
Tensorflow GPU訓練過程中遇到的問題總結
阿新 • • 發佈:2019-01-29
錯誤型別:CUDA_ERROE_OUT_OF_MEMORY
GPU的全部memory資源不能全部都申請,可以通過修改引數來解決:
在session定義前增加
config = tf.ConfigProto(allow_soft_placement=True)
#最多佔gpu資源的70%
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
#開始不會給tensorflow全部gpu資源 而是按需增加
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
當Host有多個GPU時,如何控制有多少個GPU在工作?
通過配置環境CUDA_VISIBLE_DEVICES來實現
在程式碼中:
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
os.environ["CUDA_VISIBLE_DEVICES"] = 2
在命令列中:
CUDA_VISIBLE_DEVICES=0 python train.py 注意=號兩邊不能有空格
GPU訓練一段時間之後,溫度接近100度,然後罷工,提示GPU從總線上消失。
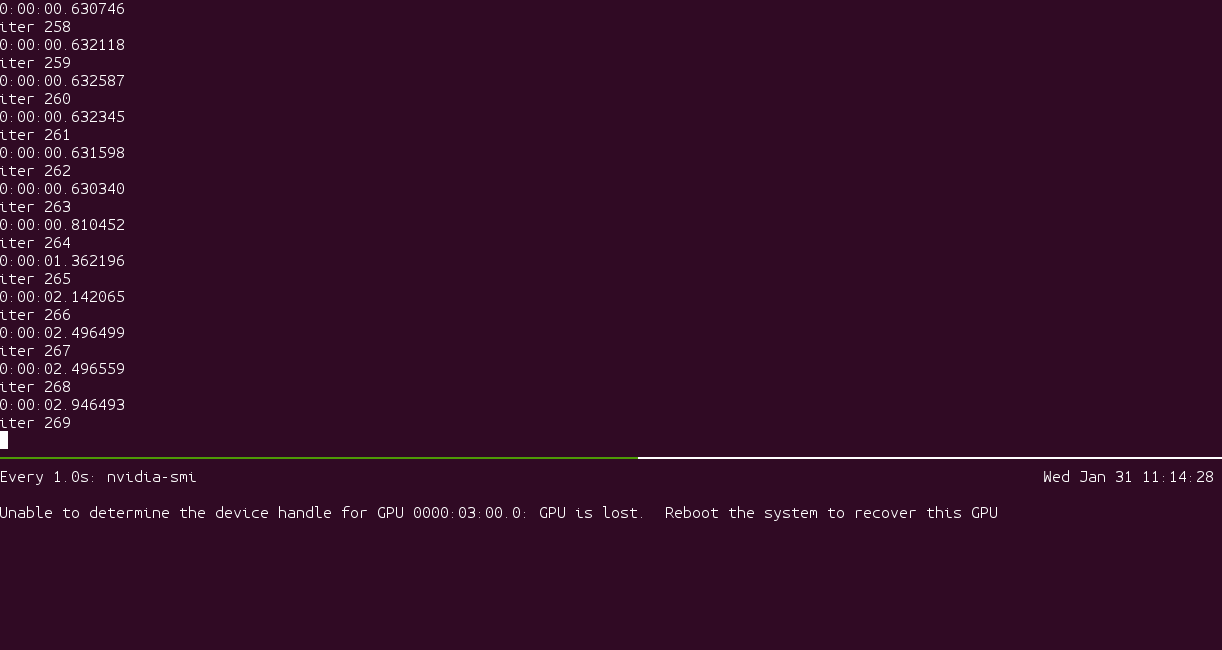
知道目前為止,也沒有找到好的辦法。