
Hadoop安裝部署的三種模式
hadoop安裝部署有以下三種模式:
本地模式
偽分佈模式
全分佈模式
安裝之前操作: 1.修改主機名,設定好IP 2.設定hadoop的環境變數: 命令:vi ~/.bash_profile ``` ### add for hadoop HADOOP_HOME=/root/ubuntu/training/hadoop-2.7.3 export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export PATH ``` source ~/.bash_profile 讓環境變數生效
一、本地模式
1.配置引數:
引數檔案 配置引數 參考值
hadoop-env.sh JAVA_HOME /root/training/jdk1.8.0_144
特點:
機器一臺,沒有HDFS、只能測試MapReduce程式,MapReduce處理的是本地Linux的檔案資料
2.實際操作:
修改配置:
vi hadoop-env.sh
25 export JAVA_HOME=/root/training/jdk1.8.0_144
3.測試MapReduce程式:
(1)、建立目錄和原始資料data.txt
mkdir ~/input
vi ~/input/data.txt
編輯內容:

(2)、執行和結果檢視
例子:/root/training/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ~/input/data.txt ~/output
二、偽分佈模式
1.引數配置:
特點:
是在單機上,模擬一個分散式的環境
具備Hadoop的主要功能,可以用於學習使用
HDFS: namenode+datanode+secondarynamenode
Yarn: resourcemanager + nodemanager
2.實際操作:
(1)修改配置檔案
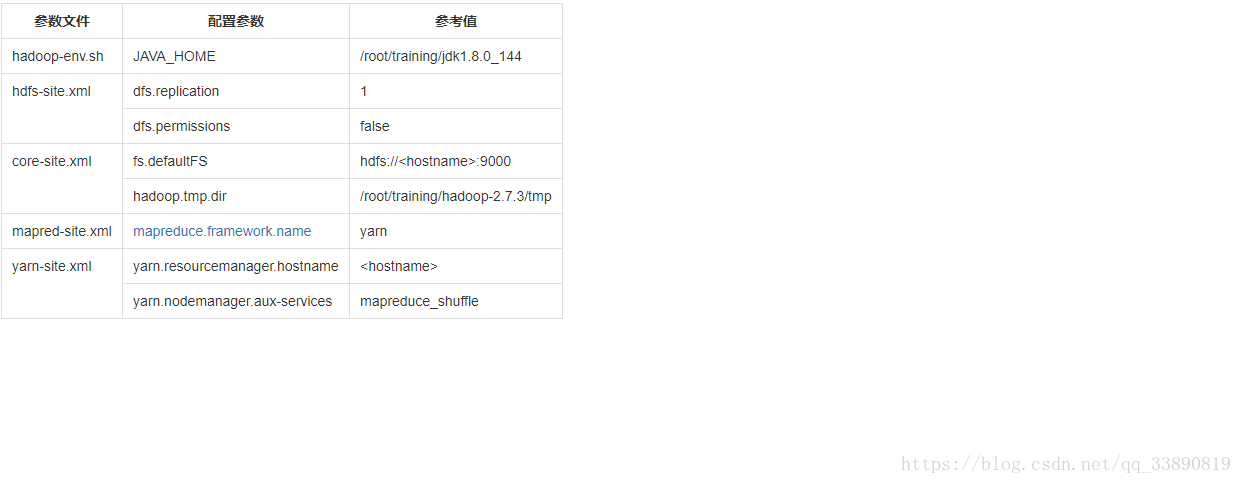
. hdfs-site.xml
原則:一般資料塊的冗餘度跟資料節點(DataNode)的個數一致;最大不超過3
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
先不設定
<!--是否開啟HDFS的許可權檢查,預設true-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
這裡寫程式碼片core-site.xml
<!--配置NameNode地址,9000是RPC通訊埠-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property>
<!--HDFS資料儲存在Linux的哪個目錄,預設值是Linux的tmp目錄-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property> mapred-site.xml 預設沒有 cp mapred-site.xml.template mapred-site.xml
<!--MR執行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> yarn-site.xml
<!--Yarn的主節點RM的位置,bigdata111為主機名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property>
<!--MapReduce執行方式:shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> (2).格式化:HDFS(NameNode)
hdfs namenode -format
日誌:
Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted.

