
為什麼索引可以提高查詢速度
有這麼一個students表:
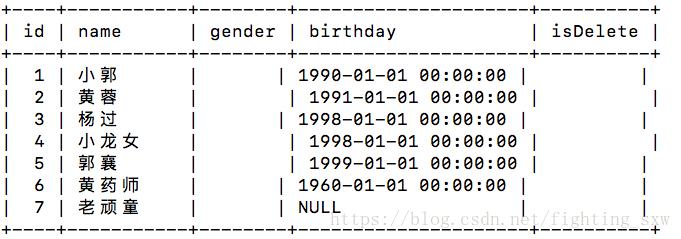
我們執行一條sql語句:select * from students where name=’老頑童’
執行結果:

如果我們沒有為name欄位建立索引,這條sql語句是從頭開始一條一條比較的,比較七次 找到了老頑童所在的這一條資料。
如果此時我們為name欄位加一個索引:create index nameIndex on students(name(20)); 其中nameIndex是索引的名稱,20是欄位的長度。此時可以理解為,將name這一列資料取出來,按照一定的方式重新組織一下(通常是b樹或者雜湊),將name欄位的每一個值,都與其所對應的表中那一條資料的地址做對映,使用雜湊,一次就可以定位到該條資料。
相關推薦
利用SQL索引提高查詢速度
code 創建索引 nbsp 存儲 test 約束 soft 讀取 select 1.合理使用索引 索引是數據庫中重要的數據結構,它的根本目的就是為了提高查詢效率。現在大多數的數據庫產品都采用IBM最先提出的ISAM索引結構。 索引的使用要恰到好處,其使用原則如下:
索引深入理解索引提高查詢速度的原因
1.索引是什麼index索引是幫助資料庫高效獲取資料的資料結構。 是1種資料結構 2.引入索引無論是資料庫查詢資料,還是其他的程式查詢資料利用到的查詢資料必定涉及到相關的查詢演算法。引入:如資料結構的順序表中獲取順序資料一般地我們採用for迴圈來查詢資料此演算法的複雜度為
【轉】使用索引為什麽能提高查詢速度?
更多 地址 sga 數據緩沖 同時 list 磁盤 ID 大量數據 為什麽能夠提高查詢速度? 索引就是通過事先排好序,從而在查找時可以應用二分查找等高效率的算法。 一般的順序查找,復雜度為O(n),而二分查找復雜度為O(log2n)。當n很大時,二者的效率相差及其
資料庫中,索引的作用?為什麼能夠提高查詢速度?(索引的原理)
為什麼能夠提高查詢速度? 索引就是通過事先排好序,從而在查詢時可以應用二分查詢等高效率的演算法。 一般的順序查詢,複雜度為O(n),而二分查詢複雜度為O(log2n)。當n很大時,二者的效率相差及其懸殊。 舉個例子: 表中有一百萬條資料,需要在其中尋找一
索引對提高查詢速度的影響
2009-01-06 10:35 456人閱讀 評論(0)收藏舉報 在進行多個表聯合查詢的時候,使用索引可以顯著的提高速度,剛才用SQLite做了一下測試。 建立三個表: create table t1 (id integer primary key, num
sqlserver重建(rebuild)索引可以提高查詢速度
當隨著表的資料量不斷增長,很多儲存的資料進行了不適當的跨頁(sqlserver中儲存的最小單位是頁,頁是不不可再分的),會產生很多索引的碎片。這時候需要重建索引來提高查詢效能。 如何檢視索引的使用情況: SELECT index_type_desc,alloc_unit_t
什麼情況下需要建立索引? 索引的作用?為什麼能夠提高查詢速度?(索引的原理) 索引有什麼副作用嗎?
