
從同步非同步、阻塞非阻塞到5種IO模型
同步非同步、阻塞非阻塞
同步與非同步
同步與非同步在不同的場景下有不同的概念,在IO模型中的同步非同步,主要區別在當任務A呼叫任務B的過程中,程序A是否繼續進行。
如果A等待B的結果,則為同步
如果A不等待B的結果,則為非同步
- 同步狀態下任務A的執行時依賴於任務B的,任務A成功是依賴於成功B的。而非同步模式下兩者是不相關的。
- 非同步的實現方式大概有三種:狀態、通知和回撥
狀態就是任務A去查詢任務B的結果如何
通知就是等任務B執行完成之後通知任務A來實現
回撥就是任務A定義個回撥函式,當任務B結束後會自動呼叫回撥函式
我個人認為通知和回撥的主要區別在於誰佔有主動,以及呼叫的方式不同。
阻塞與非阻塞
阻塞和非阻塞的主要區別在,任務A等待B的結果的過程中,任務A是否會被掛起?
如果A等待的過程中不會掛起,則為阻塞
如果A不等待的過程中不會掛起,則為非阻塞
- 同步阻塞的情況下,任務A會掛起,同步非阻塞的情況下任務A並不掛起。不掛起的情況下任務A保留有響應訊號的能力。
- 非阻塞的情況下並不會導致執行緒切換(只是不強制進行執行緒切換,如果該執行緒的時間片用完還是會切換的),可能效率更高,cpu利用率也更高,但是cpu可能會無意義空轉,這樣又會導致效能降低,所以使用何種方式需要看當前的系統情況。
概念之間的區別
上面兩點似乎被分的很清楚,但是實際上這兩個概念我認為指的是同一件事情,站的角度不同而已,過分的強調概念是無意義的。同步和非同步更多的是兩個任務之間資料通訊方式,而阻塞非阻塞,則是站在當前執行緒自身的角度考慮是否可以在保留程序不掛起而繼續進行任務來看的。
5種IO模型
使用者空間和核心空間
要了解IO模型先要理解一linux類的系統下計算機的IO基本概念,5種IO模型實際上指的都是網路程式設計中的IO,資料從網路讀取後先會被放入核心區,而後從核心區傳入使用者區。