(3).啟動停止Hadoop的環境
start-all.sh
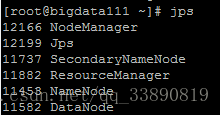
(5).stop-all.sh
注意:最好配置免密碼登入
3.執行例子:
/root/training/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
命令:hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output/0407
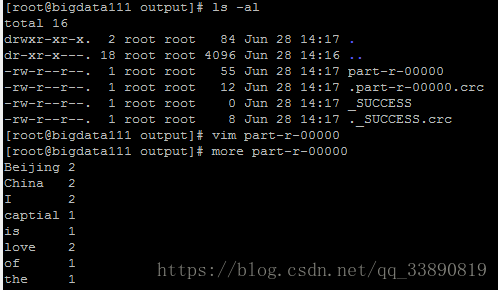
hdfs dfs -ls -R /out/0407
[email protected] ~/training/hadoop-2.7.3/tmp/dfs $ hdfs dfs -ls -R /output
drwxr-xr-x - ubuntu supergroup 0 2018-07-05 16:31 /output/0407
-rw-r--r-- 1 ubuntu supergroup 0 2018-07-05 16:31 /output/0407/_SUCCESS
-rw-r--r-- 1 ubuntu supergroup 56 2018-07-05 16:31 /output/0407/part-r-00000
[email protected] ~/training/hadoop-2.7.3/tmp/dfs $ hdfs dfs -cat /output/0407/part-r-00000
Beijing 2
China 2
I 2
captital 1
is 1
love 2
of 1
the 1三、全分佈模式
1.引數配置
特點:
正在的分散式環境,用於生產
2.實際操作:
做好規劃,三臺機器
(1)、準備工作(3臺均操作)
(*)關閉防火牆
systemctl stop firewalld.service
systemctl disable firewalld.service
(*)安裝JDK
(*)配置主機名 vi /etc/hosts
192.168.17.112 bigdata112
192.168.17.113 bigdata113
192.168.17.114 bigdata114
(*)配置免密碼登入:兩兩之間的免密碼登入
a. 每臺機器產生自己的公鑰和私鑰
ssh-keygen -t rsa
b. 每臺機器把自己的公鑰給別人
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
ssh-copy-id -i .ssh/id_rsa.pub [email protected]
(*)保證每臺機器的時間同步
如果時間不一樣,執行MapReduce程式的時候可能存在問題
在MTputty上使用date -s 2018-06-29
(2)、在主節點上(bigdata112)安裝
a.解壓設定環境變數
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
設定:112 113 114
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
b.修改配置檔案
