
JAVA刷題筆記
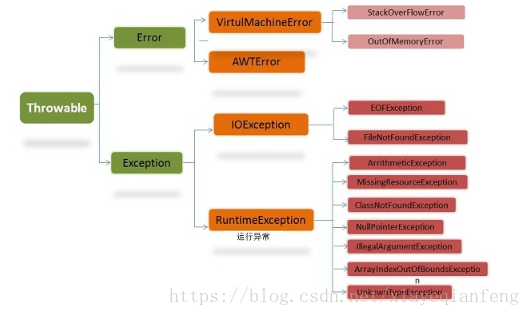
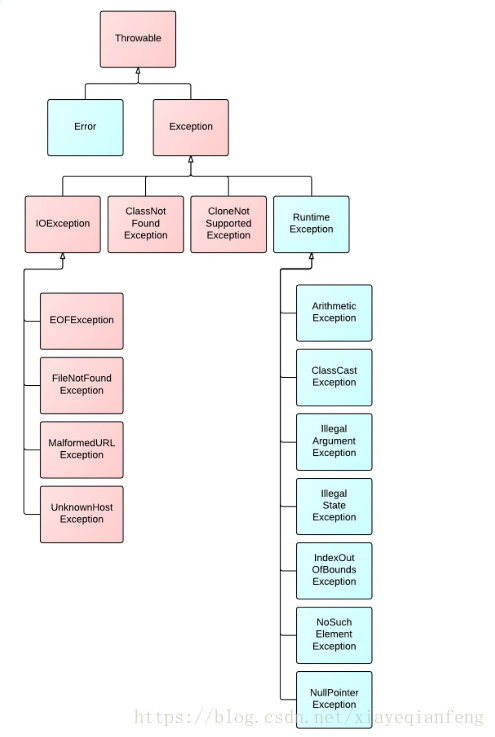
1.JAVA異常類體系
Error類體系描述了java執行體系中的內部錯誤以及資源耗盡的情形,Error不需要捕捉;
異常分為執行時異常,非執行時異常和error,其中error是系統異常,只能重啟系統解決。非執行時異常需要我們自己補獲,而執行異常是程式執行時由虛擬機器幫助我們補獲,執行時異常包括陣列的溢位,記憶體的溢位空指標,分母為0等!
2.執行緒安全
Thread.sleep() 和 Object.wait(),都可以丟擲 InterruptedException。這個異常是不能忽略的,因為它是一個檢查異常(checked exception)
如果你的程式碼所在的程序中又多個執行緒再同時執行,而這些執行緒可能會同時執行這段程式碼。如果每次執行結果和單執行緒執行的結果是一樣的,而且其他的變數的值也和預期是一樣的,就是執行緒安全的。
執行緒安全問題都是由全域性變數及靜態變數引起的。

3.Servlet載入
ServletContext物件:servlet容器在啟動時會載入web應用,併為每個web應用建立唯一的servletcontext物件,可以把ServletContext看成是一個Web應用的伺服器端元件的共享記憶體,在ServletContext中可以存放共享資料。ServletContext物件是真正的一個全域性物件,凡是web容器中的Servlet都可以訪問。
整個web應用只有唯一的一個ServletContext物件
servletConfig物件:用於封裝servlet的配置資訊。從一個servlet被例項化後,對任何客戶端在任何時候訪問有效,但僅對servlet自身有效,一個servlet的ServletConfig物件不能被另一個servlet訪問。
4.java表示式轉型規則由低到高轉換
java表示式轉型規則由低到高轉換:
1、所有的byte,short,char型的值將被提升為int型;
2、如果有一個運算元是long型,計算結果是long型;
3、如果有一個運算元是float型,計算結果是float型;
4、如果有一個運算元是double型,計算結果是double型;
5、被fianl修飾的變數不會自動改變型別,當2個final修飾相操作時,結果會根據左邊變數的型別而轉化。
6、整數型別byte(1個位元組)short(2個位元組)int(4個位元組)long(8個位元組)
7、字元型別char(2個位元組)
8、浮點型別float(4個位元組)double(8個位元組,預設浮點型型別)
只要兩個運算元中有一個是double型別的,另一個將會被轉換成double型別,並且結果也是double型別,如果兩個運算元中有一個是float型別的,另一個將會被轉換為float型別,並且結果也是float型別,如果兩個運算元中有一個是long型別的,另一個將會被轉換成long型別,並且結果也是long型別,否則(運算元為:byte、short、int 、char),兩個數都會被轉換成int型別,並且結果也是int型別。
5.java記憶體
方法區和堆記憶體是執行緒共享的。程式計數器、虛擬機器棧是線性隔離的。
6.java的各種開發模式
7.抽象類vs介面
(1)抽象類可以定義普通成員變數而介面不可以,但是抽象類和介面都可以定義靜態成員變數,只能介面的靜態成員變數要用static final public來修飾。
(2)介面沒有構造方法,所以不能例項化,抽象類又構造方法,但是不是用來例項化的,是用來初始化的。
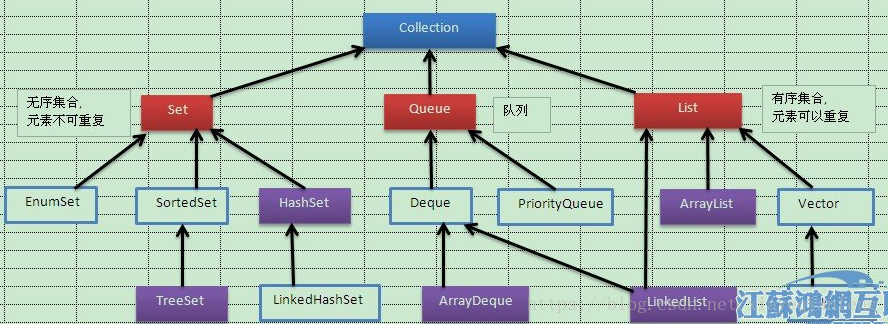
8.Collection子類
9.java基本資料型別
(1)第一類:整數型別 byte short int long
(2) 第二類:浮點型 float double
(3)第三類:邏輯型 boolean
(4)字元型 : char
10.java正則表示式
| 元字元 | 描述 |
| \ | 將下一個字元標記符、或一個向後引用、或一個八進位制轉義符。例如,“\\n”匹配\n。“\n”匹配換行符。序列“\\”匹配“\”而“\(”則匹配“(”。即相當於多種程式語言中都有的“轉義字元”的概念。 |
|
^ |
匹配輸入字串的開始位置。如果設定了RegExp物件的Multiline屬性,^也匹配“\n”或“\r”之後的位置。 |
|
$ |
匹配輸入字串的結束位置。如果設定了RegExp物件的Multiline屬性,$也匹配“\n”或“\r”之前的位置。 |
|
* |
匹配前面的子表示式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等價於o{0,} |
