《利用Python進行資料分析》 例項:USDA食品資料庫
阿新 • • 發佈:2019-01-30
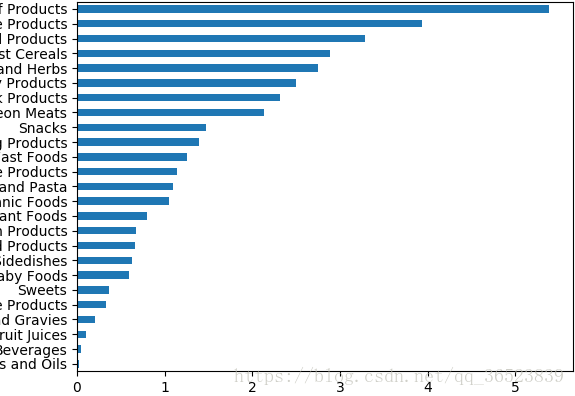
USDA食品資料庫:
from pandas import DataFrame,Series from pylab import * import pandas as pd import json def groupby(ndata): result = ndata.groupby(['nutrient','groupp'])['value'].quantile(0.5) result['Zinc, Zn'].sort_values().plot(kind='barh') show() def combination(info,nutrients): ndata = pd.merge(nutrients,info,on='id',how='outer') #連線兩個DataFrame groupby(ndata) def changename(nutrients,data): info_keys = ['description','group','id','manufacturer'] #只獲取這四列 info = DataFrame(data,columns=info_keys) rename1 = {'description':'breed','group':'groupp'} info = info.rename(columns=rename1,copy=False) #為避免兩個DataFrame的名字重複修改名字 rename2 = {'description':'nutrient','group':'groupq'} nutrients = nutrients.rename(columns=rename2,copy=False) #為避免兩個DataFrame的名字重複修改名字 print(info) combination(info,nutrients) def lists(data): nutrients = [] for res in data: #把所有的事物的營養項轉換為DataFrame fnuts = DataFrame(res['nutrients']) fnuts['id'] = res['id'] nutrients.append(fnuts) nutrients = pd.concat(nutrients,ignore_index=True) #連線列表中所有的項 nutrients = nutrients.drop_duplicates() #去掉重複的資料 changename(nutrients,data) def decode(path): data = json.load(open(path)) #解json為python lists(data) if __name__=="__main__": path = r"D:\pythonAnalysis\Python for Data Analysis-1st-edition\pydata-book-1st-edition\ch07\foods-2011-10-03.json" decode(path) #匯入檔案路徑