
C++基礎資料結構STL
在C++裡有寫好的標準模板庫,我們稱為STL庫,它實現了集合、對映表、棧、佇列等資料結構和排序、查詢等演算法。我們可以很方便地呼叫標準庫來進行各類操作。
動態陣列
引用庫
有時候想開一個數組,但是卻不知道應該開多大長度的數組合適,因為我們需要用到的陣列可能會根據情況變動,是個時候就需要我們用到動態陣列了。
C++中的動態陣列寫作 vector,它的實現被寫在 vector 的標頭檔案中,並在所有標頭檔案之後加上一句 using namespac std。
#include <vector>
using namespace std;
int main() {
return 構建一個動態陣列
現在我們來構造一個動態陣列。
C++中直接構造一個vector的語句為:
vector<T>vec;這樣我們定義了一個名為 vec 的儲存 T 型別資料的動態陣列。其中 T 是我們要儲存的資料型別,可以是 int、float、double 或者其他自定義的資料型別等等。初始的時候 vec 是空的。
插入元素
C++中通過 push_back ( ) 方法在陣列最後面插入一個新的元素。
#include <vector>
using namespace std;
int main() {
vector<int 獲取長度並且訪問元素
C++ 中通過 size ( ) 方法獲取 vector 的長度,通過 [ ] 操作直接訪問 vector 中的元素,這一點和陣列是一樣的。
#include <vector>
#include <stdio.h>
using namespace std;
int main() {
vector 修改元素
C++ 中修改 vector 中某個元素很簡單,只需要用 = 給它賦值就好了,比如 vec[1]=3。
#include <vector>
#include <stdio.h>
using namespace std;
int main() {
vector<int> vec; // []
vec.push_back(1); // [1]
vec.push_back(2); // [1, 2]
vec.push_back(3); // [1, 2, 3]
vec[1] = 3; // [1, 3, 3]
vec[2] = 2; // [1, 3, 2]
for (int i = 0; i < vec.size(); ++i) {
printf("%d\n", vec[i]);
}
return 0;
}清空
C++需呼叫 clear( ) 方法就可以清空 vector 。
C++中 vector 的 clear( ) 只是清空 vector ,並不會清空開的記憶體。用一種方法可以清空 vector 的記憶體。先定義一個空的 vector x,然後用需要清空的 vector 和 x 交換,因為 x 是區域性變數,所以會被系統回收記憶體(注意:大括號一定不能去掉)。
vector<int> v;
{
vector<int> x;
v.swap(x);
}C++ vector 方法總結
| 方法 | 功能 |
|---|---|
| push_back | 在末尾加入一個元素 |
| pop_back | 在末尾彈出一個元素 |
| size | 獲取長度 |
| clear | 清空 |
集合
集合是數學中的一個基本概念,通俗地講,集合是由一些不重複的資料組成的。比如 { 1 , 2 , 3 } 就是一個有1,2,3的集合。C++的標準庫中的集合支援高效的插入、刪除合查詢操作,這三個操作的時間複雜度都是 O(lgn),其中n是當前集合中元素的個數。如果用陣列,雖然插入的時間複雜度是 O(1),但是刪除合查詢都是 O(n),此時效率太低。在C++中我們常用的集合是set。
引用庫
C++中的集合實現被寫在 set 的標頭檔案中,並在所有標頭檔案之後加上一句 using namespac std。
#include <set>
using namespace std;構造一個集合
現在我們來構造一個集合。
C++中直接構造一個 set 的語句為:
set<T> s;這樣我們定義了一個名為s的、儲存T型別資料的集合,其中T是集合要儲存的資料型別。初始的時候s是空集合。
插入元素
C++中用 insert( ) 方法向集合中插入一個新的元素。注意如果集合中已經存在了某個元素,再次插入不會產生任何效果,集合中是不會出現重複元素的。
#include <set>
#include <string>
using namespace std;
int main() {
