strutc test{
char a;
int b;
double c;
char d;
}
int main(void)
{
STU s;
printf 依照簡單的4位元組對齊(gcc預設是4位元組對齊),首先的char在0上(其實也就是某個4的整數倍數上),之後int b在地址4上,一直延續到8,double c就在地址8上,之後sizeof必須是8的整數倍,之前是4+4+8 == 16,那這個char就只能存入一個8大小的記憶體中了,也就是4+4+8+8 == 24
為什麼這麼算呢?
開始的可以根據記憶體的自然對齊求得,最後的char補7個空白是因為結構體的總大小,必須要是其內部最大成員的整數倍,不足的要補齊,像這裡就是double 8個位元組的整數倍,所以給最後的d補上了7個空白空間。這也是記憶體分配的3個原則之一。
關於記憶體分配的其他兩個規則如下:
1.結構體或union聯合的資料成員,第一個資料成員是要放在offset == 0的地方,如果遇上子成員,要根據子成員的型別存放在對應的整數倍的地址上
2.如果結構體作為成員,則要找到這個結構體中的最大元素,然後從這個最大成員的整數倍地址開始儲存(strutc a中有一個struct b,b裡面有char,int,double….那b應該從8的整數倍開始儲存)
還需要注意一點:
typedef struct stu{
char a;
int b;
char ex;
double c;
char d;
}STU;
printf("STU的大小是 = %d\n",(int)sizeof(STU));
/*32位輸出
STU的大小是 = 24
*/
/*64位輸出
STU的大小是 = 32
*/計算一下出來的結果和輸出是否正確:
32位:a( 4 )+b( 4 )+ex( 4 )+c( 4+4 )+d( 4 ) == 24
64位:a( 4 )+b( 4 )+ex( 8 )+c( 8 )+d( 8 ) == 32
而為什麼會出現這樣的結果呢?準確一點為什麼32位中的double變成了2個4位元組而不是一個8?
這需要結合之前說的記憶體的自然對齊,我們知道char遇到int型,產生3個空白,遇上double要產生7個空白。而這裡32位中的char遇上double卻只是產生了3個空白,是因為32位限制了一次只能讀入4個位元組資料處理,也就是說8位元組的double被分成了2個4位元組字元被處理,也可以說死了,32位平臺下就定死了4位元組對齊(當然你可以設定更小,但是沒什麼意義),接著說結構體,那結構體中最大的數就是4位元組的了,sizeof(STU)也只需要遵守是4的整數倍即可。最後得到24位元組。
64位就按正常的計算。
最後貼上這一段程式碼,是下面參考博文中某個作者總結的一段,只要能看懂這段程式碼就大抵上全部理解3個記憶體對其和分配原則了
typedef struct bb
{
int id; //[0]....[3]
double weight; //[8].....[15] 原則1
float height; //[16]..[19],總長要為8的整數倍,補齊[20]...[23] 原則3
}BB;
typedef struct aa
{
char name[2]; //[0],[1]
int id; //[4]...[7] 原則1
double score; //[8]....[15]
short grade; //[16],[17]
BB b; //[24]......[47] 原則2
}AA;
int main()
{
AA a;
cout<<sizeof(a)<<" "<<sizeof(BB)<<endl;
return 0;
}
/*輸出
48 24
*/總結
記憶體對齊的目的和好處
記憶體自然對其的概念
記憶體對齊(分配)的3個原則
有什麼錯誤還請指出