5種IO模型中前四種全部都是同步IO只有非同步IO,這裡的同步和非同步區別在於同步IO會在資料到達核心區的等待過程中進行各種方式的檢查,如果查到了有資料到達了核心區則進行阻塞,因此整個IO的流程是分成2個階段的。而非同步IO的模式是隻有資料完成了從核心區到使用者區的複製之後才有通知。
而同步IO中根據第一階段的不同策略又分成很多的不同模型。
5種IO模型
阻塞式IO
應用程序在呼叫recvfrom,後阻塞直至資料到達使用者區之後才恢復。從應用程序的角度上說這是很合理而高效的,從效能的角度來說可以見上文中的討論,首先他會引起執行緒切換,其次其cpu利用率低。
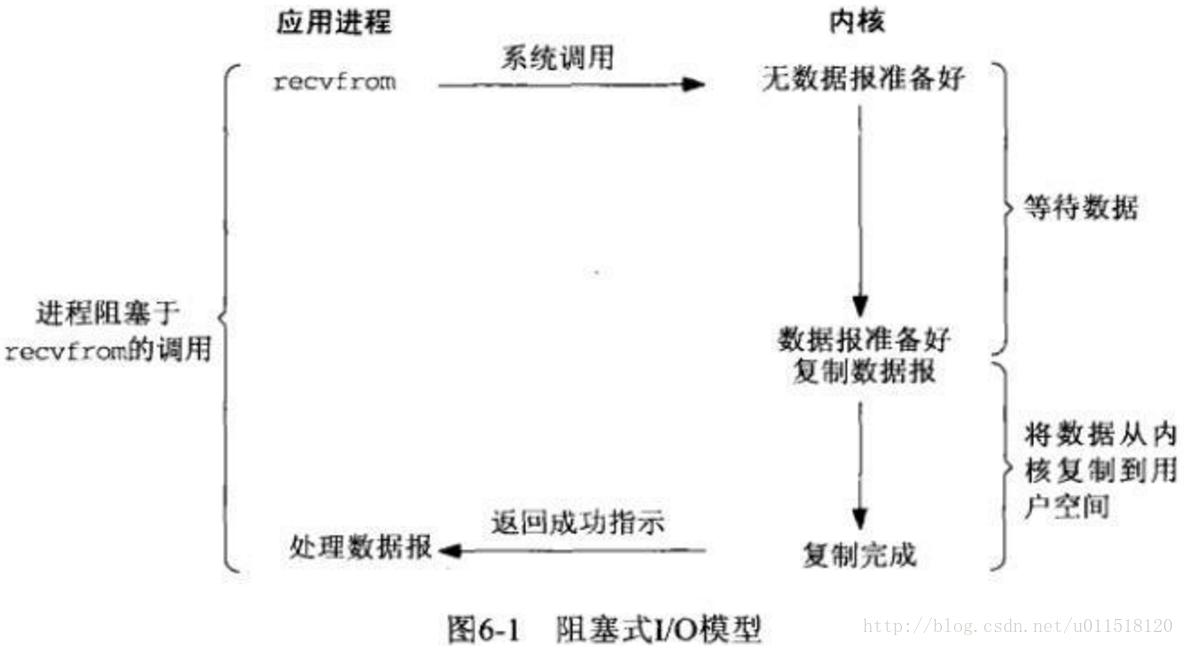
非阻塞式IO
應用程序在呼叫recvfrom的情況下並阻塞,而是返回一個為準備好的返回值,這時候應用程序可以繼續執行,處理一些其他事情。通過這種輪詢的方式查詢是否有資料到達核心區,如果核心區有資料則需要阻塞應用執行緒,等待資料讀取至使用者區之後進行處理。
非阻塞IO看起來很傻,不停的迴圈,但是這樣有兩個好處,第一個是不會強制進行執行緒的切換,執行緒切換的代價是很大的,其次在兩次查詢直接可以用來做一些其他的事情,使用者執行緒保有一定的響應能力。
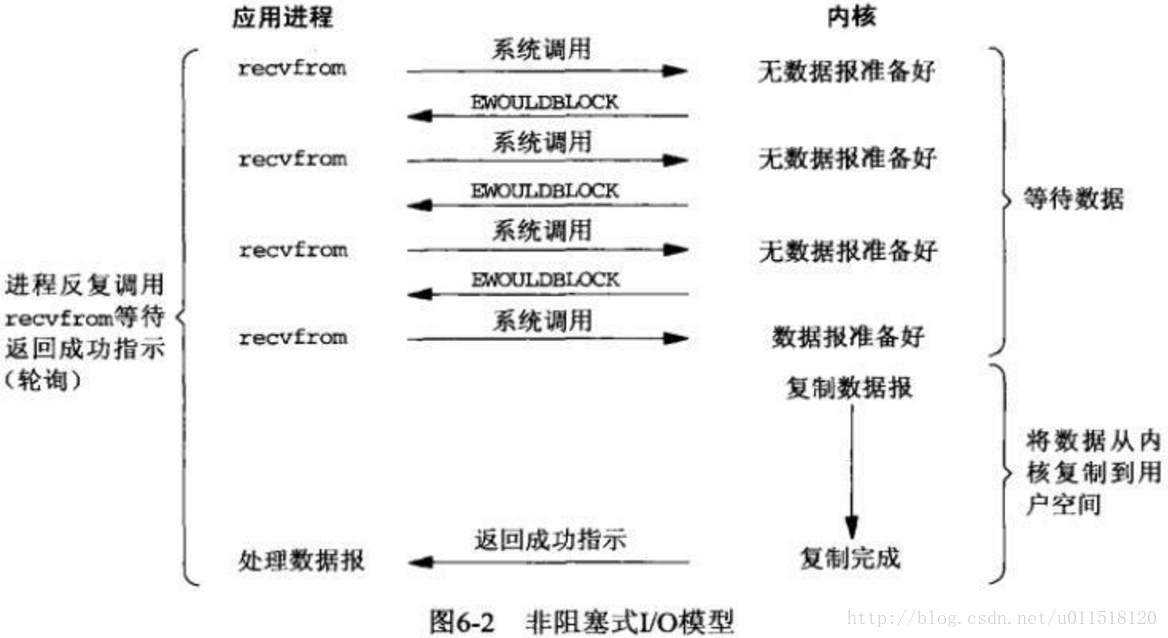
IO複用模型
非阻塞式IO中說到了採用輪詢的方式檢視是否有資料到達核心區,單執行緒的來看這個問題其實很傻,但是網路IO通常不是單個執行緒的。會有很多執行緒同時進行IO讀寫,因此我們可以依次檢測多個IO讀寫任務,如果有某個任務所指定的資料到達則返回這樣效率就高得多了,這就是所謂的IO複用。
其實這是網路模型中最為常用的模式,平時所謂的select、poll和epoll都是IO複用模型,只是細節上略有區別,具體的區別在後面討論。
