
【PyTorch】PyTorch進階教程一
阿新 • • 發佈:2019-01-29
前面介紹了PyTorch的一些基本用法,從這一節開始介紹Pytorch在深度學習中的應用。在開始介紹之前,首先熟悉一下常用的概念和層。
class torch.nn.Module
- 是所有神經網路模組的基類,自定義的網路模組必須繼承此模組
- 必須重寫forward方法,也即前傳模組
舉例:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1 在前面的線性迴歸和邏輯迴歸中同樣用到了此模組,用法也是類似。
class torch.nn.Sequential(*args)
- 多個模組按照它們傳入建構函式的順序被加入到網路中去
舉例:
# Example of using Sequential
model = nn.Sequential(
nn.Conv 2D Convolution
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)其中
- in_channels 為輸入資料通道數
- out_channels 為輸出資料通道數
- kernel_size kernel大小
其餘幾個引數跟caffe一樣。
2D Normalization
class torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)其中
- num_features 為輸入資料的通道數
BatchNorm2d計算的是每個通道上的歸一化特徵,公式為
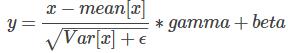
2D Pooling
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)其中
- kernel_size 為kernel大小
其餘引數和caffe一樣。
pooling之後的特徵圖大小計算方式為
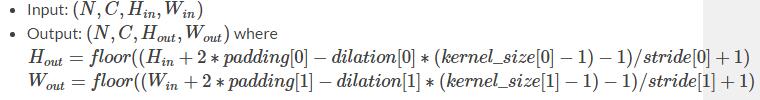
convolutional_neural_network
接下來就是見證奇蹟的時刻,讓我們來看看一個簡單的卷積神經網路是如何構建的。
首先和前面幾節一樣載入資料
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.autograd import Variable
# Hyper Parameters
num_epochs = 5
batch_size = 100
learning_rate = 0.001
# MNIST Dataset
train_dataset = dsets.MNIST(root='./data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = dsets.MNIST(root='./data/',
train=False,
transform=transforms.ToTensor())
# Data Loader (Input Pipeline)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)構建卷積神經網路,兩個卷積層,一個線性層。
# CNN Model (2 conv layer)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7*7*32, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
cnn = CNN()定義loss和優化演算法。
# Loss and Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate)開始訓練。
# Train the Model
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = Variable(images)
labels = Variable(labels)
# Forward + Backward + Optimize
optimizer.zero_grad()
outputs = cnn(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f'
%(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.data[0]))測試。
#有BN層或drop層時需加上cnn.eval(),因為計算方式不一樣,可以參考caffe原始碼。
# Test the Model
cnn.eval() # Change model to 'eval' mode (BN uses moving mean/var).
correct = 0
total = 0
for images, labels in test_loader:
images = Variable(images)
outputs = cnn(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Test Accuracy of the model on the 10000 test images: %d %%' % (100 * correct / total))最終結果為正確率99%,訓練耗時7分鐘左右。按照前一節的做法改為GPU版本後,正確率為99%,訓練耗時34秒。由於載入資料只有一個worker,將DataLoader的num_workers設為4後,訓練耗時17秒。
相較於上一節的兩個線性層,本節的兩個卷積層加上一個線性層的做法在準確率上有所提升,並且引數量更少。上一節隱層的引數量為784x500=392000,這一節卷積層的引數量為16x1x5x5+32x16x5x5=13200。