
【原創】Python+Scrapy+Selenium簡單爬取淘寶天貓商品資訊及評論
(轉載請註明出處)
哈嘍,大家好~
前言:這次寫這個小指令碼的目的是為了給老師幫個小忙,爬取某一商品的資訊,寫完覺得這個程式似乎也可以用在更普遍的地方,所以就放出來給大家看看啦,然後因為是在很短時間寫的,所以自然有很多不足之處,想著總之實現了功能再說吧,程式碼太醜大不了之後再重構吧(不存在的)
程式簡介:
廢話不多說,這個指令碼首先是基於scrapy框架實現的,因為前面也說了是一整個專案的一部分嘛,但是我這裡沒有寫出scrapy框架的其他部分,僅僅展示了spider檔案的程式碼,如果你不瞭解scrapy,也許你並不能看懂程式的某些部分,但是沒什麼關係,因為spider是框架相對獨立的一部分,所以你可以僅僅瞭解爬蟲的部分就行了。至於為什麼不寫出scrapy的其他部分,是因為實際上也並沒有對其他部分做什麼修改,只是建立了一個初始框架,甚至你也看不到對資料庫的輸出(因為我根本沒寫),但是我們還是可以從命令列得到所需的資料的,至於具體的使用,就看自己的需求了(比如可以簡單的把資料輸出到excel表格),重點還是在於對資料的爬取和分析,接下來我們就來分析一下功能吧
先明確一下目標:
1.指定任意一個或一類需要爬取的商品
2.爬取所有的商品連結
3.爬取所有商品連結的商品詳細資訊
4.我們這次爬取的資訊包括:
(1)商品名稱
(2)商品價格
(3)商品評論
以此來作為範例,當然同理也可以爬取其他資訊
具體實現:
(1)最重要的第一步,是要獲得商品的連結,但是要注意這裡的連結,如果你只爬取一個確定的商品的話那麼連結自然就是商品的介面連結,這樣自然是很容易的,只需在瀏覽器找到你的商品然後複製其連結就可以了,但是我們也希望找到所有店家出售的此商品,或者甚至是某一類商品(比如與python有關的所有書籍),這樣我們就不能只用一個連結,即url,來作為唯一的爬取物件。
所以我們的第一步其實是構建一個url的列表,以便之後的爬蟲爬取。
首先我們進入淘寶的搜尋介面,然後在搜尋欄輸入要搜尋的商品,點選搜尋
之後你自然會看到淘寶為你搜索出了所有有關的商品,這裡我們要做的是複製當前網頁的連結,這裡以搜尋python書籍為例
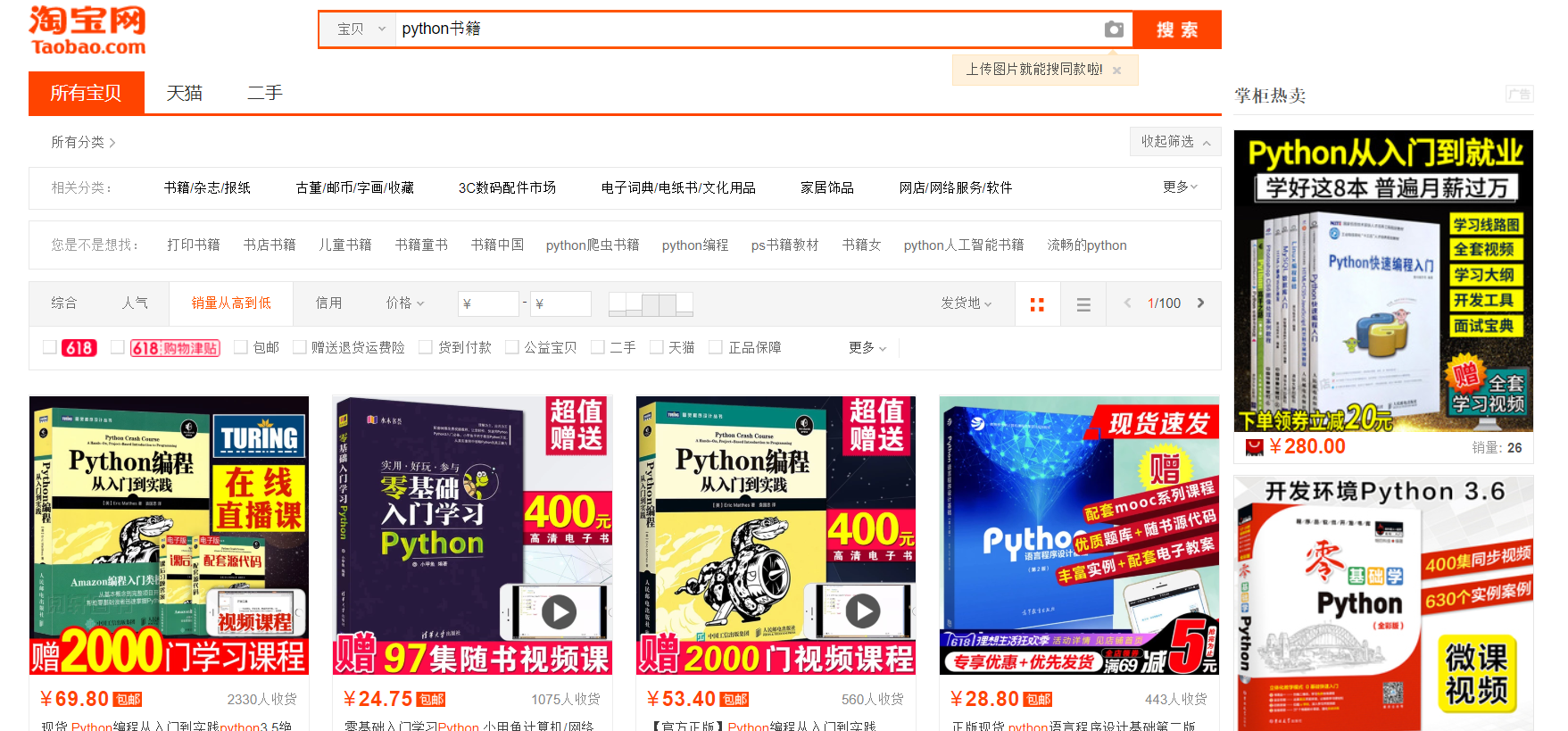

連結如下:
大部分沒什麼用,我們主要關注中間的https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=python%E4%B9%A6%E7%B1%8D&suggest=history_1&_input_charset=utf-8&wq=p&suggest_query=p&source=suggest&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=0
q=python%E4%B9%A6%E7%B1%8D你可以直接用 q=python書籍 替換它,這說明了q=的後面即是我們要輸入的商品名稱
然後我們再看連結的最後:
s=0這個s代表的就是商品的當前頁,當我點選第二頁時,s變為了s=44,可見頁數是以44位倍數的(也不知道是不是普遍如此)
所以我們要構建所有商品的資訊頁就可以寫成:
start_urls = []
#根據指定頁數新增商品列表,設定值為20頁
for i in range(0,20):
url="https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=python%E4%B9%A6%E7%B1%8D&suggest=history_1&_input_charset=utf-8&wq=p&suggest_query=p&source=suggest&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s="+str(i*44)
start_urls.append(url)start_urls是spider會自動爬取的url列表,所以我們只需要先把所有的url放入此列表就可以了
當然這還只是爬取了商品的所有搜尋介面的資訊,並不是每個商品的完整資訊,所以我們接下來要做的應該是繼續提取url,來訪問每個商品的具體購買介面,然後提取更詳細的資訊。
之後我會慢慢更新程式碼的具體作用和內容的
以下為全部的程式碼(這裡我們以爬取所有Python書籍的商品為例)
import scrapy
from scrapy.spiders import CrawlSpider
from selenium import webdriver
import re,requests
#構建評論頁表
def makeURL(itemId,sellerId,i):
url='http://rate.tmall.com/list_detail_rate.htm?itemId='\
+itemId+'&sellerId='+sellerId+'¤tPage='+i
return url
class taobaospider(CrawlSpider):
name = "taobao"
start_urls = [
"https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=python%E4%B9%A6%E7%B1%8D&suggest=history_1&_input_charset=utf-8&wq=p&suggest_query=p&source=suggest&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=0"