|
+ |
匹配前面的子表示式一次或多次(大於等於1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等價於{1,}。 |
|
? |
匹配前面的子表示式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等價於{0,1}。 |
|
{n} |
n是一個非負整數。匹配確定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的兩個o。 |
|
{n,} |
n是一個非負整數。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等價於“o+”。“o{0,}”則等價於“o*”。 |
|
{n,m} |
m和n均為非負整數,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”將匹配“fooooood”中的前三個o為一組,後三個o為一組。“o{0,1}”等價於“o?”。請注意在逗號和兩個數之間不能有空格。 |
|
? |
當該字元緊跟在任何一個其他限制符(*,+,?,{n},{n,},{n,m})後面時,匹配模式是非貪婪的。非貪婪模式儘可能少的匹配所搜尋的字串,而預設的貪婪模式則儘可能多的匹配所搜尋的字串。例如,對於字串“oooo”,“o+”將盡可能多的匹配“o”,得到結果[“oooo”],而“o+?”將盡可能少的匹配“o”,得到結果 ['o', 'o', 'o', 'o'] |
|
.點 |
匹配除“\r\n”之外的任何單個字元。要匹配包括“\r\n”在內的任何字元,請使用像“[\s\S]”的模式。 |
|
(pattern) |
匹配pattern並獲取這一匹配。所獲取的匹配可以從產生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中則使用$0…$9屬性。要匹配圓括號字元,請使用“\(”或“\)”。 |
|
(?:pattern) |
非獲取匹配,匹配pattern但不獲取匹配結果,不進行儲存供以後使用。這在使用或字元“(|)”來組合一個模式的各個部分時很有用。例如“industr(?:y|ies)”就是一個比“industry|industries”更簡略的表示式。 |
| (?=pattern) | 非獲取匹配,正向肯定預查,在任何匹配pattern的字串開始處匹配查詢字串,該匹配不需要獲取供以後使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜尋,而不是從包含預查的字元之後開始。 |
| (?!pattern) | 非獲取匹配,正向否定預查,在任何不匹配pattern的字串開始處匹配查詢字串,該匹配不需要獲取供以後使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
| (?<=pattern) | 非獲取匹配,反向肯定預查,與正向肯定預查類似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
| (?<!pattern) |
非獲取匹配,反向否定預查,與正向否定預查類似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。這個地方不正確,有問題 此處用或任意一項都不能超過2位,如“(?<!95|98|NT|20)Windows正確,“(?<!95|980|NT|20)Windows 報錯,若是單獨使用則無限制,如(?<!2000)Windows 正確匹配 |
|
x|y |
匹配x或y。例如,“z|food”能匹配“z”或“food”(此處請謹慎)。“[zf]ood”則匹配“zood”或“food”。 |
|
[xyz] |
字元集合。匹配所包含的任意一個字元。例如,“[abc]”可以匹配“plain”中的“a”。 |
|
[^xyz] |
負值字元集合。匹配未包含的任意字元。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
|
a-z] |
字元範圍。匹配指定範圍內的任意字元。例如,“[a-z]”可以匹配“a”到“z”範圍內的任意小寫字母字元。 注意:只有連字元在字元組內部時,並且出現在兩個字元之間時,才能表示字元的範圍; 如果出字元組的開頭,則只能表示連字元本身. |
|
[^a-z] |
負值字元範圍。匹配任何不在指定範圍內的任意字元。例如,“[^a-z]”可以匹配任何不在“a”到“z”範圍內的任意字元。 |
|
\b |
匹配一個單詞邊界,也就是指單詞和空格間的位置(即正則表示式的“匹配”有兩種概念,一種是匹配字元,一種是匹配位置,這裡的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
