
python爬蟲學習筆記(一)—— 爬取騰訊視訊影評
前段時間我忽然想起來,以前本科的時候總有一些公眾號,能夠為我們提供成績查詢、課表查詢等服務。我就一直好奇它是怎麼做到的,經過一番學習,原來是運用了爬蟲的原理,自動登陸教務系統爬取的成績等內容。我覺得挺好玩的,於是自己也琢磨了一段時間,今天呢,我為大家分享一個爬蟲的小例項,也算是記錄自己的學習過程吧。
我發現騰訊視訊出了一部新的電視劇,叫做《新笑傲江湖》,也不知道好看不好看,反正我只喜歡陳喬恩版的東方教主。言歸正傳,假如,我們若要對騰訊視訊中的某個視訊的影評進行批量爬取並實現自動載入新評論,這個時候,我們就可以寫一個爬蟲來幫我們完成工作。接下來,我們開始爬蟲的編寫之旅吧!
一、 Fiddler的使用
我們要爬取影評的視訊網址是:https://v.qq.com/x/cover/8jkko7n7si6k04m.html,首先我們開啟該網址,看看裡面的內容。內容如下,使勁往下拉,就可以看到下面的影評啦,如下所示:


我們發現,該網站下面的評論每次只能載入10條評論,當我們單擊“載入更多”的時候,就會又加載出10條,但是網頁的網址並沒有變化,那麼整個過程是怎樣實現的呢?要想弄明白整個過程,我們需要用到一個工具——Fiddler。Fiddler是一種常見的抓包分析軟體,同時,我們可以利用Fiddler詳細地對HTTP請求進行分析,並模擬對應的HTTP請求。
Fiddler是基本工作原理是怎樣的呢?如果沒有Fiddler,本地應用如果要與伺服器進行通訊,可以直接向伺服器傳送Request請求,待伺服器處理之後將處理結果返回本地,本地應用接收響應Response。如果有了Fiddler,本地應用與伺服器之間所有的Request和Response都將經過Fiddler,由Fiddler進行轉發,因此Fiddler以代理伺服器的方式存在,由於所有的網路資料都會經過Fiddler,自然Fiddler能夠截獲這些資料,實現網路資料的抓包。
要使用Fiddler,首先需要安裝Fiddler這款軟體。我們可以從Fiddler的官網(http://www.telerik.com/fiddler)下載Fiddler,下載之後開啟直接安裝即可。安裝好Fiddler之後,我們將學習如何使用Fiddler來捕獲瀏覽器與伺服器之間的會話資訊。在此,我們將以360瀏覽器為例進行講解。
因為Fiddler是以代理伺服器的方式進行工作的,所以我們首先應當設定360瀏覽器,讓360瀏覽器使用Fiddler作為其代理伺服器。設定360瀏覽器的方式如下:
(1)首先單擊“開啟選單”,如下所示:

(2)選擇選單中的“工具”,然後選擇“代理伺服器”,最後選擇”代理伺服器設定“,彈出以下對話方塊,在列表中新增”127.0.0.1:8888”,因為Fiddler監控的地址是127.0.0.1:8888。如下所示:


(3)此時,我們就可以使用Fiddler來捕獲360瀏覽器與伺服器之間的會話資訊了。我們知道,現在的網站有的使用HTTP協議,有的使用的是HTTPS協議。如果想讓Fiddler能夠捕獲HTTPS的會話資訊,還需要設定一下Fiddler。開啟Fiddler,然後單擊“Tools”,選擇“Options”,在彈出來的介面中選擇“HTTPS”標籤,將下方選項全部勾選上,如下所示:

至此,現在Fiddler就能捕獲360瀏覽器與伺服器之間的HTTP和HTTPS會話資訊了。
在我們編寫爬蟲之前,我們需要找到載入影評時所觸發的真實網址,這個就需要Fiddler來捕捉。操作如下:
(1)首先,在Fiddler的QuickExec命令列中輸入cls,清理列表螢幕,如下所示:

(2)單擊騰訊視訊網頁中底部的“載入更多”,觀察Fiddler的會話列表的變化,找到所觸發的會話資訊,如下所示:

(3)選中該會話,對其單擊滑鼠右鍵,選擇複製URL,如下所示:

(4)得到單機"載入更多"時所觸發的真實網址,如下所示:
https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6374514531154423930&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1522384207407
為了便於觀察載入評論資訊時觸發的網址之間的規律,再次在視訊網頁中的評論處單機“載入更多”,用同樣的方法可以在Fiddler中捕獲到新觸發的對應的真實網址,將其URL複製出來,如下所示:
https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6380041197477962010&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1522384207408
https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6378846293964012868&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1522384207409
觀察這三個網址之間的差異,可以分析出如下結果:
1) 三次都出現了2451377986,可以分析並推斷得出這個值為對應視訊的一種編號,即2451377986代表的是《新笑傲江湖》的視訊評論。
2)三次都出現orinum=10,觀察每次載入的評論數,發現也是10條,所以可以推斷得出,orinum欄位代表的是每次評論載入的數量。
3)三次cursor欄位的值不一樣,該欄位代表的應該是每10條評論中的起始id。
4)網址中後續的“&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=9&_=1522384207407”等資訊可以省略,我們可以省略後再訪問該網址進行驗證。即登陸如下網址:
https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6374514531154423930