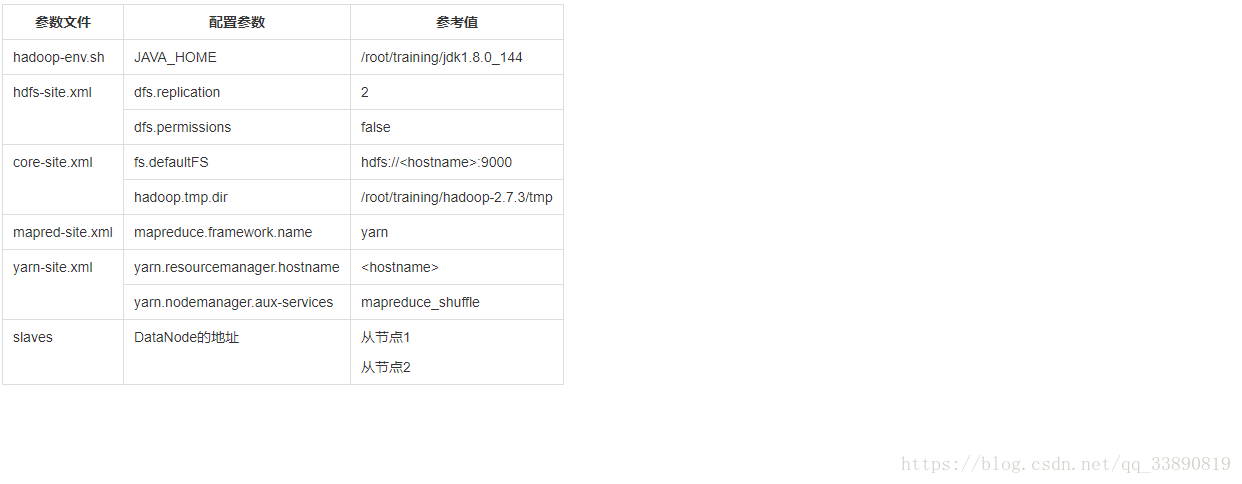
hadoop-env.sh JAVA_HOME /root/training/jdk1.8.0_144
hdfs-site.xml
<!--表示資料塊的冗餘度,預設:3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>core-site.xml
<!--配置NameNode地址,9000是RPC通訊埠-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata112:9000</value>
</property>
<!--HDFS資料儲存在Linux的哪個目錄,預設值是Linux的tmp目錄-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property> mapred-site.xml 預設沒有 cp mapred-site.xml.template mapred-site.xml
<!--MR執行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> yarn-site.xml
<!--Yarn的主節點RM的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata112</value>
</property>
<!--MapReduce執行方式:shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> slaves
bigdata113
bigdata114(3) 格式化NameNode: hdfs namenode -format
(4) 把主節點上配置好的hadoop複製到從節點上
scp -r hadoop-2.7.3/ [email protected]:/root/training
scp -r hadoop-2.7.3/ [email protected]:/root/training
(5) 在主節點上啟動 start-all.sh
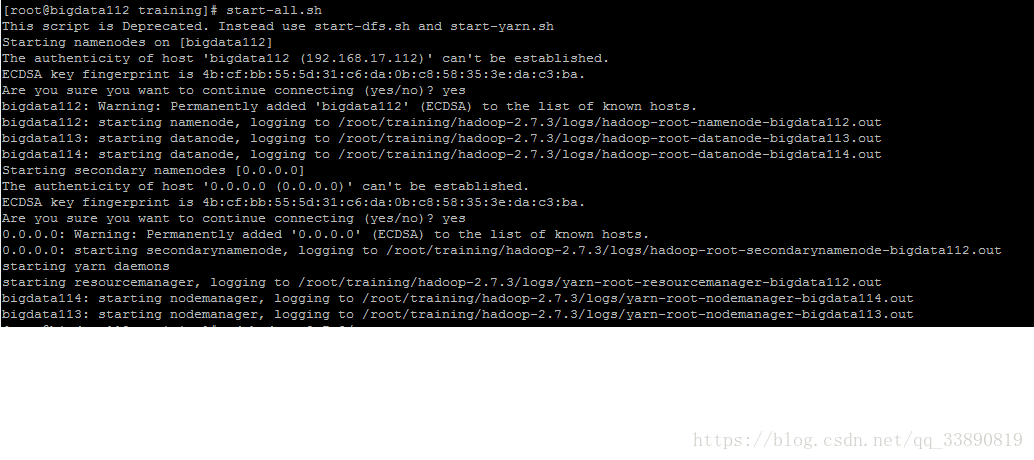
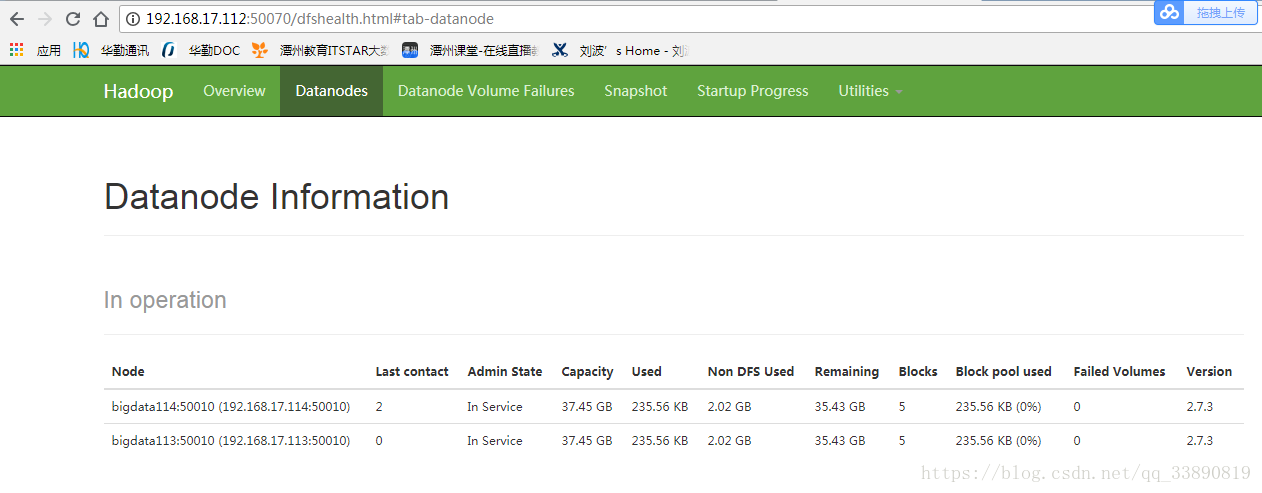
執行wordcount程式:
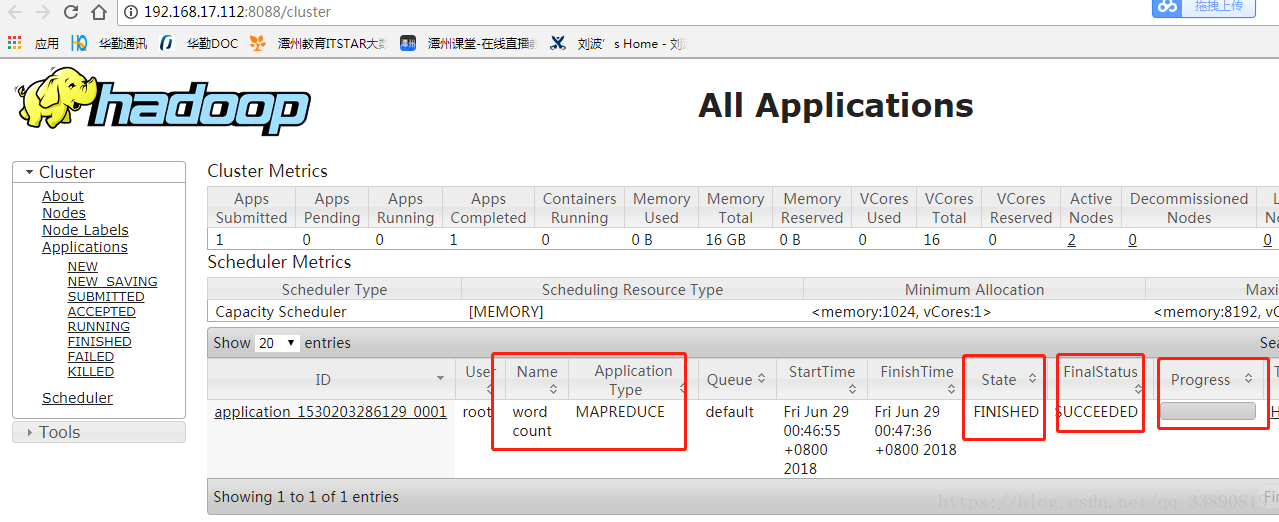
詳細操作步驟可參考連結:
相關推薦
zookeeper 安裝的三種模式
Zookeeper安裝 zookeeper的安裝分為三種模式:單機模式、叢集模式和偽叢集模式。 單機模式 首先,從Apache官網下載一個Zookeeper穩定版本,本次教程採用的是zookeeper-3.4.9版本。 http://apache.fayea.com/zookeeper/zook
Hadoop安裝部署的三種模式
hadoop安裝部署有以下三種模式: 本地模式 偽分佈模式 全分佈模式 安裝之前操作: 1.修改主機名,設定好IP 2.設定hadoop的環境變數: 命令:vi ~/.bash_profile ``` ### add for ha
VM安裝的三種網路模式
VMware虛擬機器有三種網路模式,分別是Bridged(橋接模式)、NAT(網路地址轉換模式)、Host-only(主機模式)。 VMware workstation安裝好之後會多出兩個網路連線,分別是VMware Network Adapter VMnet1和VMw
hadoop基礎-------虛擬機器(五)-----虛擬機器linux系統網路配置的三種模式
三種模式的簡介VMWare提供了三種工作模式它們是bridged(橋接模式)NAT(網路地址轉換模式)host-only(主機模式)要想在網路管理和維護中合理應用它們,你就應該先了解一下這三種工作模式。這裡首先大概介紹它們什麼情況下需要它們。bridged相當於建立一臺獨立的
day06.Hadoop快速入門&雲服務三種模式IaaS,PaaS和SaaS【大資料教程】
day06.Hadoop快速入門&雲服務三種模式IaaS,PaaS和SaaS【大資料教程】1. HADOOP背景介紹1.1 什麼是HADOOP1). HADOOP是apache旗下的一套開源軟體
EXSI+VSPHERE的安裝配置+三種虛擬磁碟模式
一、EXSI的基本介紹 1. ESXi專為執行虛擬機器、最大限度降低配置要求和簡化部署而設計且由VMware出品。目前的伺服器基本都DELL系列的R710、R720、R820這些伺服器,而既然用作伺服器來使用,像這種伺服器的配置一般都很高,是不會單獨用來裝一個系統而承載小部
hadoop學習;自定義Input/OutputFormat;類引用mapreduce.mapper;三種模式
hadoop分割與讀取輸入檔案的方式被定義在InputFormat介面的一個實現中,TextInputFormat是預設的實現,當你想要一次獲取一行內容作為輸入資料時又沒有確定的鍵,從TextInputFormat返回的鍵為每行的位元組偏移量,但目前沒看到用過 以前在m
Apache hadoop叢集安裝的三種方式:本地、偽分佈、完全分佈
四 Hadoop執行模式1)官方網址(1)官方網站:(2)各個版本歸檔庫地址 (3)hadoop2.7.2版本詳情介紹2)Hadoop執行模式(1)本地模式(預設模式):不需要啟用單獨程序,直接可以執行,測試和開發時使用。(2)偽分散式模式:等同於完全分散式,只有一個節點。(
mysql binlog日誌的三種模式
base 新版 產生 日誌模式 出現 行數據 原本 兩種模式 可能 1、statement level模式 每一條會修改數據的sql都會記錄到master的bin-log中。slave在復制的時候sql進程會解析成和原來master端執行過的相同的sql來再次執行。優點:s
VMware網絡的三種模式
vmware1.Bridged模式2.NAT模式3.Host-only模式VMware網絡的三種模式
centos 軟件安裝的三種方式
.rpm 依賴 lin 軟件安裝 沒有 深入 linux install linu Linux下面安裝軟件的常見方法: 1.yum 替你下載軟件 替你安裝 替你解決依賴關系 點外賣 缺少的東西 外賣解決 1).方便 簡單2)沒有辦法深入修改 yum install -y
第十三節: EF的三種模式(三) 之 來自數據庫的CodeFirst模式
三種 相同 blog size 好的 不一致 mil 簡介 pan 一. 簡介 【來自數據庫的Code First模式】實質上並不是CodeFirst模式,而是DBFirst模式的輕量級版本,在該模式中取消了edmx模型和T4模板,直接生成了EF上下文和相應的類,該模
Vi編輯器的三種模式
linux vi編輯器的三種模式 Vi編輯器的三種模式1)一般模式 (光標移動、復制、粘貼、刪除)2)編輯模式 (編輯文本)3)命令行模式 (查找和替換)ESC:返回鍵vi 文件名查找字符串,使用/加上要查找的字符串,如:/abc輸入/後,就進入命令行模式一般模式,輸入: 或 \ 或 ?就進
LVS三種模式配置及優點缺點比較
111LVS三種模式配置LVS 三種工作模式的優缺點比較LVS三種模式配置LVS三種(LVS-DR,LVS-NAT,LVS-TUN)模式的簡要配置LVS是什麽:http://www.linuxvirtualserver.org/VS-NAT.htmlhttp://www.linuxvirtualserver.
VMware網絡連接三種模式
vmware 網絡連接VMWARE裏面有三種網絡連接模式,分別是橋接模式、NAT模式、Host-Only模式,推薦使用NAT模式,可以分配更多的IP地址給虛擬機使用。下面分別介紹一下這三種模式。橋接模式:橋接模式就是將主機網卡與虛擬機虛擬的網卡利用虛擬網橋進行通信。在橋接的作用下,類似於把物理主機虛擬為一個交
oop思維意識,類 模塊命名空間,類擴展之繼承 、組合、mixin三種模式
經驗 .cn 第四版 分享圖片 實例 pytho 模塊 組合 為什麽 python的書都是講怎麽創建類怎麽實例化對象,一般會用使用了,但還不具備這種編程意識。這是從python學習手冊第四版節選出來的,書中說oop不僅是一種技術,更是一種經驗。學習大神的看法,為什麽需
Linux中vim的三種模式以及基本命令
body 指定 col -s global 使用 全局 oba .com 在Linux中vim的三種模式分別為:命令模式、末行模式、編輯模式。以下是三者的關系圖: 三種模式的彼此切換: 命令模式是vim中的默認模式。 命令模式切換至末行模式: 使用英文冒號(:)。 末行模
VMware下網絡配置的三種模式
tcp/ip ati 相對 導致 默認 互聯 外部網絡 網絡連接 外部 目錄 一 網絡配置中出現的錯誤及解決方案二 VMware下網絡配置的三種模式簡介1、橋接模式(Bridged)2、網絡地址轉化模式(NAT)3、僅主機模式(host-only) 網絡配置中出現的錯誤及解
nginx虛擬主機三種模式的簡單實現
_for nod send nop request user 模式 -s hit main配置段: user nginx; #指定用於運行worker進程的用戶和組 worker_processes 4; #worker的進程數;通常應該為CPU的核心數或核心數減1
應用負載均衡之LVS(一):基本概念和三種模式
保存 訪問 方式 video big key vhdl cisc vid 網站架構中,負載均衡技術是實現網站架構伸縮性的主要手段之一。所謂"伸縮性",是指可以不斷向集群中添加新的服務器來提升性能、緩解不斷增加的並發用戶訪問壓力。通俗地講,就是一頭牛拉不動時,就用兩頭、三