文字生成統一框架Texygen實踐
文字生成是自然語言理解的高階階段,是實現類人智慧的重要手段之一。Geek.AI在AAAI2018中推出了LeakGAN後,終於又推出了TexyGen這個開源文字生成框架。由於之前就想對leakgan深入地看一下,不過這回可以通過TexyGen這個框架來實現實現對近幾年的所有文字生成模型的直接實現。
目前其支援的模型如下:
Implemented Models and Original Papers
從SeqGAN, LeakGAN、TextGAN等全部涵蓋在裡面。GAN是實現無監督學習和樣本生成的重要方法,而GAN與NLP的結合來實現文字生成也是很自然的切入點。GAN的成功激發了人們對文字離散資料對抗性訓練研究的興趣。例如,序列生成對抗網路SeqGAN是應用REINFORCE演算法解決原始GAN目標函式的離散優化的早期嘗試之一。自那以後,研究人員提出了許多改進SeqGAN的方法來進一步提升SeqGAN的效能,例如梯度消失(MaliGAN ,RankGAN ,LeakGAN 使用的自舉再啟用),以及生成長文字時的魯棒性(LeakGAN)。
如SeqGAN的框架如下所示:

LeakGAN的原理框架如下所示:
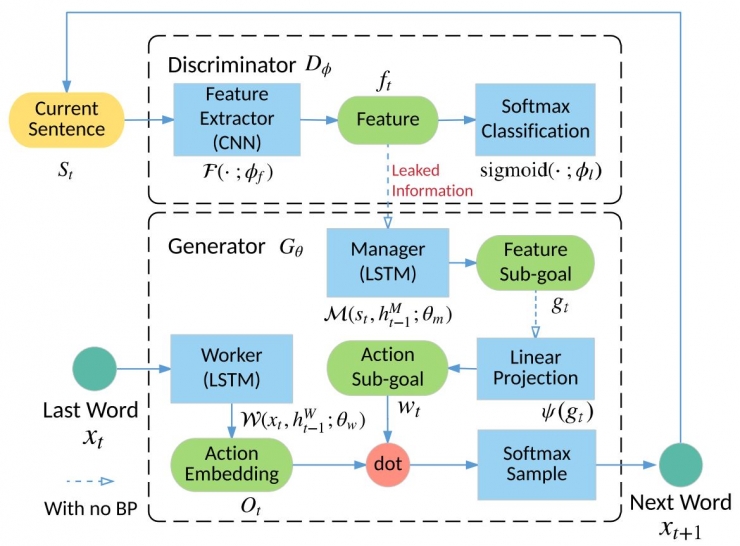
Texygen框架呢則實現將所有的GAN以派生的方式進行綜合抽象。
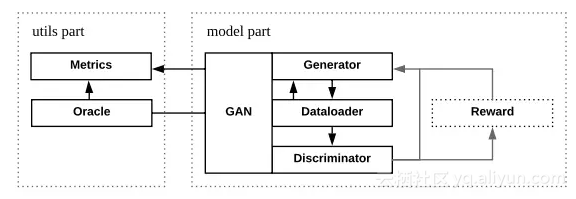
此外,重要的是Texygen提供了一個多元化的文字評價指標體系,它包括了5個文字生成的評測指標,主要如下:
基於文件相似度的指標。生成的文件質量的最直觀的評測指標是文件與自然語言或者訓練資料集的類似程度:
BLEU:基於詞袋(bag of words)模型的評測指標。以詞和片語為基本單位。
EmbSim :使用模型輸出的序列訓練出的詞向量的相互相似性特徵定義的評測指標。以基本詞元(token)為基本單位。
基於似然性(likelihood)的指標:
NLL-oracle:基於人造資料的似然度估計。衡量待評測語言模型的輸出在構造出的人造資料模型衡量下的負對數似然。
NLL-test:基於測試資料的似然度估計。衡量構造出測試資料在待評測語言模型的衡量下的負對數似然。
基於多樣性評價的指標:
Self-BLEU:基於詞袋(bag of words)模型的評測指標。衡量一個模型的每一句輸出與此模型其他輸出的相似性。以詞和片語為基本單位。
2、實踐訓練
此處只以leakgan的訓練進行RUN。
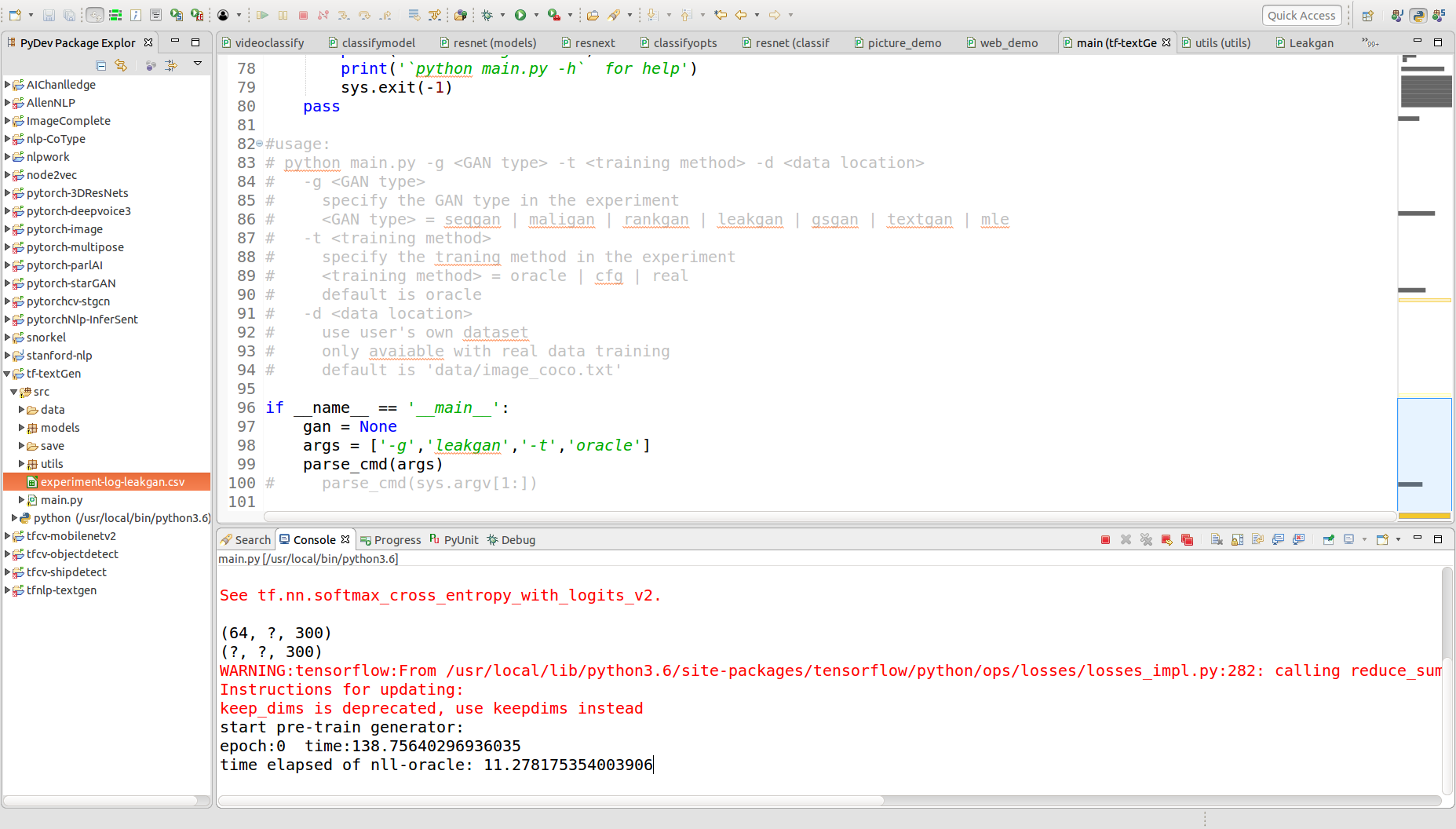
可以看出在每個epoch中,都會計算評測的數值。