]
#根據指定頁數新增商品列表,設定值為20頁
for i in range(1,2):
url="https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=python%E4%B9%A6%E7%B1%8D&suggest=history_1&_input_charset=utf-8&wq=p&suggest_query=p&source=suggest&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s="+str(i*44)
start_urls.append(url)
def parse(self, response):
#需要通過selenium啟動虛擬瀏覽器,如果使用其他瀏覽器需作出修改
driver=webdriver.Chrome()
driver.get(response.url)
driver.implicitly_wait(30)
driver.refresh()
driver.implicitly_wait(30)
html = driver.page_source
driver.close()
#新增訪問商品詳細介面的url
list=re.findall('href=\"//detail.tmall.com.*?\"', html)
linkList = sorted(set(list), key=list.index)
#新增銷量資料
sales=re.findall('>[0-9]*人收貨', html)
i=0
for href in linkList:
link = 'https:'+href.split('"')[1]
sale=sales[i].replace('>', '').replace("人收貨", "")
i=i+1
yield scrapy.Request(url=link, meta={'sales':sale}, callback=self.parse_item)
def parse_item(self, response):
#根據實際item名稱修改此處
item = GameItem()
#獲取商品銷量
item['sales']=response.meta['sales']
#從商品介面提取資訊以構建評論介面的url
try:
str1 = re.findall('itemId:\".*?\"', response.text)[0]
itemId = str1.split(' ')[1]
str2 = re.findall('sellerId:\".*?\"', response.text)[0]
sellerId = str2.split(' ')[1]
except:
return
#初始化評論列表
comments = []
comment_times = []
#爬取所需評論頁數,設定值為爬取100頁,如果沒有評論則結束
for i in range(1,2):
try:
url_comment = makeURL(itemId, sellerId, str(i))
page=requests.get(url_comment)
page.status_code
comment = re.findall('\"rateContent\":(\".*?\")', page.text)
comment_time=re.findall('\"rateDate\":(\".*?\")', page.text)
comments.extend(comment)
comment_times.extend(comment_time)
except:
break
#輸入評論
item['comment'] = comments
item['comment_time'] = comment_times
#獲取商品其他資訊,(以@為分割符)
details=response.xpath('//ul[@id="J_AttrUL"]/li/text()').extract()
details="@".join(details)
details=details+"@"
#輸入item
try:
item['name']=re.findall('書名:(.*?)@',details)[0].replace('書名:', '').replace("\xa0","")
except:
pass
try:
item['ISBN']=re.findall('ISBN編號:(.*?)@',details)[0].replace('ISBN編號:', '').replace("\xa0","")
except:
pass
try:
item['writer']=re.findall('作者:(.*?)@',details)[0].replace('作者:', '').replace("\xa0","")
except:
pass
try:
item['price']=re.findall('定價:(.*?)@',details)[0].replace('定價:', '').replace("\xa0","")
except:
pass
try:
item['company'] = re.findall('出版社名稱:(.*?)@', details)[0].replace('出版社名稱:', '').replace("\xa0","")
except:
pass
yield item