
黑馬程式設計師--python高階程式設計
第二部分:高階進階
傳值傳引數筆試題
def extendList(val,list=[]):
list.append(val)
return list
list1=extendList(10)
list2=extendList(123,['a','b','c'])
list3=extendList('a')
print(list1)
print(list2)
print(list3)
#---------------------------------
[10, 'a']
['a', 'b', 'c', 123]
[10, 'a']list2呼叫時,初始化並傳入了2列表引數,list1和list3list2呼叫時沒有引數,使用了extentdList預設初始化的list,(是同一地址,且列表可變
1、模組呼叫
A.import math
B.from 模組名 import 函式名1,函式名2....
C.from modname import name1[, name2[, ... nameN]]
from fib import fibonacci
注意,不會把整個fib模組匯入到當前的名稱空間中,它只會將fib裡的fibonacci單個引入
D.as 取別名
import time as tt
每個Python檔案都可以作為一個模組,模組的名字就是檔案的名字。 xxx.py
包將有聯絡的模組組織在一起,即放到同一個資料夾下,並且在這個資料夾建立一個名字為__init__.py 檔案,那麼這個資料夾就稱之為包,__init__.py 控制著包的匯入行為
object是頂級基類
type也是一個類,同時type也是一個物件

魔法函式一覽
字串表示: __repr__:開發模式下呼叫 __str__:print呼叫 集合序列相關: __len__ __getitem__ __setitem__ __delitem__ __containes__ 迭代相關: __iter__ __next__ 可呼叫: __call__ 上下文管理器: __enter__ __exit__ 數值轉換: __abs__ __bool__ __int__ __float__ __hash__ __index__ 元類相關: __new__ __init__ 屬性相關: __getattr__、__setattr__ __getattribute__、setattribute__ __dir__ 屬性描述: __get__、__set__、__delete__ …………
鴨子型別
#函式類似
class Cat(object):
def say(self):
print('I am a cat')
class Dog(object):
def say(self):
print('I am a dog')
animals = [Dog,Cat]
for animal in animals:
animal().say()type和isinstance的區別
'''
sinstance() 與 type() 區別:
type() 不會認為子類是一種父類型別,不考慮繼承關係。
isinstance() 會認為子類是一種父類型別,考慮繼承關係。
如果要判斷兩個型別是否相同推薦使用 isinstance()。
'''
class A(object):
pass
class B(A):
pass
b = B()
print(isinstance(b, B)) # True
print(isinstance(b, A)) # True
print(type(b)) #<class '__main__.B'>
print(type(b) is B) # True
print(type(b) is A) # False+=本質會呼叫MutableSequence類下的魔法函式__iadd__方法,該方法有呼叫了extend方法。
a = [1, 2, 3]