|
\B |
匹配非單詞邊界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
|
\cx |
匹配由x指明的控制字元。例如,\cM匹配一個Control-M或回車符。x的值必須為A-Z或a-z之一。否則,將c視為一個原義的“c”字元。 |
|
\d |
匹配一個數字字元。等價於[0-9]。grep 要加上-P,perl正則支援 |
|
\D |
匹配一個非數字字元。等價於[^0-9]。grep要加上-P,perl正則支援 |
|
\f |
匹配一個換頁符。等價於\x0c和\cL。 |
|
\n |
匹配一個換行符。等價於\x0a和\cJ。 |
|
\r |
匹配一個回車符。等價於\x0d和\cM。 |
|
\s |
匹配任何不可見字元,包括空格、製表符、換頁符等等。等價於[ \f\n\r\t\v]。 |
|
\S |
匹配任何可見字元。等價於[^ \f\n\r\t\v]。 |
|
\t |
匹配一個製表符。等價於\x09和\cI。 |
|
\v |
匹配一個垂直製表符。等價於\x0b和\cK。 |
|
\w |
匹配包括下劃線的任何單詞字元。類似但不等價於“[A-Za-z0-9_]”,這裡的"單詞"字元使用Unicode字符集 |
|
\W |
匹配任何非單詞字元。等價於“[^A-Za-z0-9_]”。 |
11.內部類
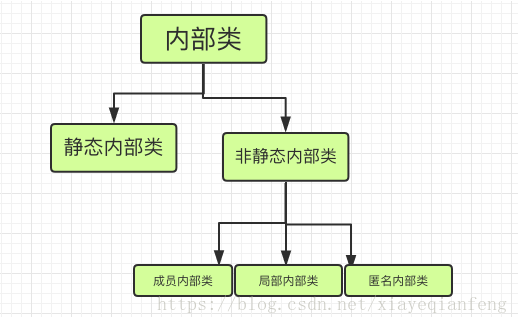
(1)靜態內部類除了訪問許可權修飾符比外圍類多以外, 和外圍類沒有區別, 只是程式碼上將靜態內部類組織在了外部類裡面。靜態內部類不能訪問外部類的非公開成員。
(2)成員內部類可以直接使用外部類的所有成員和方法,即使是private修飾的。而外部類要訪問內部類的所有成員變數和方法,內需要通過內部類的物件來獲取。(誰叫它是親兒子呢?) 要注意的是,成員內部類不能含有static的變數和方法。因為成員內部類需要先建立了外部類,才能建立它自己的。成員內部類不能有static修飾的成員,但是卻允許定義常量
(3)區域性內部類的區域性變數需要用final修飾;區域性變數必須有初始值。
(4)為了免去給內部類命名,或者只想使用一次,就可以選擇匿名內部類。
12.構造方法vs普通方法
(1)普通的類方法是可以和類名同名的,和構造方法唯一的區分就是,構造方法沒有返回值
(2)建構函式不能被繼承,只能被呼叫
13 java虛擬機器功能
(1)通過ClassLoader尋找和裝載class檔案
(2)解釋位元組碼成為指令並執行,提供class檔案的執行環境
(3)進行執行期間垃圾回收
(4)提供與硬體互動的平臺
14 default和protected的區別
default拒絕一切包外訪問;protected接受包外的子類訪問
15 關鍵字
(1)final用於宣告屬性,方法和類,分別表示屬性不可變,方法不可覆蓋,類不可繼承。
(2)finally是異常處理語句結構的一部分,表示總是執行。
(3)finalize這個方法一個物件只能執行一次,只能在第一次進入被回收的佇列,而且物件所屬於的類重寫了finalize方法才會被執行。第二次進入回收佇列的時候,不會再執行其finalize方法,而是直接被二次標記,在下一次GC的時候被GC。
(4) abstract不能與final同時修飾一個類
16 變數初始化
(1)靜態變數會預設賦初始值,區域性變數和final宣告的變數必須手動賦初始值。
17 ClassLoader
JDK中提供了三個ClassLoader,根據層級從高到低為:
1.BootStrap ClassLoader,主要載入JVM自身工作需要的類。
2.Extension ClassLoader,主要載入%JAVA_HOME%\lib\ext目錄下的庫類。
3. Application ClassLoader ,主要載入ClassPath指定的庫類,一般情況下這是程式中的預設類載入器,也是ClassLoader.getSystemClassLoader()的返回值。
JVM載入類的實現方式,我們稱為雙親委託模式:如果一個類載入收到了類載入的請求,他首先不會自己去嘗試載入這個類,而是把這個請求委託給自己的父載入器,每一層的類載入器都是如此,因此所有的類載入請求最終都應該傳送到頂層的Bootstrap ClassLoader中,只有當父載入器反饋自己無法完成載入請求時,子載入器才會嘗試自己載入。雙親委託模型的重要用途是為了解決類載入過程中的安全性問題
18.java中的四捨五入
floor : 意為地板,指向下取整,返回不大於它的最大整數 ceil : 意為天花板,指向上取整,返回不小於它的最小整數 round : 意為大約,表示“四捨五入”,而四捨五入是往大數方向入。Math.round(11.5)的結果為12,Math.round(-11.5)的結果為-11而不是-12。
