
Dlib提取人臉特徵點(68點,opencv畫圖)
//女票被學妹約出去看電影了,所以有點無聊的我來寫部落格了。主要在官網給的Demo基礎之上用Opencv把特徵點描繪出來了。
很早之前寫過一篇配置Dlib環境的部落格,現在來稍微梳理下提取特徵點的使用方法。
慣例先放效果圖吧:
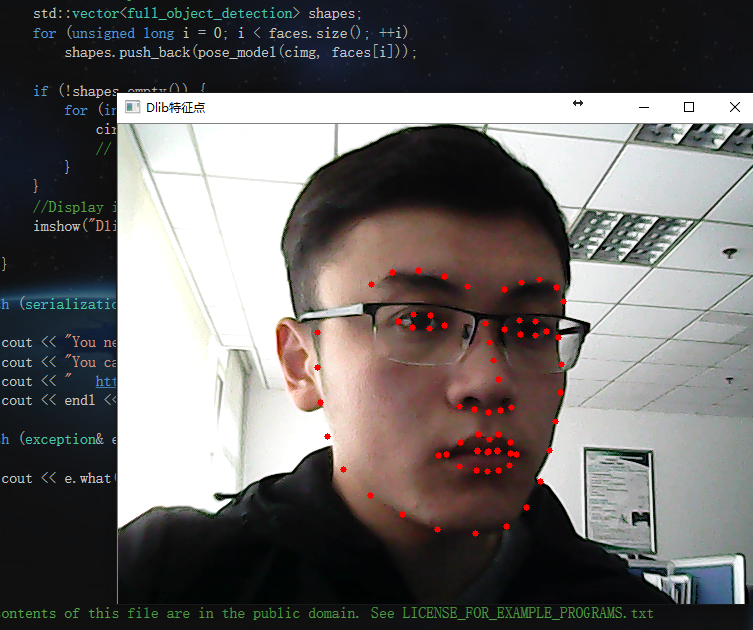
動圖如下:
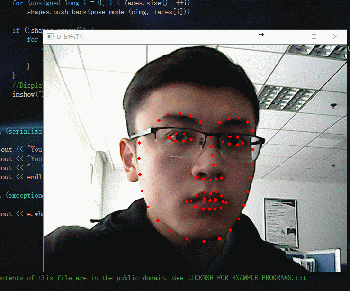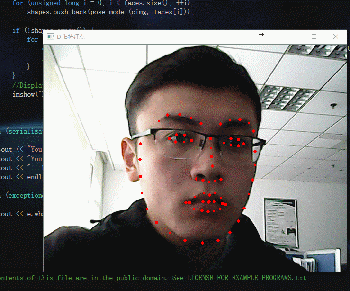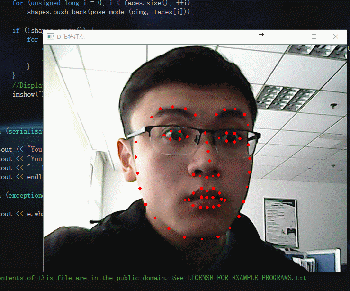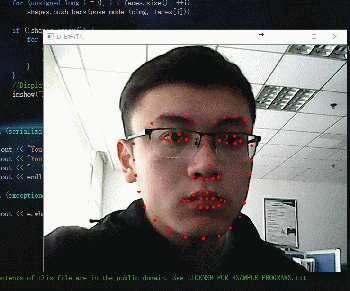
接著就是簡單粗暴的程式碼:
//@[email protected] //2016-12-4 //http://blog.csdn.net/zmdsjtu/article/details/53454071 #include <dlib/opencv.h> #include <opencv2/opencv.hpp> #include <dlib/image_processing/frontal_face_detector.h> #include <dlib/image_processing/render_face_detections.h> #include <dlib/image_processing.h> #include <dlib/gui_widgets.h> using namespace dlib; using namespace std; int main() { try { cv::VideoCapture cap(0); if (!cap.isOpened()) { cerr << "Unable to connect to camera" << endl; return 1; } //image_window win; // Load face detection and pose estimation models. frontal_face_detector detector = get_frontal_face_detector(); shape_predictor pose_model; deserialize("shape_predictor_68_face_landmarks.dat") >> pose_model; // Grab and process frames until the main window is closed by the user. while (cv::waitKey(30) != 27) { // Grab a frame cv::Mat temp; cap >> temp; cv_image<bgr_pixel> cimg(temp); // Detect faces std::vector<rectangle> faces = detector(cimg); // Find the pose of each face. std::vector<full_object_detection> shapes; for (unsigned long i = 0; i < faces.size(); ++i) shapes.push_back(pose_model(cimg, faces[i])); if (!shapes.empty()) { for (int i = 0; i < 68; i++) { circle(temp, cvPoint(shapes[0].part(i).x(), shapes[0].part(i).y()), 3, cv::Scalar(0, 0, 255), -1); // shapes[0].part(i).x();//68個 } } //Display it all on the screen imshow("Dlib特徵點", temp); } } catch (serialization_error& e) { cout << "You need dlib's default face landmarking model file to run this example." << endl; cout << "You can get it from the following URL: " << endl; cout << " http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2" << endl; cout << endl << e.what() << endl; } catch (exception& e) { cout << e.what() << endl; } }