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
return 0;
}刪除元素
C++中通過 erase( ) 方法刪除集合中的一個元素,如果集合中不存在這個元素,不進行任何操作。
#include <set>
#include <string>
using namespace std;
int main() {
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
country.erase("America"); // {"China", "France"}
country.erase("England"); // {"China", "France"}
return 0;
}查詢元素
C++中如果你想知道某個元素是否在集合中出現,你可以直接用 count( ) 方法。如果集合中存在我們要查詢的元素,返回 1 ,否則返回 0 。
#include <set>
#include <string>
#include <stdio.h>
using namespace std;
int main() {
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
if (country.count("China")) {
printf("China belong to country");
}
return 0;
}遍歷元素
C++ 通過迭代器可以訪問集合中的每個元素,迭代器就好比只想集合中的元素的指標。如果你不瞭解迭代器,你只需要先記住。
#include <set>
#include <string>
#include <iostream>
using namespace std;
int main() {
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
for (set<string>::iterator it = country.begin(); it != country.end(); ++it) {
cout << (*it) << endl;
}
return 0;
}注意:在C++中遍歷set是從小到大進行的。
清空
C++中只需要呼叫 clear( ) 方法就可以清空 set 。
C++ set方法總結
| 方法 | 功能 |
|---|---|
| insert | 插入一個元素 |
| erase | 刪除一個元素 |
| count | 判斷元素是否在set中 |
| size | 獲取元素的個數 |
| clear | 清空 |
對映
對映是指兩個集合之間的元素的相互對應關係。通俗地說,就是一個元素對應另外一個元素。比如一個姓名的集合 {“Tom”, “Jone”, “Marry”},班級集合{1, 2}。姓名與班級之間可以有如下的對映關係:
class(“Tom”) = 1 , class(“Jone”) = 2 , class(“Marry”) = 1
我們稱其中的姓名集合為 關鍵字集合(key) , 班級集合為 值集合(value) 。
在 C++ 中我們常用的對映是 map。
引用庫
C++中的map實現被寫在 set 的標頭檔案中,並在所有標頭檔案之後加上一句 using namespac std。
#include <map>
using namespace std;構造一個對映
現在我們來構造一個對映。
在C++中,我們構造一個 map 的語句為:
map<T1,T2> m;這樣我們定義了一個名為 m 的從 T1 型別到 T2 型別的對映。初始的時候 m 是空對映。
插入對映
在 C++ 中通過 insert( ) 方法向集合中插入一個新的對映,引數是一個 pair 型別的結構。這裡需要用到另外一個 STL 模板 —— 元組(pair)。
pair<int,char>(1,'a');定義了一個整數 1 合字元 a 的 pair。我們向對映中加入了新對映對的時候就是通過加入 pair 來實現的。如果插入的 key 之前已經有了 value,不會用插入的新的 value 替代原來的 value,也就是此次插入是無效的。
#include <map>
#include <string>
using namespace std;
int main() {
map<string, int> dict; // {}
dict.insert(pair<string, int>("Tom", 1)); // {"Tom"->1}
dict.insert(pair<string, int>("Jone", 2)); // {"Tom"->1, "Jone"->2}