19.java鎖
(1)自旋鎖,自旋,jvm預設是10次,有jvm自己控制。for去爭取鎖
(2)阻塞鎖,被阻塞的執行緒,不會爭奪鎖。
(3)可重入鎖,多次進入改鎖的域
(4)讀寫鎖
(5)互斥鎖 鎖本身就是互斥的
(6)悲觀鎖 不相信,這裡會是安全的,必須全部上鎖
(7)樂觀鎖
(8)公平鎖 又優先順序的鎖
(9)非公平鎖
(10)偏向鎖 無競爭不鎖,有競爭掛起,轉為輕量鎖
(11)物件鎖 鎖住物件
(12)執行緒鎖
(13)鎖粗化
(14)輕量級鎖 CAS實現
(15)鎖膨脹 jvm實現
(16)訊號量 使用阻塞鎖 實現的一種策略
(17)排他鎖:X鎖,若事物T對資料物件A加上X鎖,則只允許T讀取和修改A,其他任何事物都不能再對A加任何型別的鎖,直到T釋放A上的鎖。這就保證了其他事務在T釋放A上的鎖之前不能再讀取和修改A。
20 strut1 vs struts2
(1)struts1要求Action類繼承一個抽象基類。Struts1的一個普遍問題是使用抽象類程式設計而不是介面。
(2)Struts2 Action類可以實現一個Action介面,也可實現其他介面,使可選和定製的服務成為可能。Struts2提供一個ActionSupport基類去實現常用的介面。Action介面不是必須的,任何又execute標識的物件都可以用作struts2的Action物件。
(3)Struts1 Action依賴於Servlet API,因為當一個Action被呼叫時HttpServletRequest和HttpServletResponse被傳遞給execute方法。
(4)struts2 Action依賴於容器,允許Action脫離容器單獨被測試。如果需要,Struts2 Action仍然可以訪問初始的request和response。但是,其他的元素減少或者消除了直接訪問HttpServetRequest 和 HttpServletResponse的必要性。
(5)Struts1 Action是單例模式並且必須是執行緒安全的,因為僅有Action的一個例項來處理所有的請求。單例策略限制了Struts1 Action能作的事,並且要在開發時特別小心。Action資源必須是執行緒安全的或同步的。
(6) Struts2 Action物件為每一個請求產生一個例項,因此沒有執行緒安全問題。(實際上,servlet容器給每個請求產生許多可丟棄的物件,並且不會導致效能和垃圾回收問題)
21載入驅動的方法
(1)Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver);
(2) DriverManager.registerDriver(new com.mysql.jdbc.Driver());
(3) System.setPropetry("jdbc.drivers","com.mysql.jdbc.Driver");
22 queue類比較
(1)LinkedBlockingQueue:基於連結節點的可選限定的blocking queue 。 這個佇列排列元素FIFO(先進先出)。 佇列的頭部是佇列中最長的元素。 佇列的尾部是佇列中最短時間的元素。 新元素插入佇列的尾部,佇列檢索操作獲取佇列頭部的元素。 連結佇列通常具有比基於陣列的佇列更高的吞吐量,但在大多數併發應用程式中的可預測效能較低。
blocking queue說明:不接受null元素;可能是容量有限的;實現被設計為主要用於生產者 - 消費者佇列;不支援任何型別的“關閉”或“關閉”操作,表示不再新增專案實現是執行緒安全的;
(2)PriorityQueue:基於優先順序堆的無限優先順序queue 。 優先順序佇列的元素根據它們的有序natural ordering ,或由一個Comparator在佇列構造的時候提供,這取決於所使用的構造方法。 優先佇列不允許null元素。 依靠自然排序的優先順序佇列也不允許插入不可比較的物件(這樣做可能導致ClassCastException )。該佇列的頭部是相對於指定順序的最小元素。 如果多個元素被繫結到最小值,那麼頭就是這些元素之一 - 關係被任意破壞。 佇列檢索操作poll , remove , peek和element訪問在佇列的頭部的元件。優先順序佇列是無限制的,但是具有管理用於在佇列上儲存元素的陣列的大小的內部容量 。 它始終至少與佇列大小一樣大。 當元素被新增到優先順序佇列中時,其容量會自動增長。 沒有規定增長政策的細節。該類及其迭代器實現Collection和Iterator介面的所有可選方法。 方法iterator()中提供的迭代器不能保證以任何特定順序遍歷優先順序佇列的元素。 如果需要有序遍歷,請考慮使用Arrays.sort(pq.toArray()) 。請注意,此實現不同步。 如果任何執行緒修改佇列,多執行緒不應同時訪問PriorityQueue例項。 而是使用執行緒安全的PriorityBlockingQueue類。實現注意事項:此實現提供了O(log(n))的時間入隊和出隊方法( offer , poll , remove()和add ); remove(Object)和contains(Object)方法的線性時間; 和恆定時間檢索方法( peek , element和size )。