c = a + (4, 5, 6)
print(c) # TypeError: can only concatenate list (not "tuple") to list
a = [1, 2, 3]
a += (4, 5, 6)
print(a) # [1, 2, 3, 4, 5, 6]生成器
ge = (i for i in range(1, 21) if i % 2 == 1)
print(ge) # <generator object <genexpr> at 0x000001F09B0EEFC0>
print(type(ge)) # <class 'generator'>
print(list(ge)) # [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]python核心程式設計
在Python中,這種一邊迴圈一邊計算的機制,稱為生成器:generator。
1、 要建立一個生成器,有很多種方法。第一種方法很簡單,只要把一個列表生成式的 [ ] 改成 ( )
L = [ x*2 for x in range(5)]
L
[0, 2, 4, 6, 8]
In [17]: G = ( x*2 for x in range(5))
G
Out[18]: <generator object <genexpr> at 0x7f626c132db0>
要打印出來, for 迴圈來迭代它
2、建立生成器,generator非常強大。如果推算的演算法比較複雜,用類似列表生成式的 for 迴圈無法實現的時候,還可以用函式來實現。
In [30]: def fib(times):
....: n = 0
....: a,b = 0,1
....: while n<times:
....: yield b
....: a,b = b,a+b
....: n+=1
....: return 'done'
....: 生成器的特點:
- 節約記憶體
- 迭代到下一次的呼叫時,所使用的引數都是第一次所保留下的,即是說,在整個所有函式呼叫的引數都是第一次所呼叫時保留的,而不是新建立的
- 凡是可作用於 for 迴圈的物件都是 Iterable 型別;
- 凡是可作用於 next() 函式的物件都是 Iterator 型別
- 集合資料型別如 list 、 dict 、 str 等是 Iterable 但不是 Iterator ,不過可以通過 iter() 函式獲得一個 Iterator 物件。
迭代器
迭代是訪問集合元素的一種方式。迭代器是一個可以記住遍歷的位置的物件。迭代器物件從集合的第一個元素開始訪問,直到所有的元素被訪問完結束。迭代器只能往前不會後退。
L = ['Adam', 'Lisa', 'Bart', 'Paul']
for index, name in enumerate(L):
print index+1, '-', name以直接作用於 for 迴圈的資料型別有以下幾種:
一類是集合資料型別,如 list 、 tuple 、 dict 、 set 、 str 等;
一類是 generator ,包括生成器和帶 yield 的generator function。
這些可以直接作用於 for 迴圈的物件統稱為可迭代物件: Iterable 。
一個閉包的實際例子:
內部函式對外部函式作用域裡變數的引用(非全域性變數),則稱內部函式為閉包。
def line_conf(a, b):
def line(x):
return a*x + b
return line
line1 = line_conf(1, 1) #預設賦值,第一次引數被鎖住了
line2 = line_conf(4, 5)
print(line1(5))
print(line2(5))
line1 = line_conf(1, 1) #預設賦值,第一次引數被鎖住了
line2 = line_conf(4, 5)
print(line1(5))