dict.insert(pair<string, int>("Mary", 1)); // {"Tom"->1, "Jone"->2, "Mary"->1}
dict.insert(pair<string, int>("Tom", 2)); // {"Tom"->1, "Jone"->2, "Mary"->1}
return 0;
}訪問對映
在 C++ 中訪問對映合數組一樣,直接用 [] 就能訪問。比如 dict[“Tom”] 就可以獲取 “Tom” 的班級了。而這裡有一個比較神奇的地方,如果沒有對 “Tom” 做過對映的話,此時你訪問 dict[“Tom”] ,系統將會自動為 “Tom” 生成一個對映,其 value 為對應型別的預設值。並且我們可以之後再給對映賦予新的值,比如 dict[“Tom”] = 3 ,這樣為我們提供了另一種方便的插入手段。當然有些時候,我們不希望系統自動為我們生成對映,這時候我們需要檢測 “Tom” 是否已經有映射了,如果已經有對映再繼續訪問。這時候就需要用 count( ) 函式進行判斷。
#include <map>
#include <string>
#include <stdio.h>
using namespace std;
int main() {
map<string, int> dict; // {}
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
printf("Mary is in class %d\n", dict["Mary"]);
printf("Tom is in class %d\n", dict["Tom"]);
return 0;
}查詢關鍵字
在 C++ 中,如果你想知道某個關鍵字是否被對映過,你可以直接用 count( ) 方法。如果被對映過,返回 1 ,否則返回 0 。
#include <map>
#include <string>
#include <stdio.h>
using namespace std;
int main() {
map<string, int> dict; // {}
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
if (dict.count("Mary")) {
printf("Mary is in class %d\n", dict["Mary"]);
} else {
printf("Mary has no class");
}
return 0;
}遍歷對映
在 C++ 中,通過迭代器可以訪問對映中的每個對映,每個迭代器的 first 值對應 key,second 值對應 value。
#include <map>
#include <string>
#include <iostream>
using namespace std;
int main() {
map<string, int> dict; // {}
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
for (map<string, int>::iterator it = dict.begin(); it != dict.end(); ++it) {
cout << it->first << " is in class " << it->second << endl;
}
return 0;
}清空
C++ 中只需要呼叫 Clear( ) 即可清空 map。
C++中map常用方法總結
| 方法 | 功能 |
|---|---|
| insert | 插入一對對映 |
| count | 查詢關鍵字 |
| erase | 刪除關鍵字 |
| size | 獲取對映對個數 |
| clear | 清空 |
棧
棧(stack),又名堆疊,是一種運算受限制的線性表型別的資料結構。其限制是只允許在棧的一段進行插入和刪除運算。這一端被稱為棧頂,相對地,把另一端稱為棧底。
可以想像往子彈夾中裝子彈的情形,正常情況下只能往子彈夾入口那端裝入子彈,這一步就好比向棧中壓入元素,稱為 push,射擊的時候,彈夾會從頂端彈出子彈,這一步就好比從棧頂彈出元素,稱為 pop,可以發現,從棧頂彈出的子彈是最後一個壓進去的子彈,這也是棧的一個重要性質,先進後出(FILO——first in last out)。另外,用一個 top 指標表示當前棧頂的位置。
下圖演示棧的 push 和 pop 的過程。
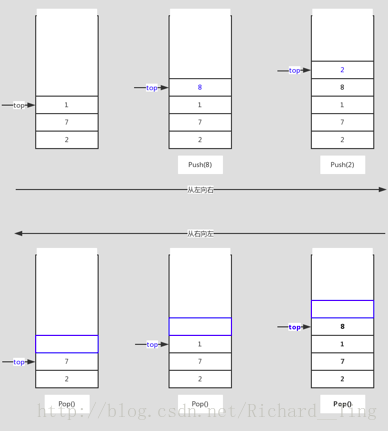