來看下上面那段程式碼,所有的需要的特徵點都儲存在Shapes裡。仔細看看下面這行程式碼:
circle(temp, cvPoint(shapes[0].part(i).x(), shapes[0].part(i).y()), 3, cv::Scalar(0, 0, 255), -1);
每個特徵點的編號如下:
在上述畫圖的基礎上加了如下一行程式碼:
效果圖:putText(temp, to_string(i), cvPoint(shapes[0].part(i).x(), shapes[0].part(i).y()), CV_FONT_HERSHEY_PLAIN, 1, cv::Scalar(255, 0, 0),1,4);
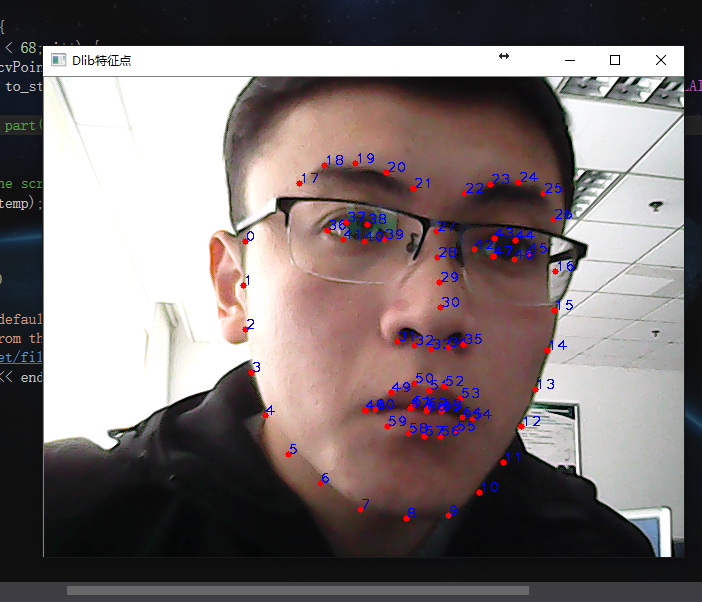
對照著上圖,比如說想獲取鼻尖的座標,那麼橫座標就是shapes[0].part[30].x(),其餘的類似。
在這個的基礎上就可以做很多有意思的事情啦,2333
最後祝大家開發愉快:)
//順便祝女票大人和學妹看電影愉快(攤手)
相關推薦
Dlib提取人臉特徵點(68點,opencv畫圖)
//女票被學妹約出去看電影了,所以有點無聊的我來寫部落格了。 主要在官網給的Demo基礎之上用Opencv把特徵點描繪出來了。 很早之前寫過一篇配置Dlib環境的部落格,現在來稍微梳理下提取特徵點的使用方法。 慣例先放效果圖吧: 動圖如下: 接著就是簡單粗
jquery提取頁面公共內容(如header,footer等)引入其他頁面【$('為引入內容建立的div的id名').load('引入的頁面l')】
在做專案時,通常頁面header部分是相同的,但如果複製貼上,程式碼量很大而且很冗餘,因此可以像vue一樣可以將頁面拆分成不同的元件,而header就是一個元件,可以單獨提取出來,最後再把不同元件合併呈現不同的頁面; 具體怎麼把頁面的一部分提取出來然後引入到需要的頁面,只需
excel 2016 提取漢字和數字(經典方法,沒有之一)
第一列含有姓名和身份證號,第二列,提取姓名,在新列中,輸入第一列有的姓名,然後豎拉快速填充(新版excel自動提取漢字功能),這樣所有的漢字即被提取。第三列,採用此公式即可 =SUBSTITUTE(A1,B1,"",1),用第一列的字串減去第二列的字串,剩下的就是身份證號碼。 去掉前後的空格。=TRI
OpenCV開發筆記(六十五):紅胖子8分鐘帶你深入瞭解ORB特徵點(圖文並茂+淺顯易懂+程式原始碼)
若該文為原創文章,未經允許不得轉載原博主部落格地址:https://blog.csdn.net/qq21497936原博主部落格導航:https://blog.csdn.net/qq21497936/article/details/102478062本文章部落格地址:https://blog.csdn.ne
組隊項目——黃金點(葉雨&王浩)
規則 pla abs 至少 相同 6.0 輸入 自己 沒有 代碼來源:自己編寫 運行環境:win10 編譯軟件:VC++6.0 使用語言:C語言 功能:可多次運行,由用戶決定退出與否,可以記錄玩家的姓名與分數並顯示。 BUG:暫未發現 GitHub地址:https://gi
第一階段項目技術點總結(ES6技術,vue技術)
每次 then 觸發 ext eba 拆分 點擊 log 是否 多思多想,勤勞! 1. 擴展運算符‘...‘,主要操作用於數組的展開運算,一般簡單的用於數組的合並,數組每個元素的拆分 2.const routers = require.context ( ‘ 要操作的目
寫給自己看-編寫測試用例的注意點(之後想到還會更新)
1.標題寫全之後,步驟不需要再從頭開始寫操作 反案例 正案例 2.每條內容不宜過多,若不可避免的內容過多時,應加序號用於區分 反案例 正案例 3.寫結果時注意是否與其他功能有互動 例:商品成功下單後商品詳情頁面所購商品規格的數量和商品列表頁面該商品的銷售量是否改變、我的訂單中是否
已知A,B兩點及C點(不在直線AB上)座標,求在直線AB上距離A點距離為線段AC長度的點D座標
(取自定位導航專案) 哇!這不就是一道初中的數學題嘛!But...
