
hadoop筆記1-MR執行過程
MR執行過程包括Map、Shuffler、Reduce,其中Map、Reduce及Shuffler中的分割槽、合併、排序是可以允許程式設計師程式設計參與的。
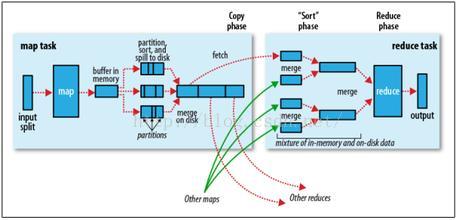
1、Map階段。
split-----map----partition sort and spill to disk------combine。
1)split的目的是應一個原始檔案分成多個檔案,分別交由不同的map節點處理,檔案塊大小由block size、max size、min size,在hadoop1版本的計算方式是spiltSize = max(minsize,max(blockSize,goalSize));在hadoop2版本中的計算方式為spiltSize
= max(minsize,max(blockSize,maxSize))
總結:新版本確定檔案塊大小時不再考慮maptask任務的個數,而有配置中的mapred.max.split.size代替。
2)map
3)partition sort and spill to disk
每個map任務計算的結果首先寫到記憶體中,當超過閾值(預設100M)時將啟動一個執行緒將資料內容溢寫到磁碟上,在溢寫的過程中需要指定每個map輸出的鍵值對對應的reduce編號,即分割槽,預設的分割槽演算法是使用map的key物件的hashcode模reduce個數,該方式不能保證負載均衡,重寫Partition類的getPartition方法可自定義分割槽方式,除分割槽外,該過程還要經歷排序過程,預設的排序是按ascii碼排序,可實現WritableComparable介面的compare方法。
4)combine。
每個map任務執行過程中有可能會溢寫生成多個檔案,而map任務結束後需要交結果傳到reduce任務節點,為提高效率需在網路傳輸檔案前將多個小檔案合併成大檔案,combine是map節點本地reduce過程。
2、Reduce階段
merge----sort----reduce-----output
在正式執行Reduce過程前,需要做一些預處理,首先將不同map節點傳輸過來的檔案合併,然後排序,排序同map階段。