為什麼能夠提高查詢速度? 索引就是通過事先排好序,從而在查詢時可以應用二分查詢等高效率的演算法。 一般的順序查詢,複雜度為O(n),而二分查詢複雜度為O(log2n)。當n很大時,二者的效率相差及其懸殊。 舉個例子: 表中有一百萬條資料,需要在其中尋找一條特定id的資料
SQL優化-索引 (三)只要建立索引就能顯著提高查詢速度
2、只要建立索引就能顯著提高查詢速度 事實上,我們可以發現上面的例子中,第2、3條語句完全相同,且建立索引的欄位也相同;不同的僅是前者在fariqi欄位上建立的是非聚合索引,後者在此欄位上建立的是聚合索引,但查詢速度卻有著天壤之別。所以,並非是在任何欄位上簡單地建立索引就
為什麼索引可以提高查詢速度
有這麼一個students表: 我們執行一條sql語句:select * from students where name=’老頑童’ 執行結果: 如果我們沒有為name欄位建立索引,這條sql語句是從頭開始一條一條比較的,比較七次 找到了老頑
處理百萬級以上數據提高查詢速度的方法
pro 需要 存儲空間 and 包括 col sql查詢 意義 調整 1.應盡量避免在 where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。 2.對查詢進行優化,應盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的
處理百萬級以上的數據提高查詢速度的方法
大服務 合並行 系統 int read_only raid select 線程數 總數 處理百萬級以上的數據提高查詢速度的方法: 1.應盡量避免在 where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。
SQL Server 百萬級資料提高查詢速度的方法
1.應儘量避免在 where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。 2.對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 3.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎
oracle 索引提升查詢速度, in 和 exist 效率
做記錄: 今天有一個有153萬條資料的表,發現查詢很慢: select count(y) as transfereeNum,x from t_ast_subject_invest_order where x= '111' and ORDER_STATUS!=1 GROUP BY x;
讓mongoDB也能使用in查詢,提高查詢速度
mongoDB使用in查詢 在mongoDB查詢,是在springboot中使用的mongoDB,結合業務需求,需要查詢多個ID的記錄,改寫了mongoDB的查詢方法,讓其實現了像MySQL中in查詢
sql處理百萬級以上的資料提高查詢速度的方法
處理百萬級以上的資料提高查詢速度的方法: 1.應儘量避免在 where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。 2.對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 3.應
MYSQL處理百萬級以上的資料提高查詢速度的方法
1、應儘量避免在 where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。 2、對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 3、應儘量避免在 where 子句中對欄位進行 nu
MongoDB學習筆記~索引提高查詢效率
回到目錄 索引這個東西大家不會陌生,只要接觸到稍微大一點的資料,都會用到這東西,它可以提升查詢的速度,相當代價就是佔用了更多的儲存空間,這也是正常的,符合“能量守恆定理”,哈哈!今天說的是MongoDB裡的索引,在我進行對500萬資料進行查詢測試時,發現如果你的查詢欄位不加索引,那是相當恐怖的,一個簡單的查
php處理百萬級以上的資料提高查詢速度的方法
1、應儘量避免在 where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。 2、對查詢進行優化,應儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 3、應儘量避免在 where 子句中對欄位進行 n
mysql千萬級資料量根據索引優化查詢速度
(一)索引的作用 索引通俗來講就相當於書的目錄,當我們根據條件查詢的時候,沒有索引,便需要全表掃描,資料量少還可以,一旦資料量超過百萬甚至千萬,一條查詢sql執行往往需要幾十秒甚至更多,5秒以上就已經讓人難以忍受了。 提升查詢速度的方向一是提升硬體(記憶體、cpu、硬碟)
Q:一個數據表中有大量資料,如何提高查詢速度?
一個數據表中有大量資料,如何提高查詢速度? 一、對SQL語句進行優化,主要目的在與讓資料庫引擎使用索引而不是全表掃描進行搜尋 使用索引查詢:應避免造成全表查詢的(索引失效的情況):避免null值查詢。索引列的資料不要大量重複。where語句中or(u