(3)ConcurrentLinkedQueue:基於連結節點的無界併發deque(deque是雙端佇列) 。 併發插入,刪除和訪問操作可以跨多個執行緒安全執行。 A ConcurrentLinkedDeque是許多執行緒將共享對公共集合的訪問的適當選擇。像大多數其他併發集合實現一樣,此類不允許使用null元素。
23 中介軟體
中介軟體是一種獨立的系統軟體或服務程式,分散式應用軟體藉助這種軟體在不同的技術之間共享資源。中介軟體位於客戶機/ 伺服器的作業系統之上,管理計算機資源和網路通訊。是連線兩個獨立應用程式或獨立系統的軟體。相連線的系統,即使它們具有不同的介面,但通過中介軟體相互之間仍能交換資訊。執行中介軟體的一個關鍵途徑是資訊傳遞。通過中介軟體,應用程式可以工作於多平臺或OS環境。(簡單來說,中介軟體並不能提高核心的效率,一般只是負責網路資訊的分發處理)。
24hashMap知識點
在這裡幫大家總結一下hashMap和hashtable方面的知識點吧: 1. 關於HashMap的一些說法: a) HashMap實際上是一個“連結串列雜湊”的資料結構,即陣列和連結串列的結合體。HashMap的底層結構是一個數組,陣列中的每一項是一條連結串列。 b) HashMap的例項有倆個引數影響其效能: “初始容量” 和 裝填因子。 c) HashMap實現不同步,執行緒不安全。 HashTable執行緒安全 d) HashMap中的key-value都是儲存在Entry中的。 e) HashMap可以存null鍵和null值,不保證元素的順序恆久不變,它的底層使用的是陣列和連結串列,通過hashCode()方法和equals方法保證鍵的唯一性 f) 解決衝突主要有三種方法:定址法,拉鍊法,再雜湊法。HashMap是採用拉鍊法解決雜湊衝突的。 注: 連結串列法是將相同hash值的物件組成一個連結串列放在hash值對應的槽位; 用開放定址法解決衝突的做法是:當衝突發生時,使用某種探查(亦稱探測)技術在散列表中形成一個探查(測)序列。 沿此序列逐個單元地查詢,直到找到給定 的關鍵字,或者碰到一個開放的地址(即該地址單元為空)為止(若要插入,在探查到開放的地址,則可將待插入的新結點存人該地址單元)。 拉鍊法解決衝突的做法是: 將所有關鍵字為同義詞的結點連結在同一個單鏈表中 。若選定的散列表長度為m,則可將散列表定義為一個由m個頭指標組成的指標數 組T[0..m-1]。凡是雜湊地址為i的結點,均插入到以T[i]為頭指標的單鏈表中。T中各分量的初值均應為空指標。在拉鍊法中,裝填因子α可以大於1,但一般均取α≤1。拉鍊法適合未規定元素的大小。 2. Hashtable和HashMap的區別: a) 繼承不同。 public class Hashtable extends Dictionary implements Map public class HashMap extends AbstractMap implements Map b) Hashtable中的方法是同步的,而HashMap中的方法在預設情況下是非同步的。在多執行緒併發的環境下,可以直接使用Hashtable,但是要使用HashMap的話就要自己增加同步處理了。 c) Hashtable 中, key 和 value 都不允許出現 null 值。 在 HashMap 中, null 可以作為鍵,這樣的鍵只有一個;可以有一個或多個鍵所對應的值為 null 。當 get() 方法返回 null 值時,即可以表示 HashMap 中沒有該鍵,也可以表示該鍵所對應的值為 null 。因此,在 HashMap 中不能由 get() 方法來判斷 HashMap 中是否存在某個鍵, 而應該用 containsKey() 方法來判斷。 d) 兩個遍歷方式的內部實現上不同。Hashtable、HashMap都使用了Iterator。而由於歷史原因,Hashtable還使用了Enumeration的方式 。 e) 雜湊值的使用不同,HashTable直接使用物件的hashCode。而HashMap重新計算hash值。 f) Hashtable和HashMap它們兩個內部實現方式的陣列的初始大小和擴容的方式。HashTable中hash陣列預設大小是11,增加的方式是old*2+1。HashMap中hash陣列的預設大小是16,而且一定是2的指數。 注: HashSet子類依靠hashCode()和equal()方法來區分重複元素。 HashSet內部使用Map儲存資料,即將HashSet的資料作為Map的key值儲存,這也是HashSet中元素不能重複的原因。而Map中儲存key值的,會去判斷當前Map中是否含有該Key物件,內部是先通過key的hashCode,確定有相同的hashCode之後,再通過equals方法判斷是否相同。