讀取的兩個階段有2次呼叫2次返回,在第一個階段是很多IO讀取任務共用的,因此效率還是比較高的。
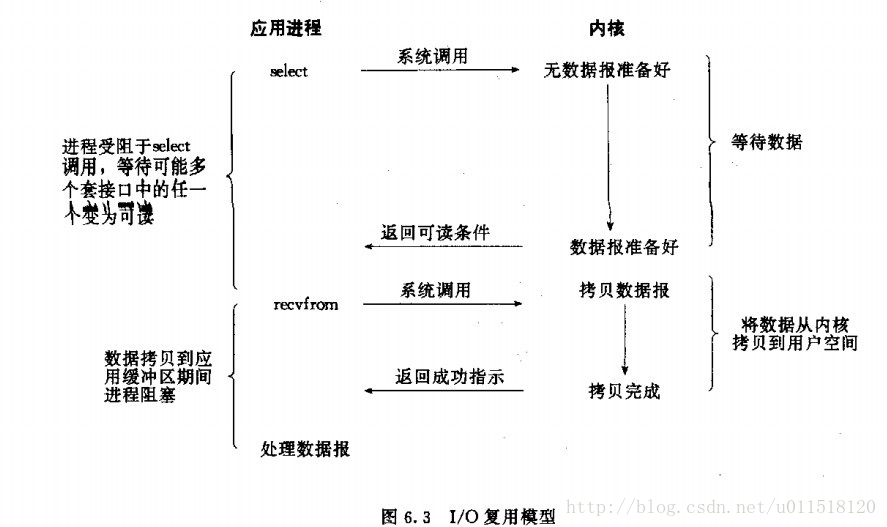
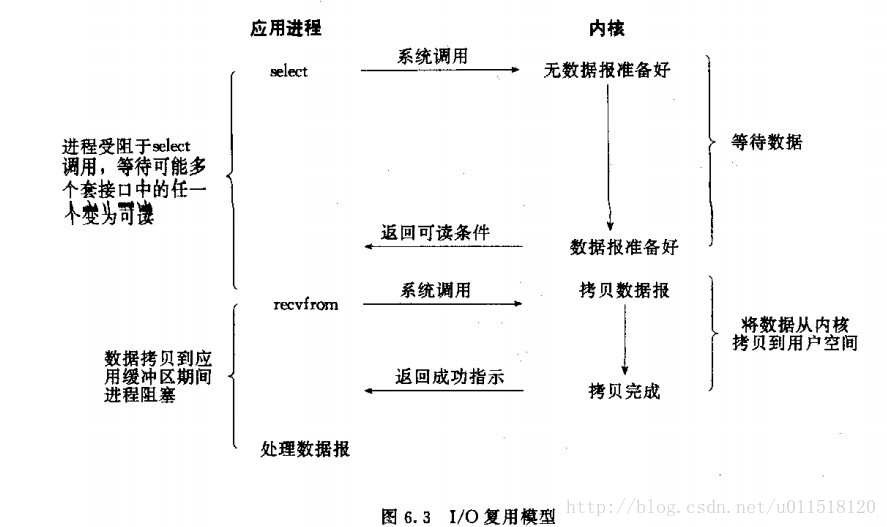
訊號驅動IO
訊號驅動IO我並不是很瞭解,目前的理解是linux類的程式下允許註冊一個訊號處理函式,我們可以用這種方式來處理IO,首先註冊一個訊號處理函式,然後應用程式繼續進行,當有資料到達核心區後,會有一個訊號返回給當前應用程序,當前引用程序進入訊號處理過程,訊號處理過程中會將資料拷貝至使用者區的過程依然是阻塞的。
其實這裡其實看出來,所謂的阻塞、非阻塞和同步、非同步,其實是一件事情,只是在不同的語境下有些細微的區別而已,訊號驅動IO的第一個階段實際上就是典型的非同步通知過程。但是因為其第二個階段需要阻塞,因此整個訊號驅動IO被歸類為同步IO。
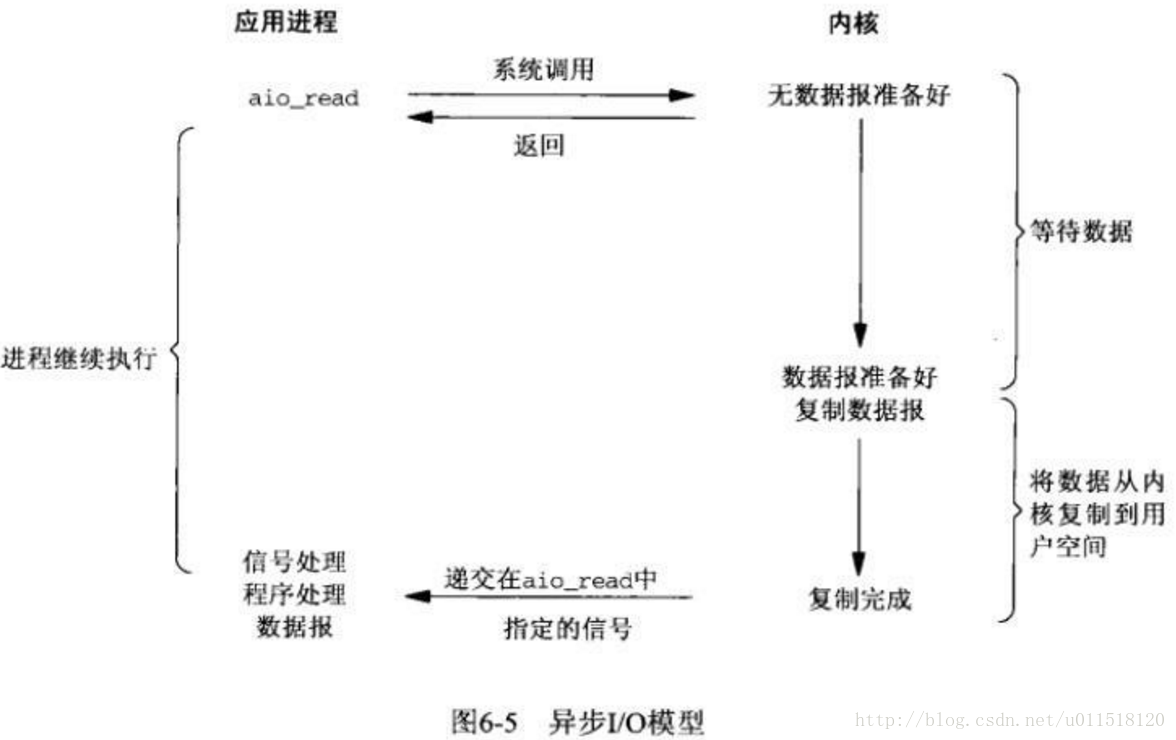
非同步IO
非同步IO的模型其實就是兩個階段均為非同步的方式,使用者程序非同步呼叫函式後,檢測資料的訊號,但是使用者執行緒自身並不掛起,而是繼續執行,當資料完成了2個階段的過程,讀取至使用者區之後才會通知應用程式。
這種方式和阻塞式IO的區別僅僅在於使用者執行緒是否在兩個階段均阻塞。
模型之間的討論
其實對於典型的伺服器環境,基本上都是預設採用IO複用模型的,這一點從模型自身的特性就可以看出。網路IO中即使採用非阻塞的方式其實本身也沒有太大的意義,因為沒有資料到來,那處理程式也沒有其他的事情要做。而且從程式設計的角度上來說,IO複用這種同步的程式設計模式也更利於理解,不會使得程式顯得很混亂。
關於效率問題,在上一章的討論中以及討論過了並不存在非阻塞效率更高的說法,只是在不同場景下有各自優勢而且,但是在絕大多數場景下依然是IO複用更高效。
select、poll、epoll
select
