centos系統下通過scrapyd部署python的scrapy
阿新 • • 發佈:2019-01-29
介紹
續接上篇:Python網路爬蟲使用總結,本篇記錄下我學習用scrapyd部署scrapy程式的過程。scrapyd的資料可以參見:scrapyd官網。
安裝scrapyd
安裝後會出現在python的bin目錄下。
安裝命令:pip install scrapyd
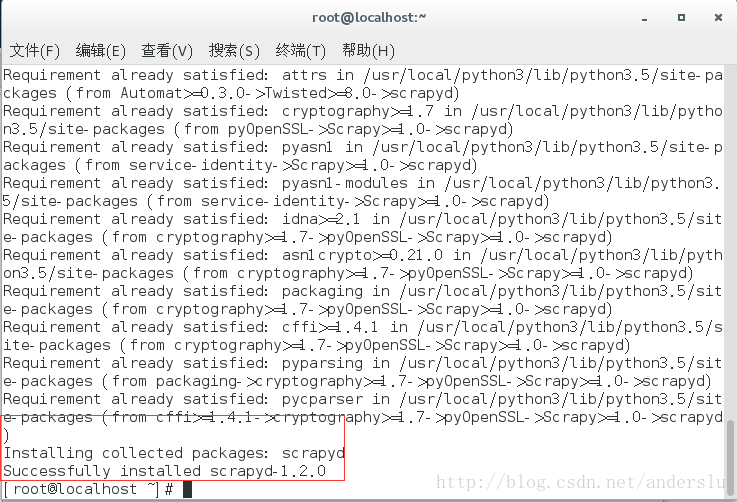
驗證scrapyd安裝
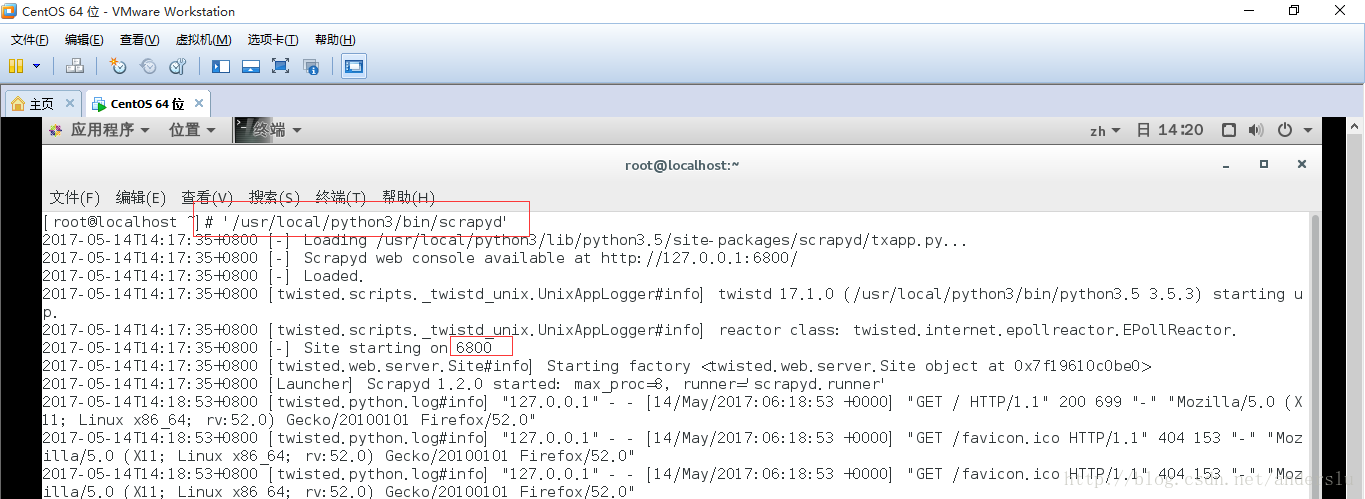
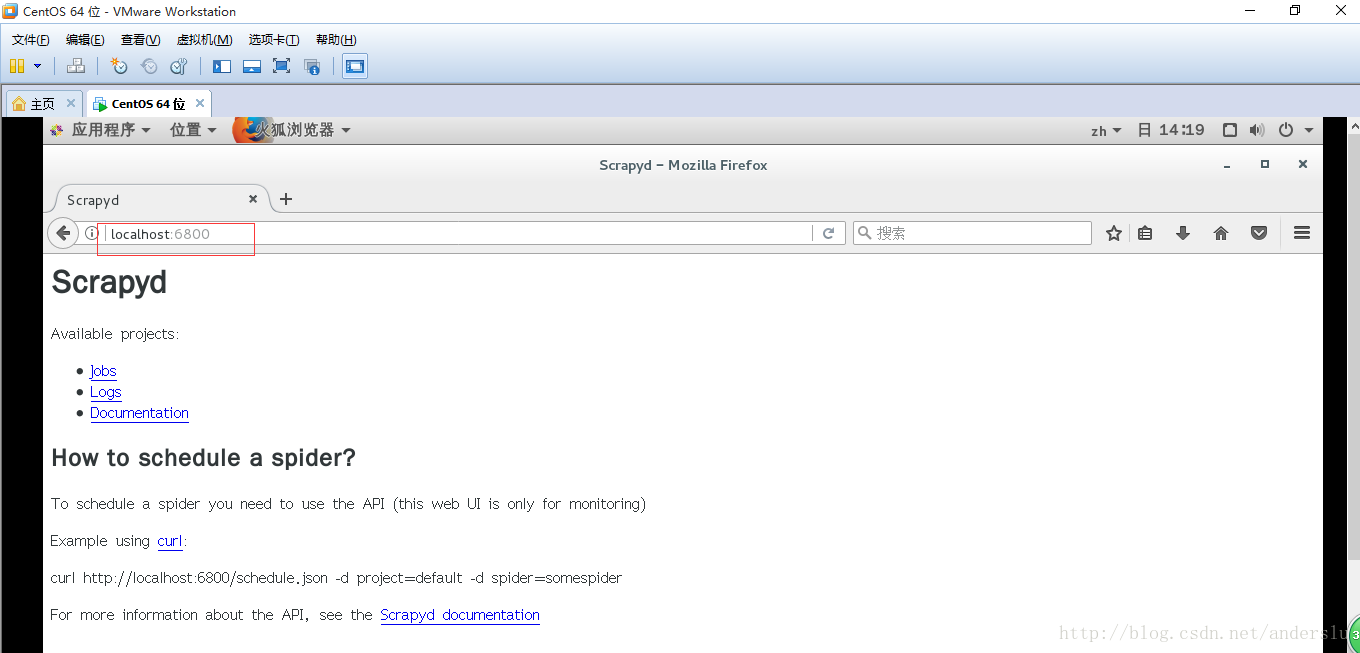
在命令列執行執行scrapyd命令即可啟動scrapyd,執行完命令後如下圖
安裝上傳工具(scrapyd-client)
