Spark基礎轉換及行動操作(python實驗)
注意:實驗前先引入包from pyspark.context import SparkContext ,還需配置 sc = SparkContext('local', 'test') ,然後才能用sc做操作。
一、常見的轉換操作
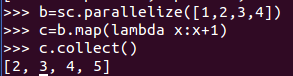
1、map() : 將函式應用於RDD中的每個元素,將返回值構成新的RDD
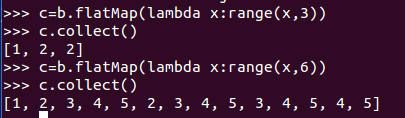
2、flatMap() :將函式應用於RDD 中的每個元素,將返回的迭代器的所有內容構成新的RDD。通常用來切分單詞(以[1,2,3,4]資料集為例)
3、filter() : 返回一個由通過傳給filter()的函式的元素組成的RDD


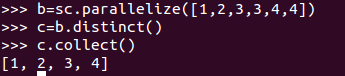
4、distinct() :去重
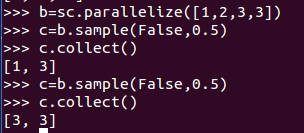
5、sample(withReplacement, fraction, [seed]) :對RDD取樣,以及是否替換(就是隨機取幾個出來,所以每次結果可能不一樣)。
以上是對一個數據集處理,下面是針對兩個以上的資料集
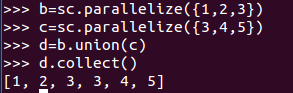
1、union() :生成一個包含兩個RDD 中所有元素的RDD(是所有,不得去重)
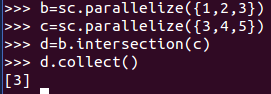
2、intersection() :求兩個RDD 共同的元素的RDD
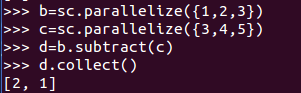
3、subtract() :移除一個RDD 中的內容(例如移除訓練資料)
4、cartesian() : 與另一個RDD 的笛卡兒積

二、常見的行動操作
1、reduce() :它接收一個函式作為引數,這個函式要操作兩個RDD 的元素型別的資料並返回一個同樣型別的新元素。
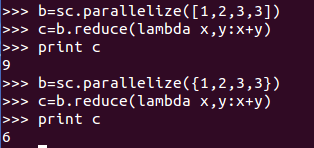
上面例子中,若傳入列表結果為9;若傳入集合結果為6,這是因為python集合會去重了才作為引數傳入計算。
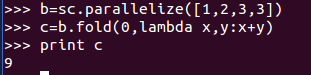
2、fold() :它和reduce() 類似,接收一個與reduce() 接收的函式簽名相同的函式,再加上一個“初始值”來作為每個分割槽第一次呼叫時的結果
3、collect() :返回RDD中的所有元素
注意:使用collect()要求資料不是很大,所有資料都必須能一同放入單臺機器的記憶體中,常用於單元測試中。
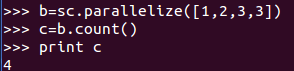
4、count() :RDD 中的元素個數
5、countByValue():各元素在RDD 中出現的次數
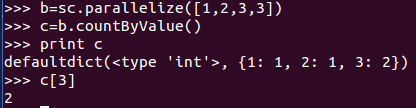
實驗得知,python返回的是一個字典,通過鍵可以獲取對應次數。
6、take(num) :從RDD中返回num個元素
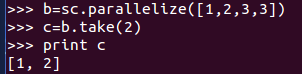
7、top(num) :從RDD中返回最前面的num個元素
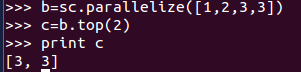
8、takeOrdered(num):函式用於從RDD中,按照預設(降序)或者指定的排序規則,返回前num個元素。
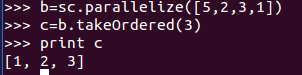
9、takeSample(withReplacement, num, [seed]):從RDD中返回任意一些元素
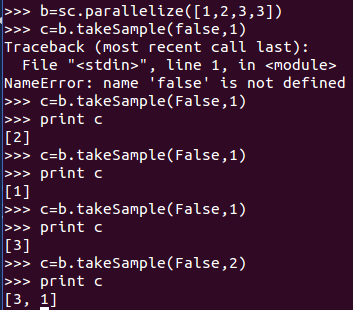
10、aggregate(zeroValue)(seqOp, combOp):和reduce() 相似,但是通常返回不同型別的函式
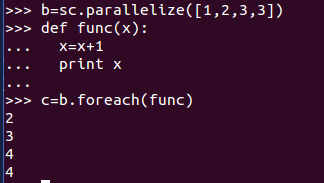
11、foreach(func):對RDD中的每個元素使用給定的函式