25. 同步器
(1)Java 併發庫 的Semaphore 可以很輕鬆完成訊號量控制,Semaphore可以控制某個資源可被同時訪問的個數,通過 acquire() 獲取一個許可,如果沒有就等待,而 release() 釋放一個許可。
(2)CyclicBarrier 主要的方法就是一個:await()。await() 方法沒被呼叫一次,計數便會減少1,並阻塞住當前執行緒。當計數減至0時,阻塞解除,所有在此 CyclicBarrier 上面阻塞的執行緒開始執行。
(3)直譯過來就是倒計數(CountDown)門閂(Latch)。倒計數不用說,門閂的意思顧名思義就是阻止前進。在這裡就是指 CountDownLatch.await() 方法在倒計數為0之前會阻塞當前執行緒。
26.靜態內部類
(1)靜態內部類不能直接訪問外部類的非靜態成員,但可以通過new 外部類成員的方式訪問
(2)如果外部類的靜態成員與內部類的成員名稱相同,可以通過“類名。靜態成員”訪問外部類的靜態成員“
(3)建立靜態內部類的物件時,不需要外部類的物件,可以直接建立內部類 物件名=new 內部類();
27子類和父類
(1)子類的許可權不能比父類更低
28 JAVA五個基本原則
(1)單一職責原則(Single-Resposibility Principle):一個類,最好只做一件事,只有一個引起它的變化。單一職責原則可以看做是低耦合、高內聚在面向物件原則上的引申,將職責定義為引起變化的原因,以提高內聚性來引起變化的原因。
(2)開放封閉原則(Open-Closed principle):軟體實體應該是可擴充套件的,而不可修改的。也就是對擴充套件開放,對修改封閉。
(3)Liskov替換原則(Liskov-Substitution Principle):子類必須能夠替換其基類。這一思想體現為對繼承機制約束規範,只有子類能夠替換基類時,才能保證系統在執行期內識別子類,這是保證複用的基礎。
(4)依賴倒置原則(Dependecy-Inversion Principle):依賴於抽象。具體而言就是高層模組不依賴於底層模組,二者都同依賴於抽象;抽象不依賴具體,具體依賴於抽象。
(5)介面隔離原則(Interface-Segregation Principle):使用多個曉的專門的介面,而不要使用一個大的總介面。
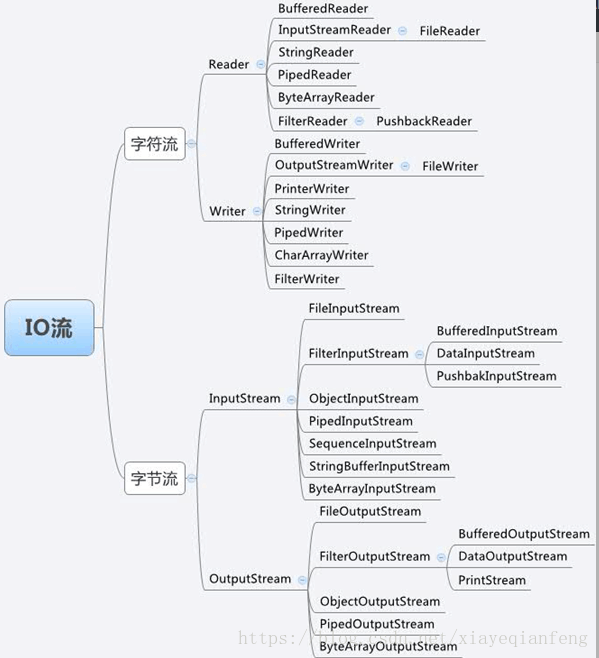
29.IO流
30、前臺執行緒和後臺執行緒的區別和聯絡
(1)後臺執行緒不會阻止程序的終止。屬於某個程序的所有前臺執行緒都終止後,該程序就會被終止。所有剩餘的後臺執行緒都會停止且不會完成。
(2)可以在任何時候將前臺執行緒修改為後臺執行緒,方式是設定Thread.IsBackground屬性。
(3)不管是前臺執行緒還是後臺執行緒,如果執行緒出現了異常,都會導致程序的終止。
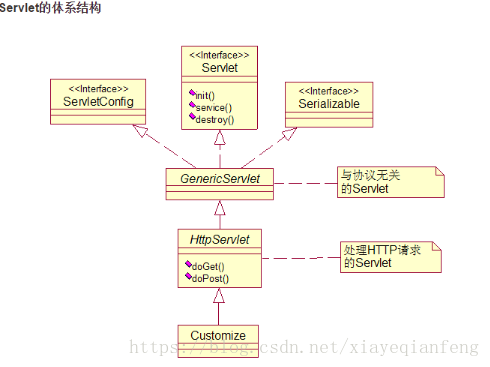
31、Servlet體系結構
32 網頁
(1)request.getAttrribute()方法返回request範圍內存在的物件,而request.getParameter()方法是獲取http提交過來的資料。 getAttribute是返回物件,getParameter返回字串。
(2) HttpServletResponse完成:設定http頭標誌,設定cookie,設定返回資料型別,輸出返回資料。
(3)HttpServletRequest:讀取路徑
(4)ServletContext:getParameter()是獲取POST/GET傳遞的引數值;getInitParameter獲取Tomcat的server.xml中設定Context的初始化引數;getAttibute()是獲取物件容器的資料值;getRequestDispatcher是請求轉發。
33 子類重寫父類方法
(1)子類重寫父類方法是,方法的訪問許可權不能小於原訪問許可權,在介面中,方法的預設許可權就是public,所以子類重寫後只能是public。
34 併發帶來的問題
(1)丟失修改
下面我們先來看一個例子,說明併發操作帶來的資料的不一致性問題。
考慮飛機訂票系統中的一個活動序列:
甲售票點(甲事務)讀出某航班的機票餘額A,設A=16.