首先select只有一個函式,建立、註冊等待都是一次完成的。
特性
首先將fd_set從使用者空間拷貝到核心區,然後註冊回撥函式 __pollwait。
回撥函式的主要工作就是把當前執行緒掛到裝置的等待佇列中,不同的裝置有不同的等待佇列,如果該裝置有個響應的響應(比如網路中讀取的IO)則會喚醒該裝置等待佇列上的程序,___pollwait方法會返回一個描述讀寫操作是否就行的mask掩碼,根據這個掩碼給fd_set賦值。
如果遍歷fd_set都沒有一個可讀寫的mask掩碼,這呼叫會 schedule_timeout將select執行緒進入睡眠,如果裝置驅動自身資源可讀或者,超時一定時間限都沒人喚醒,則會喚醒當代佇列上的執行緒重新遍歷fd_set判斷有沒有就緒的fd。
缺點
- 每次呼叫select,都需要把fd集合從使用者態拷貝到核心態,這個開銷在fd很多時會很大
- 同時每次呼叫select都需要在核心遍歷傳遞進來的所有fd,這個開銷在fd很多時也很大 ,尤其是在連線數量很多,但是活躍連線並不多的情況下。
- select支援的檔案描述符數量太小了,預設是1024(64位系統是2048)
poll
poll和select基本上類似,區別是採用連結串列的形式去組織資料,所以沒有數量限制。但是前兩個問題依然存在
epoll
epoll的實現和上面兩者有很大的不同。
epoll分為三個函式,分別表示建立,註冊和阻塞三個情況。
這樣在註冊時會將epoll的控制代碼從使用者區拷貝到核心區,所以只有一次複製,而不是每次等待都要複製,不存在第一個問題。
epoll為每個fd指定一個回撥函式,當裝置喚醒的時候就會呼叫這個回撥函式,而這個回撥函式會把就緒的fd加入一個就緒連結串列,epoll_wait要做的工作其實就是定期檢視這個連結串列有沒有就緒的fd就好,所以不需要遍歷fd,不存在第二個問題。而且由於不需要遍歷也不存在低活躍連線數量下效率低下的問題。