離群點(孤立點、異常值)檢測方法
本文介紹了離群點(孤立點)檢測的常見方法,以及應用各種演算法時需要注意的問題。 離群點是什麼? 異常物件被稱作離群點。異常檢測也稱偏差檢測和例外挖掘。孤立點是一個明顯偏離與其他資料點的物件,它就像是由一個完全不同的機制生成的資料點一樣。 離群點檢測是資
Ubuntu的安裝以及重新安裝的注意點(儲存以前的使用者資料)
最近折騰Ubuntu裝機,為了儲存以前的使用者資料。需要做一下操作:1. 為了能夠在下次安裝Ubuntu時能夠不破壞使用者資料,在磁碟分割槽時一定將使用者資料區域(/home/目錄)和Ubuntu的安裝目錄(根目錄/)單獨分兩個磁碟分割槽。swap分割槽2G即可,/boot分
恢復到特定點(時間點、scn、日誌序列號),rman不完全恢復
將資料庫、表空間、資料檔案等恢復至恢復備份集儲存時間中的任何一個時間點/SCN/日誌序列(一般是日誌挖掘找到誤操作點),但須謹慎,操作前一定需要做好備份,具備條件的情況下最好先恢復到異機,避免業務停機時間。 前提:已經有資料庫備份 (作者已經提前準備了備份,這裡不進行備
批量提取 caffe 特徵 (python, C++, Matlab)(待續)
本文參考如下: 關於如何批量提取特徵,本文的框架如下: 1. 準備資料及相應準備工作 2. 初始化網路 3.讀取影象列表 4.提取影象特徵,並儲存為特定格式 Python方法一 主要有三個函式: initialize
Dlib提取Hog特徵
效果如圖… 關鍵點: 1.設定cell大小 2.其他的看程式碼 3.Dlib配置見: 地址 程式碼: #include <dlib/gui_widgets.h> #include <dlib/image_io.h> #include
c語言實現求組合數(帶點優化的思想,防止溢位)
這是大家都知道的組合數,思想也很簡單,但是裡面的階乘,容易溢位,讓m!/n!先約分,減小數的大小,m!/n! = (n+1)(n+2)(n+3)···(m-1)(m); 如果m-n > n的話,我們就讓n = m-n.j儘可能讓乘起來的數小一點。程式碼列印的是25裡
scrapy的一些容易忽視的點(模擬登陸,傳遞item等)
信息 pan pytho 完成 xtra author back book 多少 scrapy爬蟲註意事項 item數據只有最後一條 item字段傳遞後錯誤,混亂 對一個頁面要進行兩種或多種不同的解析 xpath中contains的使用 提取不在標簽內的文本內容 使用cs
Lucene同義詞檢索同時精確提取自定義關鍵詞(Lucene版本5.3.0)
此博文針對的是Lucene版本5.3.0,若您的Lucene版本為3.X,請移步這裡http://write.blog.csdn.net/postedit/78291868(只提取關鍵詞,未包含同義詞檢索) 本篇文章包含兩個功能 1、精確提取自定義關鍵詞 2、同義詞檢索與
Python特徵選擇--方差特徵選擇(Removing features with low variance)
最近在看Python中機器學習之特徵選擇,為了避免遺忘,特記一波。Removing features with low variance,即低方差過濾特徵選擇。其原理也是比較簡單,計算樣本中每一個特徵值所對應的方差,如果低於閾值,則進行過濾(剔除)。預設情況下,將會剔除所有零
影象區域性特徵學習(筆記1之邊緣檢測)
邊緣 所謂邊緣,就是指影象中灰度強烈變化的區域。這個強烈變化,就很容易想到微分運算。(PS:涉及到微分運算,就要想到去噪,因為微分運算對噪聲是很敏感的。) 演算法分類 一階微分邊緣運算元,經典運算元比如:Roberts(羅伯特)、Prewitt(普魯
如何使用百度雲人臉識別服務(V3版介面python語言)(二)初識SDK
上次我們講到了如何新建一個面部識別的應用,現在我們就可以開始使用這個服務了 下載SDK有多種方法,我就不多說,提供一種最簡單的方法:直接使用pip安裝 開啟Windows的cmd(命令提示符) 輸入 pip ins
人臉檢測SSH(Single Stage Headless Face Detector)配置方法(caffe版)
SSH: Single Stage Headless Face Detector 這篇是ICCV2017關於人臉檢測的文章,提出SSH(single stage headless)演算法有效提高了人臉檢測的效果,主要改進點包括多尺度檢測、引入更多的上下文資訊、損失函式的分組