乙售票點(乙事務)讀出同一航班的機票餘額A,也為16.
甲售票點賣出一張機票,修改餘額A←A-1.所以A為15,把A寫回資料庫.
乙售票點也賣出一張機票,修改餘額A←A-1.所以A為15,把A寫回資料庫.
結果明明賣出兩張機票,資料庫中機票餘額只減少1。
歸納起來就是:兩個事務T1和T2讀入同一資料並修改,T2提交的結果破壞了T1提交的結果,導致T1的修改被丟失。前文(2.1.4資料刪除與更新)中提到的問題及解決辦法往往是針對此類併發問題的。但仍然有幾類問題通過上面的方法解決不了,那就是:
(2)不可重複讀
不可重複讀是指事務T1讀取資料後,事務T2執行更新操作,使T1無法再現前一次讀取結果。具體地講,不可重複讀包括三種情況:
事務T1讀取某一資料後,事務T2對其做了修改,當事務1再次讀該資料時,得到與前一次不同的值。例如,T1讀取B=100進行運算,T2讀取同一資料B,對其進行修改後將B=200寫回資料庫。T1為了對讀取值校對重讀B,B已為200,與第一次讀取值不一致。
事務T1按一定條件從資料庫中讀取了某些資料記錄後,事務T2刪除了其中部分記錄,當T1再次按相同條件讀取資料時,發現某些記錄神密地消失了。
事務T1按一定條件從資料庫中讀取某些資料記錄後,事務T2插入了一些記錄,當T1再次按相同條件讀取資料時,發現多了一些記錄。(這也叫做幻影讀)
(3) 讀"髒"資料
讀"髒"資料是指事務T1修改某一資料,並將其寫回磁碟,事務T2讀取同一資料後,T1由於某種原因被撤消,這時T1已修改過的資料恢復原值,T2讀到的資料就與資料庫中的資料不一致,則T2讀到的資料就為"髒"資料,即不正確的資料。
產生上述三類資料不一致性的主要原因是併發操作破壞了事務的隔離性。併發控制就是要用正確的方式排程併發操作,使一個使用者事務的執行不受其它事務的干擾,從而避免造成資料的不一致性。
35 建立執行緒的方法
1、繼承Thread類建立執行緒
2、實現Runnable介面建立執行緒
3、實現Callable介面通過FutureTask包裝器來建立Thread執行緒
4、使用ExecutorService、Callable、Future實現有返回結果的執行緒
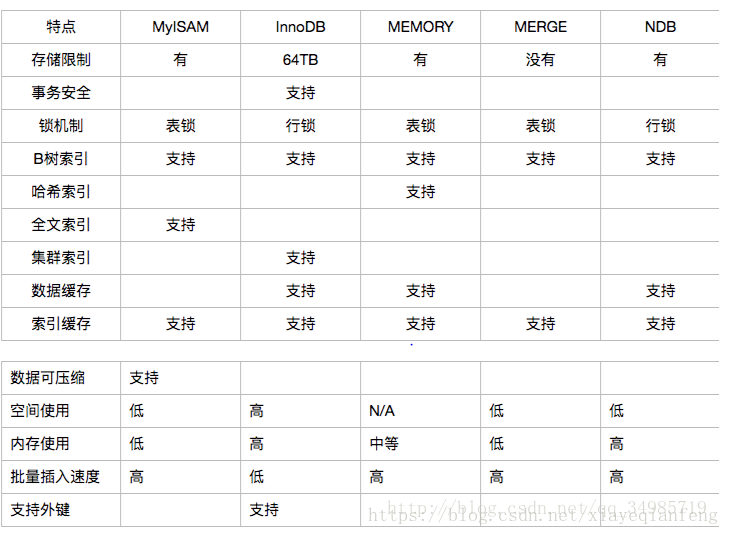
36 mysql常用資料引擎
37資料池連線
在Java中使用得比較流行的資料庫連線池主要有:DBCP,c3p0,druid。
另外,不論使用什麼連線池,低層都是使用JDBC連線,即:在應用程式中都需要載入JDBC驅動程式。
DBCP
c3p0
http://www.mchange.com/projects/c3p0/
使用c3p0有多種方式,如:既可以直接使用API方式配置c3p0,也可以通過檔案的方式進行配置,配置檔案有2種形式:properties或xml檔案。
druid
https://github.com/alibaba/druid
阿里開源的druid不單純是一個連線池,還添加了監控功能,目前已經是非常受推崇的連線池元件,詳細配置引數請參考官網。
38 實現物件克隆有兩種方式:
1). 實現Cloneable介面並重寫Object類中的clone()方法;
2). 實現Serializable介面,通過物件的序列化和反序列化實現克隆,可以實現真正的深度克隆。
39 執行緒池使用注意事項
- 死鎖
任何多執行緒程式都有死鎖的風險,最簡單的情形是兩個執行緒AB,A持有鎖1,請求鎖2,B持有鎖2,請求鎖1。(這種情況在mysql的排他鎖也會出現,不會資料庫會直接報錯提示)。執行緒池中還有另一種死鎖:假設執行緒池中的所有工作執行緒都在執行各自任務時被阻塞,它們在等待某個任務A的執行結果。而任務A卻處於佇列中,由於沒有空閒執行緒,一直無法得以執行。這樣執行緒池的所有資源將一直阻塞下去,死鎖也就產生了。