棧的實現
關於棧的實現,一種方法是利用陣列手動實現,需要固定快取大小,也就是陣列的大小。
int stack[maxsize], top = 0;
void push(int x) {
stack[top++] = x;
}
void pop() {
--top;
}
int topval() {
return stack[top - 1];
}
int empty() {
return top > 0;
}用 stack 表示儲存棧的空間,top 表示當棧頂的指標位置,方法 push( ) 壓入一個數 x 到棧頂,方法 pop( ) 從棧頂彈出一個元素,方法 topval( ) 獲取棧頂元素。
然而 C++ 中已經有寫好的棧的物件,可以直接用。
#include <stack>
#include <iostream>
using namespace std;
stack<int> S;
int main() {
S.push(1);
S.push(10);
S.push(7);
while (!S.empty()) {
cout << S.top() << endl;
S.pop();
}
return 0;
}上面是 C++ 裡的 stack 的用法。push,pop 分別是壓棧和出棧,top 是棧頂元素,empty 判斷棧是否為空。
棧的兩個經典的應用
- 火車車廂入站和出站順序確定。火車進展的時候車廂編號為從前到後一次 1,2,3,4,5,然後確定一個出站順序是否合法。這裡站臺就是一個棧的結構。需要遵循先進後出的順序。用一個棧模擬就可以得到出站順序是否合理。
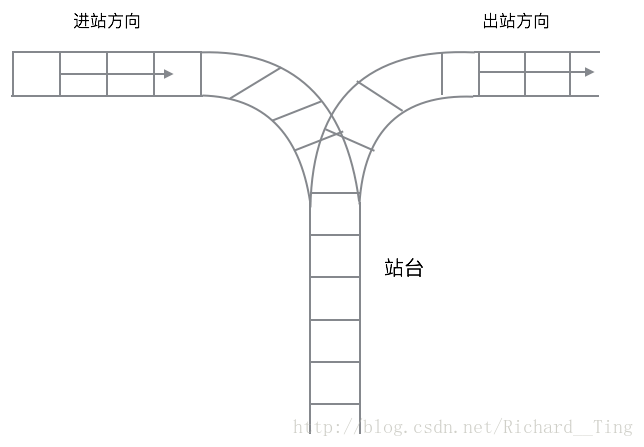
2.用來判斷括號是否匹配,經常遇到表示式裡面的括號很多的情況,有很多方法來判斷,其中最簡單的一個方法就是用棧來判斷。掃描一遍字串,當遇到 ‘(’ ,壓入棧;當遇到 ‘)’ 的時候,從棧中彈出一個 ‘(’ ,如果棧為空無法彈出元素,說明不合法。最後,如果棧中還有 ‘(’ 也不合法。
佇列
佇列(queue)是一種線性的資料結構,和棧一樣是一種運算受限制的線性表。其限制只允許從表的前端(front)進行刪除操作,而在表的後端(rear)進行插入操作。一般允許進行插入的一端我們稱為隊尾,允許刪除的一端稱為隊首。佇列的插入操作又叫入隊,佇列的刪除操作又叫出隊。
可以把佇列想像成購物時排隊結賬的時候的隊伍,先排隊的人會先結賬,後排隊的人會後結賬,並且不允許有插隊的行為,只能在隊伍的末尾進行排隊。這就是佇列的特點,具有先進先出(FIFO——First in First out)的性質。
佇列的結構如圖示:

佇列的主要操作包括:
+ 入隊(push)
+ 出隊(pop)
+ 判斷佇列是否為空(empty)
+ 統計佇列元素的個數(size)
+ 訪問隊頭元素(front)
+ 訪問隊尾元素(back)
佇列的實現與使用
由於佇列和棧都是線性表,所以佇列也同樣可以用陣列模擬來手動實現。但是由於佇列的出隊和入隊在不同的兩端,所以我們要引入一個迴圈佇列的概念。
如果單純地用陣列進行模擬,那麼當有元素出隊的時候,我們有兩種方法處理剩餘的元素:第一種是保持隊首(front)位置不變,其餘所有的元素順序往前移動一位;第二種是讓隊首(front)向後移動一位,其餘每個元素的位置不變,也就是使現在的位置稱為新的隊首位置。
第一種方法需要移動佇列的所有元素,時間效率非常低,第二種只需要移動隊頭則變得非常簡單,但第二種會導致之前隊頭所在的位置以後不會再被用到,造成空間的浪費。迴圈佇列就解決了這個問題。
在實際使用佇列中,為了使佇列的空間能重複使用,一旦佇列的頭(front)或者尾(rear)超出了所分配的佇列空間,則讓它指向佇列的起始位置,從 MaxSize -1 增加 1 變成 0 。
例如,下圖是一個迴圈佇列,由於之前的出隊操作,導致 front 已經移動倒了 4 的位置,如果繼續新增元素那麼 rear 就會移動到 0 的位置。
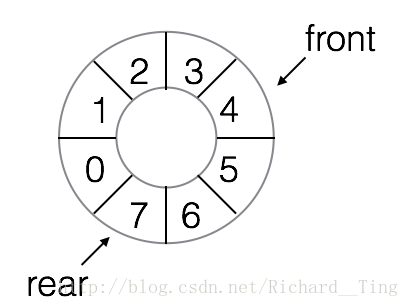
當元素裝滿整個佇列之後就會造成溢位,所以如果要動手實現佇列的話,最好提前預估佇列的最大容量。
手動實現:
#define maxsize 10000
class queue {
int q[maxsize];
int front, rear, count;
queue() {
front = 0;
rear = 0;
count = 0;
}
void push(int x) {
count++;
if (count == maxsize) {
// 溢位
}
q[rear] = x;
rear = (rear + 1) % maxsize;
}
int pop() {
count--;
front = (front + 1) % maxsize;
return q[front];
}
int front_val() {
return q[front];
}
bool empty() {
if (count == 0) {
return true;
}
return false;
}
};基本操作
| 操作 | C++ |
|---|---|
| 入隊 | push |
| 出隊 | pop |
| 訪問隊首元素 | front |
| 大小 | size |
| 是否為空 | empty |
#include <queue>
#include <iostream>
using namespace std;
int main() {
queue<int> q; // 宣告一個裝 int 型別資料的佇列
q.push(1); // 入隊
q.push(2);
q.push(3);
cout << q.size() << endl; // 輸出佇列元素個數
while (!q.empty()) { // 判斷佇列是否為空
cout << q.front() << endl; // 訪問隊首元素
q.pop(); // 出隊
}
return 0;
}優先佇列
原因:一些問題不能按照傳統模式先進先出,要優先訪問級別高的元素,這時,就產生了對優先佇列的思考。
在佇列中,元素從隊尾進入,從隊首刪除。相比佇列,優先佇列裡的元素增加了優先順序的屬性,優先順序高的元素先被刪除。
C++程式碼:
#include <queue>
#include <iostream>
using namespace std;
int main() {
priority_queue<int> q; // 宣告一個裝 int 型別資料的優先佇列
q.push(1); // 入隊
q.push(2);
q.push(3);
while (!q.empty()) { // 判斷佇列是否為空
cout << q.top() << endl; // 訪問佇列首元素
q.pop(); // 出隊
}
return 0;
}
/*
輸出為
3
2
1
*/例題講解
給出兩個包含 n 個整數的陣列 A,B。在 A、B 中任意取出一個數並將這兩個數相加,可以得到 n^2 個和。求這些和中最小的 n 個。
解析:如果按照樸素演算法,依次在 A 和 B 中分別取出一個數,然後生成和值,最後排序以後取前面的 n 個和。這樣的時間複雜度是 n^2lgn。效率不高。
我們可以藉助優先佇列來解決這題。首先把 A,B按照從小到大的順序排序。觀察下面這個表格。
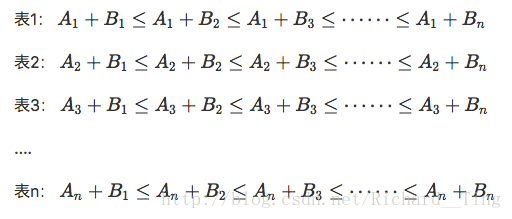
我們用一個結構 (sum,a,b) 來表示一個和值。
我們建立一個優先佇列q,佇列中 sum 越小優先順序越高。初始的時候,將(A[i]+B[1], i, 1)入隊。然後在隊中取出一個結構(sum, a, b),然後把結構(A[a]+B[b+1], a, b+1)重新入隊。這樣重複 n 次。取出的一次就是最小的 n 個和。任何時候,優先佇列中最多隻會有 n 個元素。所以這樣的複雜度是 nlgn。整個過程中,我們發現同一個表中,下標 a 其實不會變,所以可以不用記錄下標 a,這樣結構就可以簡化成(sum,b)。
推廣:
上面是隻有兩個陣列的。如果是 n 個數組,每個陣列取出一個元素,也可以用這個方法,每次合併兩個,合併 n 次就可以了。
優先佇列的優先順序過載
優先佇列,可以存放數值,也可以存放其他資料型別(包括自定義資料型別)。該容器支援查詢優先順序最高的這一操作,而優先順序的高低是可以自行定義的。
在C++中我們可以通過過載小於運算子 bool operator < 來實現。
比如整數,程式預設是數值較大的元素優先順序較高,我們一可以定義數值較小的元素優先順序較高。又比如下面的例子,定義距離值較小的 node 優先值較高。
struct node {
int dist, loc;
node() { }
bool operator < (const node & a) const {
return dist > a.dist;
}
};
priority_queue <node> Q;上述程式碼起到優先順序過載的作用,我們仍然可以進行 top,pop等操作。
並查集
並查集是一種樹型的資料結構,用於處理一些不相加集合的合併和查詢問題。在使用中常常以森林來表示。
並查集也是用來維護集合的,和 set 不同之處在於,並查集能很方便地同時維護很多集合。如果用 set 來維護會非常麻煩。並查集的核心思想是記錄每個結點的父親結點是哪個結點。