Scrapyd-client是一個專門用來發布scrapy爬蟲的工具,安裝後會出現在python的bin目錄下。
安裝命令:pip install scrapyd-client
釋出-(拷貝scrapyd-deploy到爬蟲目錄下)
釋出-(修改爬蟲的scapy.cfg檔案)
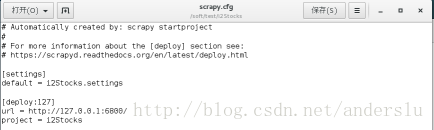
1、去掉url前的註釋符號,這裡url就是你的scrapyd伺服器的網址;
2、deploy:127表示把爬蟲釋出到名為127的爬蟲伺服器上,deploy:後的名字可以自己定義;
3、default=i2Stocks .settings 建議用工程名字。
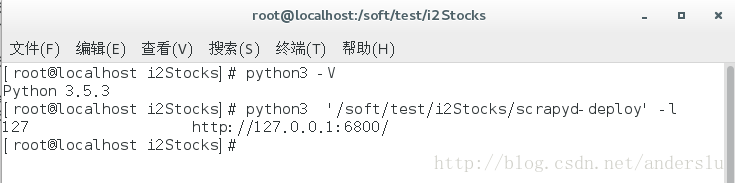
驗證配置:執行如下命令python3 scrapyd-deploy -l
預期結果如下:
釋出-(上傳scrapy到scrapyd)