print(line2(5))由於閉包引用了外部函式的區域性變數,則外部函式的區域性變數沒有及時釋放,消耗記憶體概括的講,裝飾器的作用就是為已經存在的物件新增額外的功能。
def w1(func):
def inner():
# 驗證1
# 驗證2
# 驗證3
func()
return inner
@w1
def f1():
print('f1')python直譯器就會從上到下解釋程式碼,步驟如下:
- def w1(func): ==>將w1函式載入到記憶體
- @w1
沒錯, 從表面上看直譯器僅僅會解釋這兩句程式碼,因為函式在 沒有被呼叫之前其內部程式碼不會被執行。
以後業務部門想要執行 f1 函式時,就會執行 新f1 函式,在新f1 函式內部先執行驗證,再執行原來的f1函式,然後將原來f1 函式的返回值返回給了業務呼叫者。
模組修改,要重新載入reload
避免迴圈匯入,雞生蛋,蛋生雞
- is 是比較兩個引用是否指向了同一個物件(引用比較)。深拷貝就返回false
- == 是比較兩個物件是否相等。
淺拷貝:拷貝引用,沒有拷貝內容,地址給了,指向同一地址。
深拷貝:對一個物件所有層次的拷貝,藉助copy.deepcopy模組。內容複製到新記憶體。
列表拷貝可變,新記憶體。元祖不可變,copy.copy()指向同一位置(記憶體)。
垃圾回收
- 小整數[-5,257)共用物件,常駐記憶體
- 單個字元共用物件,常駐記憶體
- 單個單詞,不可修改,預設開啟intern機制,共用物件,引用計數為0,則銷燬
編碼風格正確認知
- 促進團隊合作
- 減少bug處理
- 提高可讀性,降低維護成本
- 有助於程式碼審查
- 養成習慣,有助於程式設計師自身的成長
系統程式設計:程序&&執行緒
程序,能夠完成多工,比如 在一臺電腦上能夠同時執行多個QQ
執行緒,能夠完成多工,比如 一個QQ中的多個聊天視窗
實現方式都是兩種
多工,時間片輪轉,優先順序呼叫。 併發:有處理多工能力,不一定同時。並行:同時處理多工。
fork返回值特殊,生出多程序。fork()呼叫一次,返回兩次,2返回值。
子程序永遠返回0,而父程序返回子程序的ID。,父程序大於0;
多程序中,每個程序中所有資料(包括全域性變數)都各有擁有一份,互不影響
多程序如果是對齊,符合2的n,每人都要fork一次
伺服器程序很多,pid類似身份證,不會同多程序中,每個程序中所有資料(包括全域性變數)都各有擁有一份,互不影響,父程序、子程序執行順序沒有規律,完全取決於作業系統的排程演算法。總程序:2*n 次,一般不超過8次。
multiprocessing模組提供了一個Process類來代表一個程序物件,子程序可以用類來實現
while true 慎用
超級多工,Pool程序池 快取 apply堵塞式
使用多執行緒併發的操作,節約時間,執行順序無關
執行緒共享全域性變數,資料共享容易,列表傳參也共享。程序不能(誕生程序通訊)
os模組建立資料夾,os.mkdir(),print除錯
Queue可以用來解決百分比問題
程序池:
from multiprocessing import Pool
import os,time,random
def worker(msg):
t_start = time.time()
print("%s開始執行,程序號為%d"%(msg,os.getpid()))
#random.random()隨機生成0~1之間的浮點數
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"執行完畢,耗時%0.2f"%(t_stop-t_start))
po=Pool(3) #定義一個程序池,最大程序數3
for i in range(0,10):
#Pool.apply_async(要呼叫的目標,(傳遞給目標的引數元祖,))
#每次迴圈將會用空閒出來的子程序去呼叫目標
po.apply_async(worker,(i,))
print("----start----")
