《機器學習實戰》學習筆記——K-近鄰演算法(KNN)(二)海倫約會網站匹配實戰
阿新 • • 發佈:2019-01-29
《機器學習實戰》中KNN演算法例項一:關於這個實戰的故事背景可以搜尋“海倫 約會網站”基本上就可以瞭解。
這個實驗的目的是根據已有的海倫整理出來的約會物件的資料和海倫對約會物件的評價,構造分類器,使對新的約會物件進行自動分類(不喜歡的人,魅力一般的人,極具魅力的人)。
資料準備
海倫準備的約會資料datingTestSet.txt,我已上傳github
我們可以先看一下截圖:
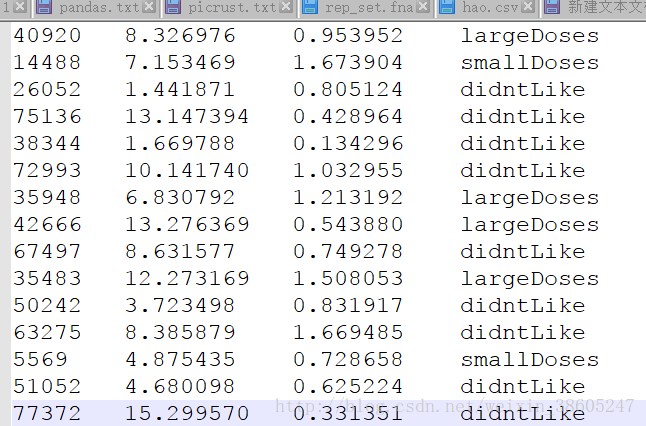
檔案一共有四列,每一行為一個約會物件的資訊(“每年獲得的飛行常客里程數”,“玩視訊遊戲所消耗的時間百分比”,“每週消費的冰激凌公斤數”),最後一列是海倫對他的評價。
那麼得到資料後,我們從下面幾個方面來處理資料,幫助海倫來預測約會物件是否合適:
1.先將文字的資料檔案轉換為NumPy的解析程式
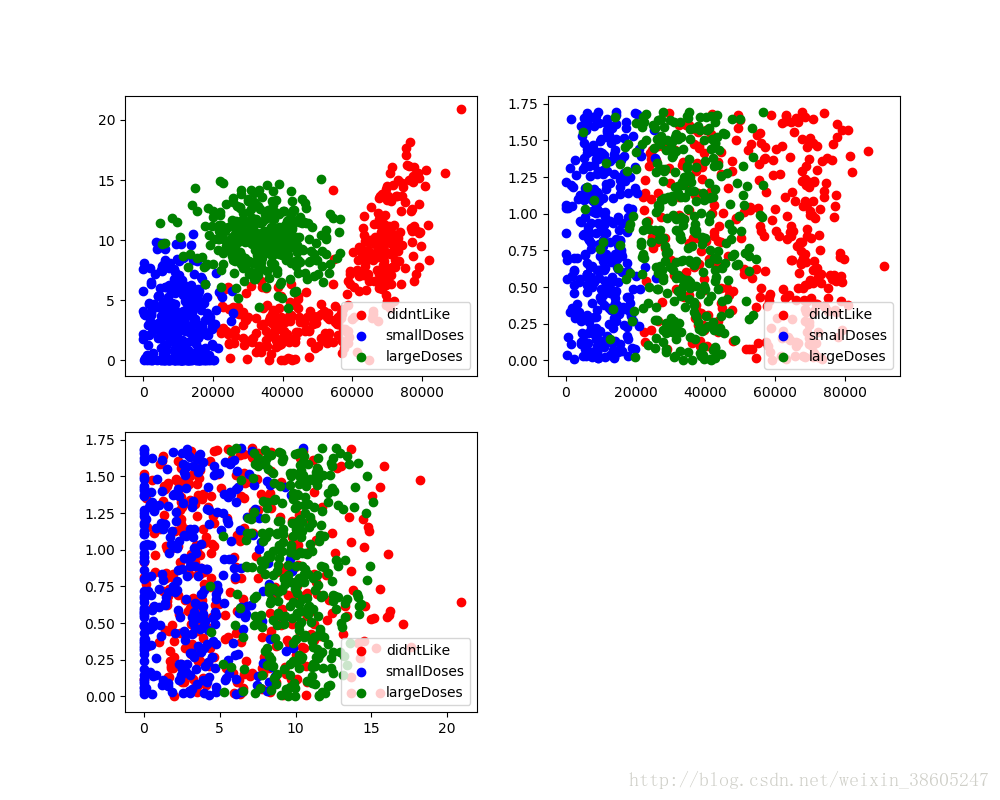
2.分析資料,將資料視覺化
3.準備資料:歸一化數值
4.測試分類器,計算準確率
5.使用演算法,對新的約會物件進行預測
將文字的資料檔案轉換為NumPy的解析程式
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberofLines = len(arrayOLines) #計算檔案總行數
returnMat = np.zeros((numberofLines,3))
#np.zeros((m,n)) 建立m行,n列的由0填充的矩陣
classLabelVector = []
#記錄海倫對每一個約會物件的評價
index = 0
for 分析資料,將資料視覺化
根據資料,我們選用散點圖。
#根據上面建立的函式,我們可以呼叫並得到資料矩陣
datingDataMat,datingLabels = file2matrix("datingTestSet.txt")
index = 0
index_1 = []
index_2 = []
index_3 = []
for i in datingLabels:
if i == 1:
index_1.append(index)
elif i == 2:
index_2.append(index)
elif i == 3:
index_3.append(index)
index +=1
type_1 = datingDataMat[index_1,:]
type_2 = datingDataMat[index_2,:]
type_3 = datingDataMat[index_3,:]
fig = plt.figure()
ax = fig.add_subplot(111)
type_1 = ax.scatter(type_1[:,1],type_1[:,2],c="red")
type_2 = ax.scatter(type_2[:,1],type_2[:,2],c="blue")
type_3 = ax.scatter(type_3[:,1],type_3[:,2],c="green")
plt.legend((type_1, type_2, type_3), ("didntLike","smallDoses","largeDoses"),loc=4)
plt.show()