- 系統資源不足
如果執行緒池中的執行緒數目非常多,這些執行緒會消耗包括記憶體和其他系統資源在內的大量資源,從而嚴重影響系統性能。
- 併發錯誤
執行緒池的工作佇列依靠wait()和notify()方法來使工作執行緒及時取得任務,但這兩個方法難以使用。如果程式碼錯誤,可能會丟失通知,導致工作執行緒一直保持空閒的狀態,無視工作佇列中需要處理的任務。因為最好使用一些比較成熟的執行緒池。
- 執行緒洩漏
使用執行緒池的一個嚴重風險是執行緒洩漏。對於工作執行緒數目固定的執行緒池,如果工作執行緒在執行任務時丟擲RuntimeException或Error,並且這些異常或錯誤沒有被捕獲,那麼這個工作執行緒就異常終止,使執行緒池永久丟失了一個執行緒。(這一點太有意思)
另一種情況是,工作執行緒在執行一個任務時被阻塞,如果等待使用者的輸入資料,但是使用者一直不輸入資料,導致這個執行緒一直被阻塞。這樣的工作執行緒名存實亡,它實際上不執行任何任務了。如果執行緒池中的所有執行緒都處於這樣的狀態,那麼執行緒池就無法加入新的任務了。
- 任務過載
當工作執行緒佇列中有大量排隊等待執行的任務時,這些任務本身可能會消耗太多的系統資源和引起資源缺乏。
綜上所述,使用執行緒池時,要遵循以下原則:
- 如果任務A在執行過程中需要同步等待任務B的執行結果,那麼任務A不適合加入到執行緒池的工作佇列中。如果把像任務A一樣的需要等待其他任務執行結果的加入到佇列中,可能造成死鎖
-
如果執行某個任務時可能會阻塞,並且是長時間的阻塞,則應該設定超時時間,避免工作執行緒永久的阻塞下去而導致執行緒洩漏。在伺服器才程式中,當執行緒等待客戶連線,或者等待客戶傳送的資料時,都可能造成阻塞,可以通過以下方式設定時間:
呼叫ServerSocket的setSotimeout方法,設定等待客戶連線的超時時間。
對於每個與客戶連線的socket,呼叫該socket的setSoTImeout方法,設定等待客戶傳送資料的超時時間。
- 瞭解任務的特點,分析任務是執行經常會阻塞io操作,還是執行一直不會阻塞的運算操作。前者時斷時續的佔用cpu,而後者具有更高的利用率。預計完成任務大概需要多長時間,是短時間任務還是長時間任務,然後根據任務的特點,對任務進行分類,然後把不同型別的任務加入到不同的執行緒池的工作佇列中,這樣就可以根據任務的特點,分配調整每個執行緒池
- 調整執行緒池的大小。執行緒池的最佳大小主要取決於系統的可用cpu的數目,以及工作佇列中任務的特點。假如一個具有N個cpu的系統上只有一個工作佇列,並且其中全部是運算性質(不會阻塞)的任務,那麼當執行緒池擁有N或N+1個工作執行緒時,一般會獲得最大的cpu使用率。
如果工作佇列中包含會執行IO操作並經常阻塞的任務,則要讓執行緒池的大小超過可用 cpu的數量,因為並不是所有的工作執行緒都一直在工作。選擇一個典型的任務,然後估計在執行這個任務的工程中,等待時間與實際佔用cpu進行運算的時間的比例WT/ST。對於一個具有N個cpu的系統,需要設定大約N*(1+WT/ST)個執行緒來保證cpu得到充分利用。
當然,cpu利用率不是調整執行緒池過程中唯一要考慮的事項,隨著執行緒池工作數目的增長,還會碰到記憶體或者其他資源的限制,如套接字,開啟的檔案控制代碼或資料庫連線數目等。要保證多執行緒消耗的系統資源在系統承受的範圍之內。
- 避免任務過載。伺服器應根據系統的承載能力,限制客戶併發連線的數目。當客戶的連線超過了限制值,伺服器可以拒絕連線,並進行友好提示,或者限制佇列長度.