
雲計算vs霧計算:物聯網的發展能否「雲開霧散」?
說雲計算小夥伴們可能都知道,但霧計算就給懵了。相比於雲計算的高高在上和遙不可及,霧計算更為貼近地面,就在你我身邊。
太復雜的概念小編就不提了,隨便百度一下就能出來無數種介紹。
小編給大家簡單介紹一下幾個關鍵點。
什麽是霧計算?
現在大多數人認為的“霧計算”是由2011年由美國思科公司首創的。
其實最開始“霧計算”概念最開始是由美國哥倫比亞大學的斯特爾佛教授提出來的,當初的目的是想利用“霧”來阻擋******。
後來美國的思科公司接手了“霧計算”這個詞,就有了現在的“霧計算”。
而思科之所以用“霧計算”這個詞,是源於“霧是更接近地面的雲”這個概念。
霧計算的網絡版定義是:在該模式中數據、(數據)處理和應用程序集中在網絡邊緣的設備中(這裏的邊緣設備可以是傳統網絡設備,如路由器、交換機、網關等,也可以是專門部署的本地服務器),而不是幾乎全部保存在雲中,是雲計算的延伸概念。
計算專家對“霧計算”的解釋:
霧計算是介於雲計算和個人計算之間的、半虛擬化的服務計算架構模型。霧計算實際上並沒有強力的計算能力,霧計算是將物理上分散的計算機聯合起來,形成較弱的計算能力,不過這樣的計算能力對於中小型的數據中心,完全夠用了。
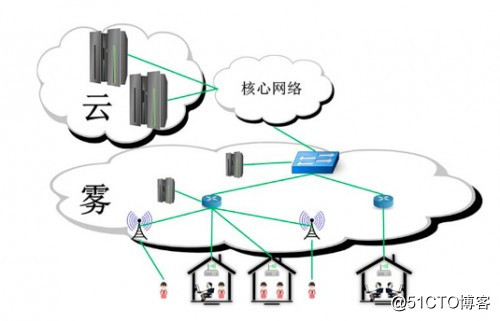
所以,對於“霧計算”,我們可以這樣理解:
首先,它是雲計算的延伸概念,但不用將數據傳到雲端,而是集中在邊緣設備中;
其次,霧計算由性能較弱、分散的各類功能計算機組成,是一種分布式的數據處理方式,具有去中心化的特點;
另外,源於“霧是更貼近地面的雲”這句話,可以知道,霧計算是距離終端更近的東西,不像雲那樣遙遠。數據的存儲及處理更依賴本地設備,而不是服務器。
所以,也可以將霧計算理解為本地化的雲計算,總之,是為用戶提供數據資源服務的。
已經有雲計算了,為什麽還要研究霧計算?
因為雲計算已經不能滿足時代發展下的計算需求。
隨著物聯網技術的發展及各種智能設備的出現,雲計算需要處理的數據量越來越大,網絡帶寬壓力、數據中心的負擔越來越重,數據傳輸和信息獲取的情況面臨巨大的挑戰。
網絡擁堵、網絡延遲、安全性低等問題都需要解決。
也就是說,上網的人越來越多了,使用網絡的設備也越來越多了,而且將來無人駕駛、各種智能應用等對數據處理的所低延遲、高速率、高安全性的要求越來越高,所以雲計算的壓力就越來越大,這時候它需要一個助手來分擔它的壓力。

所以霧計算就出現了。
雖然霧計算的整體計算能力並不比雲計算強大,但它的一些優勢也是雲計算所沒有的。
一,處理數據時效快,低延時
計算的計算節點在網絡拓撲(網絡傳輸設備的布局)中的位置更低,接近終端用戶,利用靠近服務需求的計算資源進行數據處理,所以處理數據的時效更快。
二,位置感知
由於分布範圍較廣,密度較大,可以較為精確的獲取其中設備的位置信息。
三,廣泛的地理分布
與雲計算中心集中式分布相反,霧計算更偏向於分布式分布,以量變引起質變。
四,移動性
對於霧計算來說,手機和其他移動設備可以相互之間直接通信,信號不必到雲端甚至基站走一圈。
五,更多的邊緣節點
支持多樣化的軟硬件設備,可以減輕骨幹網絡的壓力,提高連接的設備的數量。
霧計算的應用現狀及未來是什麽樣的?
以一個制造業案例為例,假設大型公司在印度建立了工廠生產清潔劑。想象整個流程中一個這樣的機器——攪拌機(垂直或水平攪拌機),攪拌機的運轉原理是以預設的轉速定時旋轉,攪拌機筒吸收到不同的原材料,其運轉會耗費一定量的能源。
如果我們利用物聯網生態系統,讓這個設備成為“智能攪拌機”會怎樣?攪拌機安裝的大量傳感器為各種參數捕捉數據,然後數據傳回服務器(雲)進行後續分析。
如何提供功率消耗的效率?這就是與霧計算的聯系。以前考慮的物聯網架構是利用雲存儲和分析數據做出決定,但是為了讓資產/機器成為“智能設備”,我們需要霧計算架構,也就是增加本地實時計算數據流的能力,並向歷史信號學習幫助機器做出決策來改善結果。
基於這些自主學習規則,通過增加和降低設置來保持在最佳能耗模式,機器可以調整操作參數。當數據傳輸到雲端,雲端用新數據組更新機器學習模型,那麽數據規則和(自主)學習就可以更新了。一旦更新,它會被推回邊緣,邊緣節點利用更新模型來更新規則,進一步改善結果。
簡而言之,通過推動計算邊緣化,我們也將智能推到邊緣,因此讓設備或資產能夠做出自主決策來改善結果,並成為智能設備。未來霧計算將與雲計算相輔相成、有機結合,為萬物互聯時代的信息處理提供更完美的軟硬件支撐平臺。
雲計算vs霧計算:物聯網的發展能否「雲開霧散」?