po.close() #關閉程序池,關閉後po不再接收新的請求
po.join() #等待po中所有子程序執行完成,必須放在close語句之後
print("-----end-----")
執行緒:
多執行緒併發的操作,花費時間要短很多
建立好的執行緒,需要呼叫start()方法來啟動
執行緒建立好了一起執行
在多執行緒開發中,全域性變數是多個執行緒都共享的資料,而區域性變數等是各自執行緒的,是非共享的
同步(上鎖,有規律):同步就是協同步調,按預定的先後次序進行執行。如:你說完,我再說。 如程序、執行緒同步,可理解為程序或執行緒A和B一塊配合,A執行到一定程度時要依靠B的某個結果,於是停下來,示意B執行;B依言執行,再將結果給A;A再繼續操作。
非同步:無約定
同步呼叫就是你 喊 你朋友吃飯 ,你朋友在忙 ,你就一直在那等,等你朋友忙完了 ,你們一起去
非同步呼叫就是你 喊 你朋友吃飯 ,你朋友說知道了 ,待會忙完去找你 ,你就去做別的了。
重構:重寫
一個ThreadLocal變數雖然是全域性變數,但每個執行緒都只能讀寫自己執行緒的獨立副本,互不干擾。ThreadLocal解決了引數在一個執行緒中各個函式之間互相傳遞的問題
對於全域性變數,在多執行緒中要格外小心,否則容易造成資料錯亂的情況發生
網路程式設計
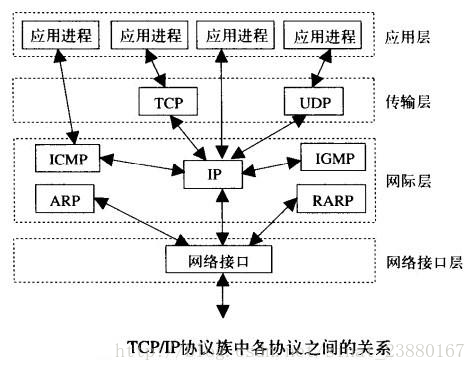
TCP/IP協議族,現實4層,實現不同系統,機器通訊
網際層也稱為:網路層
網路介面層也稱為:鏈路層
一臺擁有IP地址的主機可以提供許多服務,比如HTTP(全球資訊網服務)、FTP(檔案傳輸)、SMTP(電子郵件)等,這些服務完全可以通過1個IP地址來實現。那麼,主機是怎樣區分不同的網路服務呢?顯然不能只靠IP地址,因為IP地址與網路服務的關係是一對多的關係。
埠,標記程序的東西(同臺電腦用pid),不同電腦通訊標識
ip地址:用來在網路中標記一臺電腦的一串數字,比如192.168.1.1;在本地區域網上是惟一的。
IP地址127.0.0.1~127.255.255.255用於迴路測試 網路號+多播號不能用(多播,有些能看有些不能,視訊會議)
聯網裝置都有ip
利用ip地址,協議,埠就可以標識網路的程序了,網路中的程序通訊就可以利用這個標誌與其它程序進行互動
socket ip+埠+協議
迴圈儘可能程式碼少,節約
UDP通訊過程
TFTP客戶端
下載:建立檔案—寫資料—關閉
上傳:
網路通訊過程詳解
Packet Tracer 是由Cisco(著名網路公司,思科)公司釋出的一個輔助學習工具,
為學習思科網路課程的初學者去設計、配置、排除網路故障提供了網路模擬環境。
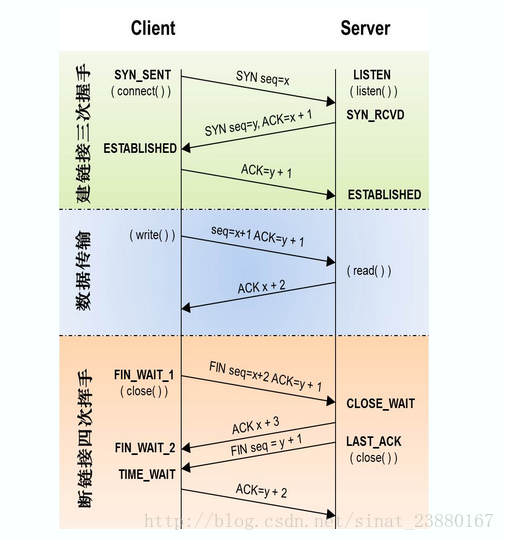
TCP通訊的整個過程,如下圖:
掩碼:二進位制的掩碼與ip按位與,得到網路號,(c類最後位255.255.255.0),3個255表示網路號,0表示主機號
網線只能連2臺電腦(網路多臺資料電訊號錯亂),多臺交換機淘汰了集線器(USB拓展)
路由器(Router)又稱閘道器裝置(Gateway)是用於連線多個邏輯上分開的網路
網絡卡:實體地址,實際地址
預設閘道器:
不在同一網段的pc,需要設定預設閘道器才能把資料傳送過去 通常情況下,都會把路由器預設閘道器
集線器:廣播,交換機:更智慧
tcp規定跨網不能直接通訊,路由器雙網絡卡雙ip,左手右手,可以連線不同網段,
ip地址通訊不會變化,mac地址會變化
ping TTL=128,經過一次路由器減一
cdn分發,各地放置伺服器
arp三方造假
nat:ip 內網和外網能上,路由表地址轉換,只能向外才能對映,自己搭建伺服器不能外網訪問,藉助花生殼。
家庭上網解析
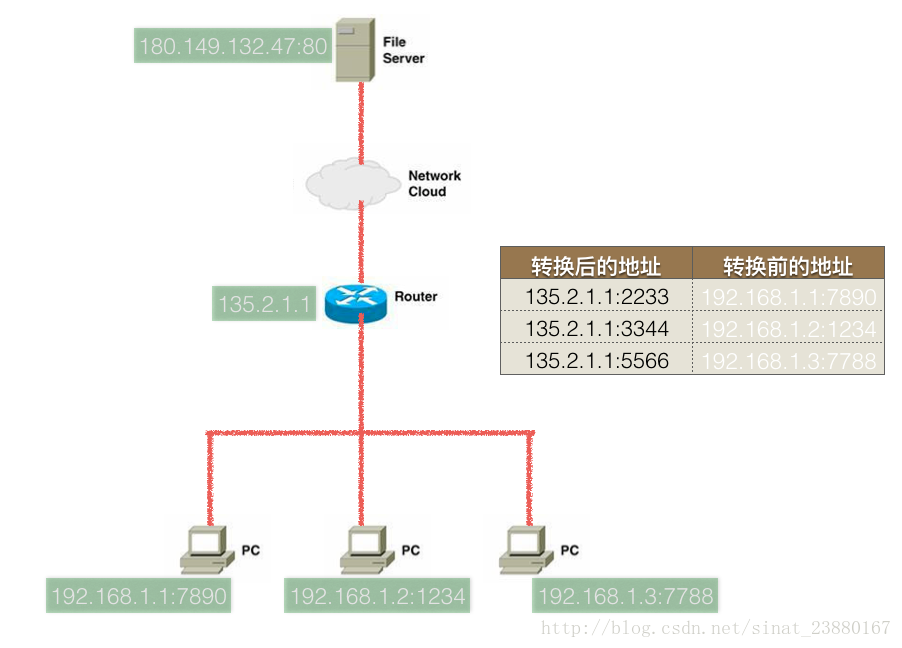
邏輯地址轉換後共用一個路由器,路由器訪問dns,伺服器
正則表示式概述
re.match只匹配字串的開始,如果字串開始不符合正則表示式,則匹配失敗,函式返回None;而re.search匹配整個字串,直到找到一個匹配。(不過可以指定起始位置)
compile 函式用於編譯正則表示式,生成一個正則表示式( Pattern )物件,供 match() 和 search() 這兩個函式使用。
>>>import re
>>> pattern = re.compile(r'\d+') # 用於匹配至少一個數字
>>> m = pattern.match('one12twothree34four') # 查詢頭部,沒有匹配
>>> print (m)日期替換
>>> s = '2017-11-27'
>>> import re
>>> print(re.sub('(\d{4})-(\d{2})-(\d{2})',r'\2/\3/\1', s))
11/27/2017\b 是指匹配一個單詞邊界,也就是指單詞和空格間的位置。
>>> import re
>>> ret = re.findall(r'o\b','hello nano$')
>>> print(ret)
['o', 'o']什麼是 Socket?
Socket又稱"套接字",應用程式通常通過"套接字"向網路發出請求或者應答網路請求,使主機間或者一臺計算機上的程序間可以通訊。
import json
# Python 字典型別轉換為 JSON 物件
data = {
'no': 1,
'name': 'Runoob',
'url': 'http://www.runoob.com'
}
json_str = json.dumps(data)
print("Python 原始資料:", repr(data))
print("JSON 物件:", json_str)
#------------------------------------
Python 原始資料: {'no': 1, 'name': 'Runoob', 'url': 'http://www.runoob.com'}
JSON 物件: {"no": 1, "name": "Runoob", "url": "http://www.runoob.com"}
# 寫入 JSON 資料
with open('data.json', 'w') as f:
json.dump(data, f)
# 讀取資料
with open('data.json', 'r') as f:
data = json.load(f)獲取時間
import time
localtime = time.asctime( time.localtime(time.time()) )
print ("本地時間為 :", localtime)WSGI介面
瞭解了HTTP協議和HTML文件,我們其實就明白了一個Web應用的本質就是:
-
瀏覽器傳送一個HTTP請求;
-
伺服器收到請求,生成一個HTML文件;
-
伺服器把HTML文件作為HTTP響應的Body傳送給瀏覽器;
-
瀏覽器收到HTTP響應,從HTTP Body取出HTML文件並顯示。
所以,最簡單的Web應用就是先把HTML用檔案儲存好,用一個現成的HTTP伺服器軟體,接收使用者請求,從檔案中讀取HTML,返回。Apache、Nginx、Lighttpd等這些常見的靜態伺服器就是幹這件事情的。
如果要動態生成HTML,就需要把上述步驟自己來實現。不過,接受HTTP請求、解析HTTP請求、傳送HTTP響應都是苦力活,如果我們自己來寫這些底層程式碼,還沒開始寫動態HTML呢,就得花個把月去讀HTTP規範。
正確的做法是底層程式碼由專門的伺服器軟體實現,我們用Python專注於生成HTML文件。因為我們不希望接觸到TCP連線、HTTP原始請求和響應格式,所以,需要一個統一的介面,讓我們專心用Python編寫Web業務。
這個介面就是WSGI:Web Server Gateway Interface。
複雜的Web應用程式,光靠一個WSGI函式來處理還是太底層了,我們需要在WSGI之上再抽象出Web框架,進一步簡化Web開發。