沒錯,正是我們想要的。
5)因此,我們可以推斷出,視訊評論的URL地址格式為“https://video.coral.qq.com/varticle/視訊編號/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor=評論標號"
我們觀察用視訊評論URL地址開啟的網頁,仔細分析其內容,我們發現有一些需要進行unicode編碼才能夠顯示的內容,主要有:
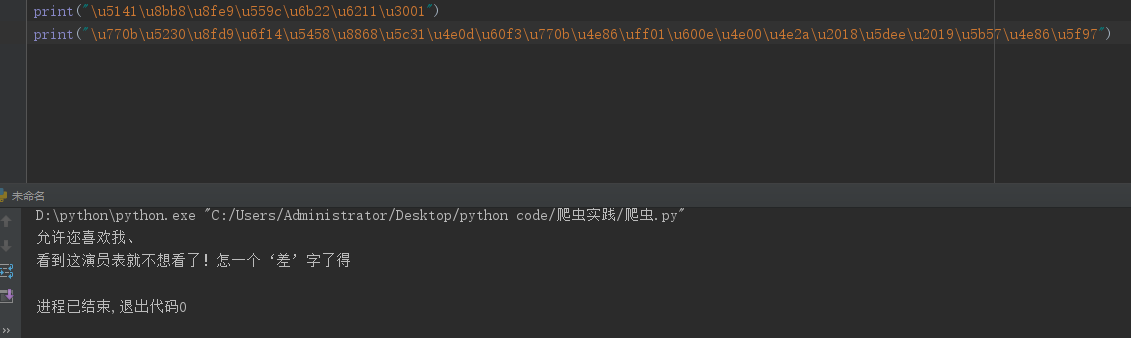
1)"content":"\u770b\u5230\u8fd9\u6f14\u5458\u8868\u5c31\u4e0d\u60f3\u770b\u4e86\uff01\u600e\u4e00\u4e2a\u2018\u5dee\u2019\u5b57\u4e86\u5f97"
2) "nick":"\u5141\u8bb8\u8fe9\u559c\u6b22\u6211\u3001"
我們用python對這兩段資訊進行解讀,並輸出對應的結果,如下所示:
隨後,我們開啟該視訊的網頁,找到對應的評論資訊,如下所示:

通過對比,我們可以很容易發現這些欄位名與評論的關係如下:
1)"content" 對應具體的評論內容
2)"nick" 對應評論者的暱稱
在理清楚了這個關係之後,我們則可以構造對應的正則表示式(不難,這裡就不介紹了)定向地爬取出評論地具體內容出來啦!
二、爬蟲程式碼展示
import urllib.request
import http.cookiejar
import re
##############################################
#該程式碼用來爬取騰訊視訊《新笑傲江湖》的影評
#時間:2018.3.30
#作者:行歌
###############################################
cursor_id = "6374188293605193032"
url = "https://video.coral.qq.com/varticle/2451377986/comment/v2?callback=_varticle2451377986commentv2&orinum=10&oriorder=o&pageflag=1&cursor="
temp_headers = {"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding":"utf-8","Accept-Language":"zh-CN,zh;q=0.8","User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"}
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener( urllib.request.HTTPCookieProcessor(cjar))
headers = []
for key,value in temp_headers.items():
item = (key,value)
headers.append( item )
opener.addheaders = headers
urllib.request.install_opener( opener)
userid_and_content = '"userid":"(.*?)","content":"(.*?)"'
id_re ='"id":"(.*?)"'
for i in range(1,20):
url_new = url + cursor_id
data = urllib.request.urlopen( url_new ).read().decode("utf-8")
userid_and_content_list = re.findall(userid_and_content,data,re.S)
id_value = re.findall(id_re ,data ,re.S)
cursor_id = id_value[-1]
content_list = [ i[1] for i in userid_and_content_list ]
for i in range(len(content_list)):
with open("comment.txt","wb") as fr:
fr.write('評論內容:'+ eval('u"'+content_list[i]+'"'))
fr.write('\n')在寫程式碼的時候我就遇到了一個坑,為了偽裝成瀏覽器,我們需要設定好對應使用者請求的Headers資訊,因此我選擇通過opener.addheaders為爬蟲新增Headers資訊,但是此時新增的Headers資訊要具備指定的格式,格式為:[(欄位名1,對應的值1),(欄位名2,對應的值2),...,(欄位名n,對應的值n)]。
其中剛開始的時候,我將Accept-Encoding設定為gzip,deflate,結果出現亂碼問題,因此,正確的辦法就是將該欄位資訊省略不寫或者將該欄位資訊的值設定為utf-8或gb2312。為什麼將該欄位的值設定為gzip,deflate會出現問題呢?是因為如果設定該欄位為gzip,deflate,那麼從伺服器返回來的是對應的gzip,deflate壓縮的程式碼,此時沒有進行解碼,故而會出現亂碼的情況,而一些常規瀏覽器中,從伺服器返回對應的gzip,deflate壓縮的程式碼後,瀏覽器可以自動進行解壓縮,故而不會出現亂碼。
最後我們把爬取的內容儲存在comment.txt檔案中,如下所示:
成功啦!!!!