上傳命令:python3 '/soft/test/i2Stocks/scrapyd-deploy' 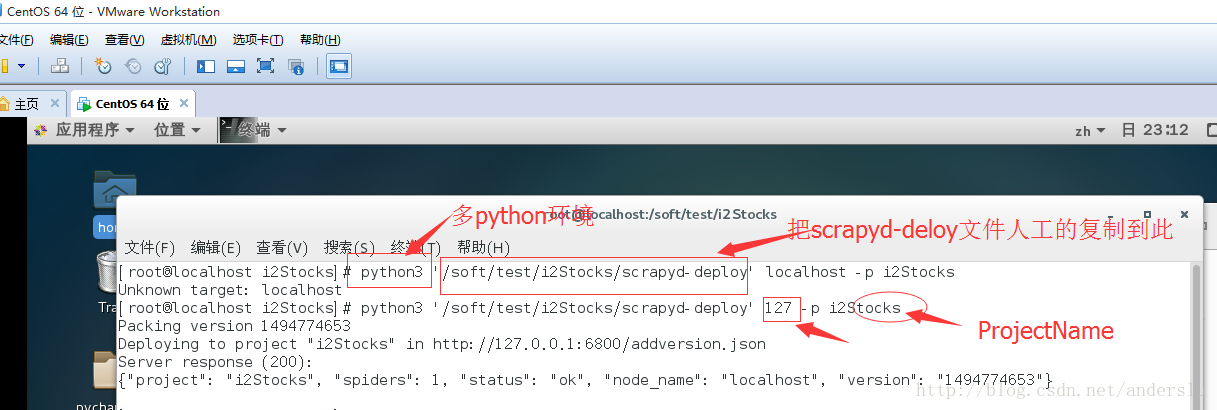
7、使用linux自帶的排程工具執行剛剛釋出的爬蟲
確認當前的linux系統有這個工具curl

curl的介紹請參見:百度百科curl介紹。
釋出job命令:curl http://localhost:6800/schedule.json -d project=i2Stocks -d spider=stocks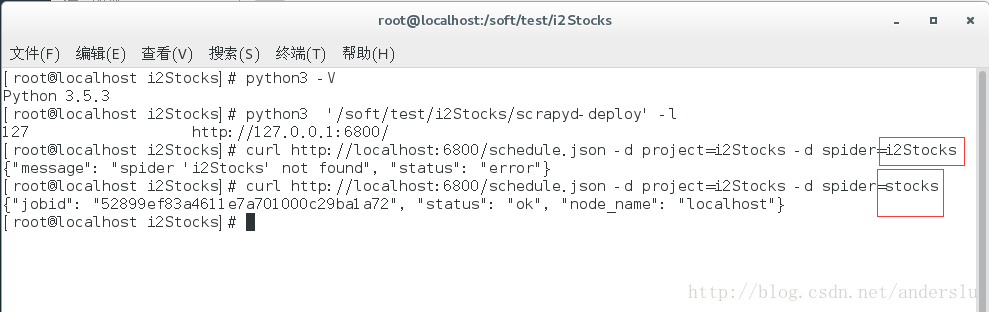
我遇到的問題是spider與工程名稱不一致,檢視spider的名稱,可以通過如下截圖獲取:
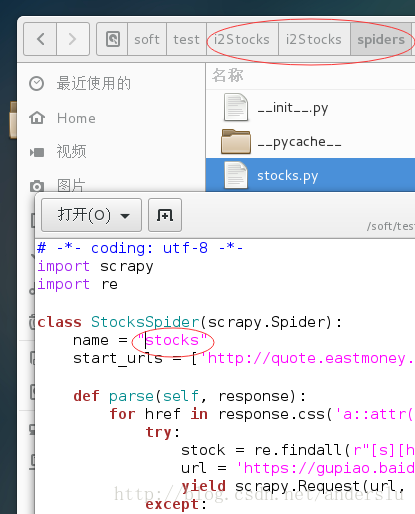
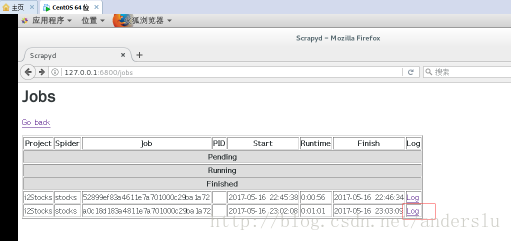
檢視job執行情況及執行日誌方法如下: