
大資料中的使用者畫像
摘要:
使用者畫像(persona)的概念最早由互動設計之父Alan Cooper提出:“Personas are a concrete representation of target users.” 是指真實使用者的虛擬代表,是建立在一系列屬性資料之上的目標使用者模型。隨著網際網路的發展,現在我們說的使用者畫像又包含了新的內涵——通常使用者畫像是根據使用者人口學特徵、網路瀏覽內容、網路...
使用者畫像的含義
使用者畫像(persona)的概念最早由互動設計之父Alan Cooper提出:“Personas are a concrete representation of target users.” 是指真實使用者的虛擬代表,是建立在一系列屬性資料之上的目標使用者模型。隨著網際網路的發展,現在我們說的使用者畫像又包含了新的內涵——通常使用者畫像是根據使用者人口學特徵、網路瀏覽內容、網路社交活動和消費行為等資訊而抽象出的一個標籤化的使用者模型。構建使用者畫像的核心工作,主要是利用儲存在伺服器上的海量日誌和資料庫裡的大量資料進行分析和挖掘,給使用者貼“標籤”,而“標籤”是能表示使用者某一維度特徵的標識。具體的標籤形式可以參考下圖某網站給其中一個使用者打的標籤。
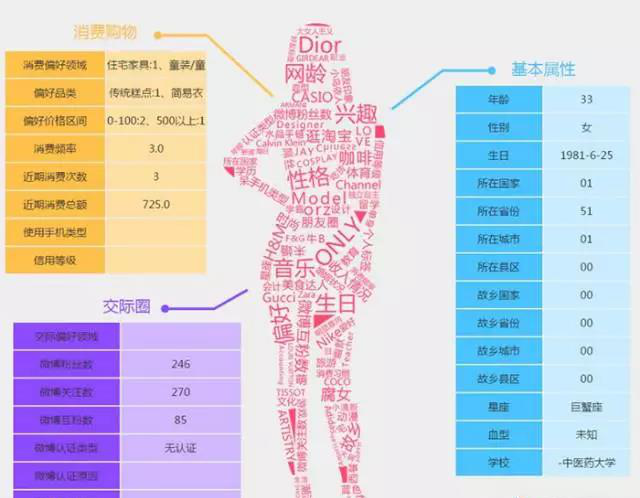
使用者畫像的作用
提取使用者畫像,需要處理海量的日誌,花費大量時間和人力。儘管是如此高成本的事情,大部分公司還是希望能給自己的使用者做一份足夠精準的使用者畫像。
那麼使用者畫像有什麼作用,能幫助我們達到哪些目標呢?
大體上可以總結為以下幾個方面:
- 精準營銷:精準直郵、簡訊、App訊息推送、個性化廣告等。
- 使用者研究:指導產品優化,甚至做到產品功能的私人定製等。
- 個性服務:個性化推薦、個性化搜尋等。
- 業務決策:排名統計、地域分析、行業趨勢、競品分析等。
使用者畫像的內容
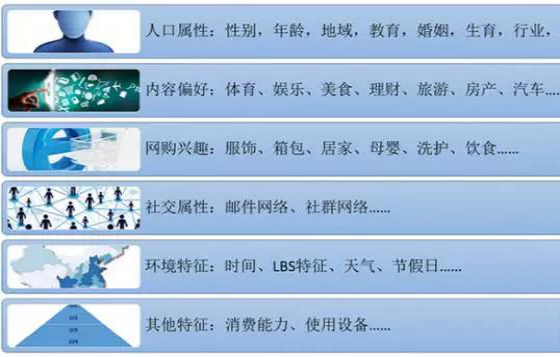
使用者畫像包含的內容並不完全固定,根據行業和產品的不同所關注的特徵也有不同。對於大部分網際網路公司,使用者畫像都會包含人口屬性和行為特徵。人口屬性主要指使用者的年齡、性別、所在的省份和城市、教育程度、婚姻情況、生育情況、工作所在的行業和職業等。行為特徵主要包含活躍度、忠誠度等指標。
除了以上較通用的特徵,不同型別的網站提取的使用者畫像各有側重點。
以內容為主的媒體或閱讀類網站,還有搜尋引擎或通用導航類網站,往往會提取使用者對瀏覽內容的興趣特徵,比如體育類、娛樂類、美食類、理財類、旅遊類、房產類、汽車類等等。
社交網站的使用者畫像,也會提取使用者的社交網路,從中可以發現關係緊密的使用者群和在社群中起到意見領袖作用的明星節點。
電商購物網站的使用者畫像,一般會提取使用者的網購興趣和消費能力等指標。網購興趣主要指使用者在網購時的類目偏好,比如服飾類、箱包類、居家類、母嬰類、洗護類、飲食類等。
消費能力指使用者的購買力,如果做得足夠細緻,可以把使用者的實際消費水平和在每個類目的心理消費水平區分開,分別建立特徵緯度。
另外還可以加上使用者的環境屬性,比如當前時間、訪問地點LBS特徵、當地天氣、節假日情況等。
當然,對於特定的網站或App,肯定又有特殊關注的使用者緯度,就需要把這些維度做到更加細化,從而能給使用者提供更精準的個性化服務和內容。
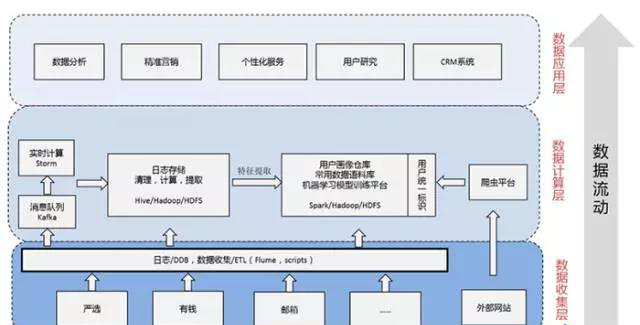
使用者畫像的生產
使用者特徵的提取即使用者畫像的生產過程,大致可以分為以下幾步:
- 使用者建模,指確定提取的使用者特徵維度,和需要使用到的資料來源。
- 資料收集,通過資料收集工具,如Flume或自己寫的指令碼程式,把需要使用的資料統一存放到Hadoop叢集。
- 資料清理,資料清理的過程通常位於Hadoop叢集,也有可能與資料收集同時進行,這一步的主要工作,是把收集到各種來源、雜亂無章的資料進行欄位提取,得到關注的目標特徵。
- 模型訓練,有些特徵可能無法直接從資料清理得到,比如使用者感興趣的內容或使用者的消費水平,那麼可以通過收集到的已知特徵進行學習和預測。
- 屬性預測,利用訓練得到的模型和使用者的已知特徵,預測使用者的未知特徵。
- 資料合併,把使用者通過各種資料來源提取的特徵進行合併,並給出一定的可信度。
- 資料分發,對於合併後的結果資料,分發到精準營銷、個性化推薦、CRM等各個平臺,提供資料支援。
下面以使用者性別為例,具體介紹特徵提取的過程:
1.提取使用者自己填寫的資料,比如註冊時或者活動中填寫的性別資料,這些資料準確率一般很高。
- 提取使用者的稱謂,如文字中有提到的對方稱呼,例如:xxx先生/女士,這個資料也比較準。
- 根據使用者姓名預測使用者性別,這是一個二分類問題,可以提取使用者的名字部分(百家姓與性別沒有相關性),然後用樸素貝葉斯分類器訓練一個分類器。過程中遇到了生僻字問題,比如“甄嬛”的“嬛”,由於在名字中出現的少,因此分類器無法進行正確分類。考慮到漢字都是由偏旁部首組成,且偏旁部首也常常具有特殊含義(很多與性別具有相關性,比如草字頭傾向女性,金字旁傾向男性),我們利用五筆輸入法分解單字,再把名字本身和五筆打法的字母一起放到LR分類器進行訓練。比如,“嬛”字的打法:『 女V+罒L+一G+衣E = VLGE 』,這裡的女字旁就很有女性傾向。
- 另外還有一些特徵可以利用,比如使用者訪問過的網站,經常訪問一些美妝或女性服飾類網站,是女性的可能性就高;訪問體育軍事類網站,是男性的可能性就高。還有使用者上網的時間段,經常深夜上網的使用者男性的可能性就高。把這些特徵加入到LR分類器進行訓練,也能提高一定的資料覆蓋率。
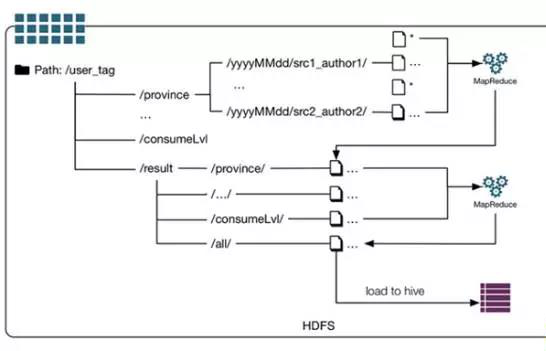
資料管理系統
使用者畫像涉及到大量的資料處理和特徵提取工作,往往需要用到多資料來源,且多人並行處理資料和生成特徵。因此,需要一個數據管理系統來對資料統一進行合併儲存和分發。我們的系統以約定的目錄結構來組織資料,基本目錄層級為:/user_tag/屬性/日期/來源_作者/。以性別特徵為例,開發者dev1從使用者姓名提取的性別資料存放路徑為 /user_tag/gender/20170101/name_dev1,開發者dev2從使用者填寫資料提取的性別資料存放路徑為 /user_tag/gender/20170102/raw_dev2。
從每種來源提取的資料可信度是不同的,所以各來源提取的資料必須給出一定的權重,約定一般為0-1之間的一個概率值,這樣系統在做資料的自動合併時,只需要做簡單的加權求和,並歸一化輸出到叢集,儲存到事先定義好的Hive表。接下來就是資料增量更新到HBase、ES、Spark叢集等更多應用服務叢集。
應用示例:個性化推薦
以電商網站的某種頁面的個性化推薦為例,考慮到特徵的可解釋性、易擴充套件和模型的計算效能,很多線上推薦系統採用LR(邏輯迴歸)模型訓練,這裡也以LR模型舉例。很多推薦場景都會用到基於商品的協同過濾,而基於商品協同過濾的核心是一個商品相關性矩陣W,假設有n個商品,那麼W就是一個n n的矩陣,矩陣的元素wij代表商品Ii和Ij之間的相關係數。而根據使用者訪問和購買商品的行為特徵,可以把使用者表示成一個n維的特徵向量U=[ i1, i2, ..., in ]。於是UW可以看成使用者對每個商品的感興趣程度V=[ v1, v2, ..., vn ],這裡v1即是使用者對商品I1的感興趣程度,v1= i1w11 + i2w12 + in*w1n。如果把相關係數w11, w12, ..., w1n 看成要求的變數,那麼就可以用LR模型,代入訓練集使用者的行為向量U,進行求解。這樣一個初步的LR模型就訓練出來了,效果和基於商品的協同過濾類似。
這時只用到了使用者的行為特徵部分,而人口屬性、網購偏好、內容偏好、消費能力和環境特徵等其他上下文還沒有利用起來。把以上特徵加入到LR模型,同時再加上目標商品自身的屬性,如文字標籤、所屬類目、銷量等資料,如下圖所示,進一步優化訓練原來的LR模型。從而最大程度利用已經提取的使用者畫像資料,做到更精準的個性化推薦。

點評:
使用者畫像是當前大資料領域的一種典型應用,也普遍應用在多款網易網際網路產品中。本文基於網易的實踐,深入淺出地解析了使用者畫像的原理和生產流程。
精確有效的使用者畫像,依賴於從大量的資料中提取正確的特徵,這需要一個強大的資料管理系統作為支撐。網易大資料產品體系中包含的一站式大資料開發與管理平臺 – 網易猛獁,正是在網易內部實踐中打磨形成的,能夠為使用者畫像及後續的業務目標實現提供資料傳輸、計算和作業流排程等基礎能力,有效降低大資料應用的技術門檻。
上海大資料培訓原作,轉載請註明出處!後續大資料相關技術文章陸續奉上,請多關注!