
基於點選圖模型Query和Document相關性的計算
參考論文:Learning Query and Document Relevance from a Web-scale Click Graph
背景:
使用者的點選日誌蘊含豐富的資訊,在資訊檢索領域具有著重要的地位。使用者點選行為資料通常用來生成訓練資料使用者機器學習提高ranking performance,或者是在ranking fuction中作為特徵來計算ranking score.
但是點選資料存在髒資料並且具有稀疏性,大量的query和document是沒有點選日誌的,這也就造成了基於點選生成的特徵的質量是難以保障的,尤其是對於一些偏長尾的query.通常會把query形成的預料庫和title形成的預料庫合併成一個預料庫,然後基於共同的這個預料庫訓練模型,但是在query和document上詞法上的區別會在之後計算相關性上帶來不好的影響。另外,當query或者是document是沒有點選日誌時,如何學習query和document的相關性就會變得困難起來。
本文主要研究:
1.在相同的語義空間中產生query和document的向量,在word-level的vector更具有解釋性,並且對於click-absent的query和document獲得vector帶來了解決之法----vector propagation on the click graph。
2.給出通用方法,形成click-absent的query和document的vector.
vector propagation on the click graph
notations:
Doc: documents形成集合,Query:queries形成集合,根據點選資料形成graph g, g的節點集V = DocUQuery.
並且用矩陣Q(|Query|*V)表示所有query-vector的矩陣,第i行Qi表示query qi的向量表示。Q(n) 表示矩陣Q的n次迭代後的結果。同樣的,D為document的向量矩陣,維度為|Doc|*V.
Vector Propagation Algorithm
迭代更新Q和D的過程很像HIT演算法迭代計算authority和hub得分的過程。
從query-side向document-side方向Propagation


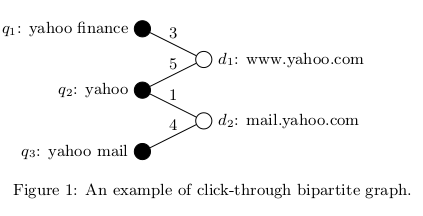
更新過程如(1)(2)所示,從query-side方向Q(0)初始化為對query中word的frequency的L2範數。如圖1中,假設從query-side向document-side方向聚合,q1{yahoo: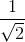


從query-side到document-side使用的是query的語料庫,而從document-side到query-side使用的則是document的語料庫。從其中一個方向初始化進行迭代就能獲得query-vector和document-vector.這樣就能避免我們提到到將兩個語料庫合併起來做特徵而導致的lexical gap的問題了。但是對於沒有點選資訊的query和document來說,如何根據點選資料生成對應的向量則是接下來我們要解決的問題。
Vector Generation For Click-Absent Queries And Documents
之前的Vector Propagation Algorithm生成query-vector和document-vector都是在word-level上,也就是說是一個詞表大小的向量 ,如果我們能夠得到word-vector,那麼即便是click-absent的query和document,如果將其分解為word,那麼這些word必然也包含在其他非click-absent的query和document中。所以獲得Unit-Vector,然後利用線性迴歸方程構造query-vector和document-vector.
形成Unit集合,將query 分解為unigrams,bigrams和trigrams。同理,可以將document的title或者是abstract進行分解,獲得unit集合,記作U。

基本步驟:
對於ui 屬於U,找到所有包含ui的query記為Qui的,同樣利用Graph g找到所有與Qui中存在連線的document,記作Kui,.Kui的第j個元素表示dj,也就是document j的vector.
如果Qui的k-th vector 和 Kui的j -th,也就是說query qk和document dj存在點選關係,那麼我們就說存在pseudo click 在qk和dj之間,記為的Pi,k,j.Pi,k,j實際上就等於query-document的co-click,Ck,j。我們想要把所有包含ui的query進行聚合,獲得ui和Kui的pseudo click,進而在從Kui上聚合獲得ui的向量表示,如公式(5)和公式(6)所示。


得到所以unit-vector,如何確定線性迴歸的權重進而得到click-absent的query-vector和document-vector.利用最小平方差來得到每個unit的weight值。

當訓練得到W和U值,則可以用線性組合分別得到在缺少點選資料的情況下query和document的向量表示,公式(8)(9)所示


這種計算query和document向量的方式都是從query vocabulary space或者是document vocabulary space中得到的,當我們能夠計算得到兩個vector向量,則可以利用cosine函式來計算query-document Pair的相關性,計算得到的相關性得分則可以作為影響排序的一個特徵。