1)初始化:初始化的時候每個結點各自為一個集合,father[i]表示結點 i 的父親結點,如果father[i] = i,我們認為這個結點是當前集合的根節點。
void init() {
for (int i = 1; i <= n; ++i) {
father[i] = i;
}
}2)查詢:查詢結點所在集合的根節點,結點 x 的根節點必然也是其父親結點的根節點。
int get(int x) {
if (father[x] == x) { // x 結點就是根結點
return x;
}
return get(father[x]); // 返回父結點的根結點
}3)合併:將兩個元素所在的集合合併在一起,通常來說,合併之前先判斷兩個元素是否屬於同一集合。
void merge(int x, int y) {
x = get(x);
y = get(y);
if (x != y) { // 不在同一個集合
father[y] = x;
}
}路徑壓縮
前面的並查集的複雜度實際上在有些極端情況會很慢。比如樹的結構正好是一條鏈,那麼最壞情況下,每次查詢的複雜度達到了O(n)。這並不是我們期望的結果。
路徑壓縮的思想是,我們只關心每個結點的父結點,而並不太關心樹的真正的結構。這樣我們在一次查詢的時候,可以把查詢路徑上的所有結點的 father[i] 都賦值成為根節點。只需要做出如下改變:
int get(int x) {
if (father[x] == x) { // x 結點就是根結點
return x;
}
return father[x] = get(father[x]); // 返回父結點的根結點,並令當前結點父結點直接為根結點
//注意,這裡一次性將所有非根結點的結點都通過遞迴直接與根節點相連,成扁平狀。
}下圖是路徑壓縮前後的對比。
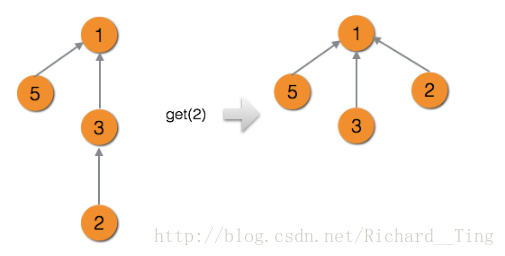
路徑壓縮在實際應用中效率很高,其依次查詢複雜度平攤下來可以認為是一個常數。並且在實際應用中,我們基本都用帶路徑壓縮的並查集。
帶權並查集
所謂帶權並查集,是指結點存有權值資訊的並查集。並查集以森林的形式存在,而結點的權值,大多是記錄該結點與祖先關係的資訊。比如權值可以記錄該結點到根節點的距離。
例題
在排隊過程中,初始時,一人一列。一共有如下兩種操作。
- 合併:令其中的兩個佇列 A,B 合併,也就是將佇列 A 排在佇列 B 的後面。
- 查詢:詢問某個人在其所在佇列中排在第幾位。
例題解析
我們不妨設 size[]為集合中的元素個數,dist[]為元素到隊首的距離,合併時,dist[A.root]需要加上size[B.root] (每個元素到隊首的距離應該是到根路徑上所有點的dist[]求和),size[B.root]需要加上size[A.root] (每個元素所在集合的元素個數只需查詢該集合中根的size[x.root])。
1)初始化:
void init() {
for(int i = 1; i <= n; i++) {
father[i] = i, dist[i] = 0, size[i] = 1;//初始化
}
}2)查詢:查詢元素所在的集合,即根節點。
int get(int x) {
if(father[x] == x) {
return x;
}
//下面1、2步為路徑壓縮,每個點都指向自己的根結點了。
//這裡一次性將所有非根結點的結點都通過遞迴直接與根節點相連,成扁平狀。
}
int y = father[x];//1 --得到x的父親節點
father[x] = get(y);//2 --將x直接指向根節點get(y)
dist[x] += dist[y]; // (x到根結點的距離) 等於 (x到之前父親結點距離) 加上 (之前父親結點到根結點的距離)
return father[x];
}路徑壓縮的時候,不需要考慮 size[],但 dist[] 需要更新成到整個集合根的距離。
3)合併
將兩個元素所在的集合合併為一個集合。
通常來說,合併之前,應先判斷兩個元素是否屬於同一個集合,這可用上面的“查詢”操作實現。
void merge(int a, int b) {
a = get(a);
b = get(b);
if(a != b) { // 判斷兩個元素是否屬於同一集合
father[a] = b;
dist[a] += size[b];//原因是A隊伍跑到B隊伍後面去了,注意這是針對例題的
size[b] += size[a];
}
}通過小小的改動,我們就可以查詢並查集這一森林中,每個元素到祖先的相關資訊。