epoll沒有fd上限,一般1G記憶體可以有10w個連線,與記憶體大小相關,而且可以修改。不存在第三個問題。
此外還有另一種說法,epoll採用mmap記憶體對映技術將核心區與使用者區對映為同一片地方以減少系統複製代價,不清楚具體用在哪裡。
epoll和select、poll之間最主要的區別還是前者基於回撥機制進行響應,而select和poll基於系統呼叫,讓核心遍歷所有fd進行查詢是否有裝置就緒。
epoll本身還分為電平觸發和邊緣觸發
電平觸發(條件觸發)LT模式:就是當fd就緒後進行通知,如果此次通知後沒有操作響應,則下次依然通知,可用在阻塞模式也可以用在非阻塞模式。
邊緣觸發ET模式:就是當fd就緒後進行通知,但是如果此次沒有響應操作,則下次不會通知。但只可以用在非阻塞模式下。
通常來說邊緣觸發效率更高,因為可以減少重複epoll的次數。
java視角的IO模型
BIO
所謂的BIO就是所謂的流,其實現就是阻塞式IO的模式效率本身是很低的。
NIO的非select模式
JAVA NIO中的不用select的情況下,其channel的非阻塞模型是非阻塞式IO。
NIO的select模式
JAVA NIO中的select實現是多路複用IO。底層使用的是poll或epoll。根據不同系統略有不同。
jdk實現(oraclejdk和openjdk)在linux環境下一般是水平觸發的epol(linux kernels>2.6)或者是poll
如果想使用邊緣出發的epoll可以使用netty,而且暴露了更多引數。
AIO
JAVA NIO2種的AIO則是非同步IO模型。
Windows上用的是IOCP是典型的非同步IO模型。
linux下並沒有真正意義上的AIO。
netty的5.X版本中似乎希望實現真正的AIO但是這個版本被廢棄了。
AIO用處實際上並不大遠不如IO複用模型成熟有效。
參考資料: