
Java之synchronized的實現原理
0. 前言
目前在Java中存在兩種鎖機制:synchronized和Lock, Lock介面及其實現類是JDK5增加的內容,其作者是大名鼎鼎的併發專家Doug Lea。本文並不比較synchronized與Lock孰優孰劣,只是介紹二者的實現原理。
資料同步需要依賴鎖,那鎖的同步又依賴誰?synchronized給出的答案是在軟體層面依賴JVM,而Lock給出的方案是在硬體層面依賴特殊的CPU指令,大家可能會進一步追問:JVM底層又是如何實現synchronized的?
本文所指說的JVM是指Hotspot的6u23版本,下面首先介紹synchronized的實現:synrhronized關鍵字簡潔、清晰、語義明確,因此即使有了Lock介面,使用的還是非常廣泛。其應用層的語義是可以把任何一個非null物件作為"鎖",
1. 執行緒狀態及狀態轉換
當多個執行緒同時請求某個物件監視器時,物件監視器會設定幾種狀態用來區分請求的執行緒:
Contention List:所有請求鎖的執行緒將被首先放置到該競爭佇列
Entry List:Contention List中那些有資格成為候選人的執行緒被移到Entry List
Wait Set:那些呼叫wait方法被阻塞的執行緒被放置到Wait Set
OnDeck:任何時刻最多隻能有一個執行緒正在競爭鎖,該執行緒稱為OnDeck
Owner:獲得鎖的執行緒稱為Owner
!Owner:釋放鎖的執行緒
下圖反映了個狀態轉換關係:
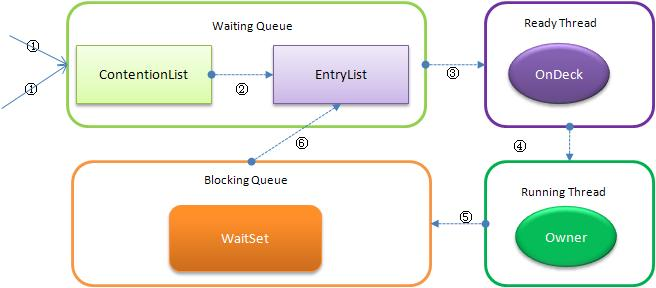
新請求鎖的執行緒將首先被加入到ConetentionList中,當某個擁有鎖的執行緒(Owner狀態)呼叫unlock之後,如果發現EntryList為空則從ContentionList中移動執行緒到EntryList, 下面說明下ContentionList和EntryList的實現方式:
1.1 ContentionList虛擬佇列
ContentionList並不是一個真正的Queue,而只是一個虛擬佇列,原因在於ContentionList是由Node及其next指標邏輯構成,並不存在一個Queue的資料結構。ContentionList是一個後進先出(LIFO)的佇列,每次新加入Node時都會在隊頭進行,通過CAS改變第一個節點的的指標為新增節點,同時設定新增節點的next指向後續節點,而取得操作則發生在隊尾。顯然,該結構其實是個Lock-Free(無鎖)的佇列。
因為只有Owner執行緒才能從隊尾取元素,也即執行緒出列操作無爭用,當然也就避免了CAS的ABA問題。
1.2 EntryList
EntryList與ContentionList邏輯上同屬等待佇列,ContentionList會被執行緒併發訪問,為了降低對ContentionList隊尾的爭用,而建立EntryList。 Owner執行緒在unlock時會從ContentionList中遷移執行緒到EntryList,並會指定EntryList中的某個執行緒(一般為Head)為Ready(OnDeck)執行緒。Owner執行緒並不是把鎖傳遞給OnDeck執行緒,只是把競爭鎖的權利交給OnDeck,OnDeck執行緒需要重新競爭鎖。這樣做雖然犧牲了一定的公平性,但極大的提高了整體吞吐量,在Hotspot中把OnDeck的選擇行為稱之為“競爭切換”。
OnDeck執行緒獲得鎖後即變為owner執行緒,無法獲得鎖則會依然留在EntryList中,考慮到公平性,在EntryList中的位置不發生變化(依然在隊頭)。如果Owner執行緒被wait方法阻塞,則轉移到WaitSet佇列;如果在某個時刻被notify/notifyAll喚醒,則再次轉移到EntryList。
2. 自旋鎖
那些處於ContetionList、EntryList、WaitSet中的執行緒均處於阻塞狀態,阻塞操作由作業系統完成(在Linxu下通過pthread_mutex_lock函式)。執行緒被阻塞後便進入核心(Linux)排程狀態,這個會導致系統在使用者態與核心態之間來回切換,嚴重影響鎖的效能。
緩解上述問題的辦法便是自旋,其原理是:當發生爭用時,若Owner執行緒能在很短的時間內釋放鎖, 則那些正在爭用執行緒可以稍微等一等(自旋),在Owner執行緒釋放鎖後,爭用執行緒可能會立即得到鎖,從而避免了系統阻塞。但Owner執行的時間可能會超出了臨界值,爭用執行緒自旋一段時間後還是無法獲得鎖,這時爭用執行緒則會停止自旋進入阻塞狀態(後退)。基本思路就是自旋,不成功再阻塞,儘量降低阻塞的可能性,這對那些執行時間很短的程式碼塊來說有非常重要的效能提高。 自旋鎖有個更貼切的名字:自旋-指數後退鎖,也即複合鎖。很顯然,自旋在多處理器上才有意義。
還有個問題是,執行緒自旋時做些啥?其實啥都不做,可以執行幾次for迴圈,可以執行幾條空的彙編指令,目的是佔著CPU不放,等待獲取鎖的機會。所以說,自旋是把雙刃劍,如果旋的時間過長會影響整體效能,時間過短又達不到延遲阻塞的目的。顯然,自旋的週期選擇顯得非常重要,但這與作業系統、硬體體系、系統的負載等諸多場景相關,很難選擇,如果選擇不當,不但效能得不到提高,可能還會下降,因此大家普遍認為自旋鎖不具有擴充套件性。
對自旋鎖週期的選擇上,HotSpot認為最佳時間應是一個執行緒上下文切換的時間,但目前並沒有做到。經過調查,目前只是通過彙編暫停了幾個CPU週期,除了自旋週期選擇,HotSpot還進行許多其他的自旋優化策略,具體如下:
- 如果平均負載小於CPUs則一直自旋
- 如果有超過(CPUs/2)個執行緒正在自旋,則後來執行緒直接阻塞
- 如果正在自旋的執行緒發現Owner發生了變化則延遲自旋時間(自旋計數)或進入阻塞
- 如果CPU處於節電模式則停止自旋
- 自旋時間的最壞情況是CPU的儲存延遲(CPU A儲存了一個數據,到CPU B得知這個資料直接的時間差)
- 自旋時會適當放棄執行緒優先順序之間的差異
那synchronized實現何時使用了自旋鎖? 答案是線上程進入ContentionList時,也即第一步操作前。執行緒在進入等待佇列時首先進行自旋嘗試獲得鎖,如果不成功再進入等待佇列。這對那些已經在等待佇列中的執行緒來說,稍微顯得不公平。還有一個不公平的地方是自旋執行緒可能會搶佔了Ready執行緒的鎖。自旋鎖由每個監視物件維護,每個監視物件一個。
3. 偏向鎖
在JVM1.6中引入了偏向鎖,偏向鎖主要解決無競爭下的鎖效能問題, 首先我們看下無競爭下鎖存在什麼問題:
現在幾乎所有的鎖都是可重入的,也即已經獲得鎖的執行緒可以多次鎖住/解鎖監視物件,按照之前的HotSpot設計,每次加鎖/解鎖都會涉及到一些CAS操作(比如對等待佇列的CAS操作),CAS操作會延遲本地呼叫,因此偏向鎖的想法是一旦執行緒第一次獲得了監視物件,之後讓監視物件“偏向”這個執行緒,之後的多次呼叫則可以避免CAS操作,說白了就是置個變數,如果發現為true則無需再走各種加鎖/解鎖流程。 但還有很多概念需要解釋、很多引入的問題需要解決:
3.1 CAS及SMP架構
CAS為什麼會引入本地延遲?這要從SMP(對稱多處理器)架構說起,下圖大概表明了SMP的結構:
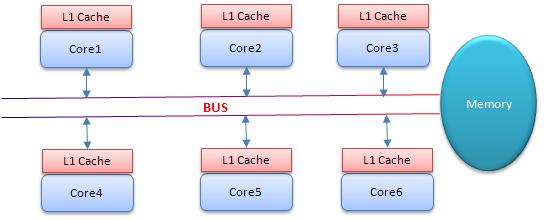
其意思是所有的CPU會共享一條系統匯流排(BUS),靠此匯流排連線主存。每個核都有自己的一級快取,各核相對於BUS對稱分佈,因此這種結構稱為“對稱多處理器”。
而CAS的全稱為Compare-And-Swap,是一條CPU的原子指令,其作用是讓CPU比較後原子地更新某個位置的值,經過調查發現,其實現方式是基於硬體平臺的彙編指令,就是說CAS是靠硬體實現的,JVM只是封裝了彙編呼叫,那些AtomicInteger類便是使用了這些封裝後的介面。
Core1和Core2可能會同時把主存中某個位置的值Load到自己的L1 Cache中,當Core1在自己的L1 Cache中修改這個位置的值時,會通過匯流排,使Core2中L1 Cache對應的值“失效”,而Core2一旦發現自己L1 Cache中的值失效(稱為Cache命中缺失)則會通過匯流排從記憶體中載入該地址最新的值,大家通過匯流排的來回通訊稱為“Cache一致性流量”,因為匯流排被設計為固定的“通訊能力”,如果Cache一致性流量過大,匯流排將成為瓶頸。而當Core1和Core2中的值再次一致時,稱為“Cache一致性”,從這個層面來說,鎖設計的終極目標便是減少Cache一致性流量。
而CAS恰好會導致Cache一致性流量,如果有很多執行緒都共享同一個物件,當某個Core CAS成功時必然會引起匯流排風暴,這就是所謂的本地延遲,本質上偏向鎖就是為了消除CAS,降低Cache一致性流量。
3.2 偏向解除
偏向鎖引入的一個重要問題是,在多爭用的場景下,如果另外一個執行緒爭用偏向物件,擁有者需要釋放偏向鎖,而釋放的過程會帶來一些效能開銷,但總體說來偏向鎖帶來的好處還是大於CAS代價的。
4. 總結
關於鎖,JVM中還引入了一些其他技術比如鎖膨脹等,這些與自旋鎖、偏向鎖相比影響不是很大,這裡就不做介紹。
通過上面的介紹可以看出,synchronized的底層實現主要依靠Lock-Free的佇列,基本思路是自旋後阻塞,競爭切換後繼續競爭鎖,稍微犧牲了公平性,但獲得了高吞吐量。