
大資料開發進階之HBase開發例項介紹
這周學習了HBase的開發例項,主要有一些HBase API的使用。(文中的程式碼,是經過實際執行有效的,只擷取片段,關於全部的可參考前一篇文章中全域性變數的設定,關於執行環境也與前一篇一樣)
一、HBase基本操作
1.追加插入-Append
在原有的value中追加值,即在其後追加值,例如原有value為a,追加b之後value值為ab
//追加資料 public static void appendData(String tablename) { TableName tableName = TableName.valueOf(tablename); try { Connection conn = ConnectionFactory.createConnection(configuration); Table table = conn.getTable(tableName); //建立Append物件,rowkey為"rowkey1" Append append = new Append("rowkey1".getBytes()); // 在append物件中設定列族、列、值 append.add("column1".getBytes(), "name".getBytes(), "123".getBytes()); // 追加資料 table.append(append); // 關閉資源 table.close(); conn.close(); } catch (IOException e) { e.printStackTrace(); } }
執行之前資料
rowkey1 column=column1:name, timestamp=1477141062736, value=aaa
執行之後資料
rowkey1 column=column1:name, timestamp=1477141062736, value=aaa123
2.符合條件插入-CheckAndPut
檢查是否有符合某個條件的值,有的話則插入資料,這裡的插入是會替換原有的值。
結果如下:插入之前值為ccc,插入之後值為ddd//檢查符合某一條件則插入資料 public static void checkAndPutData(String tablename) { try { TableName tableName = TableName.valueOf(tablename); Connection conn = ConnectionFactory.createConnection(configuration); //獲取tablename表 Table htable = conn.getTable(tableName); //Put 單個插入,rowkey為rowkey3 Put put = new Put("rowkey3".getBytes()); //列族為column1,列為name,可有多行,value值為ddd,這裡值都需要轉化為bytes型別,hbase都是以bytes儲存 put.addColumn("column1".getBytes(), "name".getBytes(), "ddd".getBytes()); //檢查是否有值是否存在,若存在則插入 boolean result = htable.checkAndPut("rowkey3".getBytes(), "column1".getBytes(), "name".getBytes(), "ccc".getBytes(), put); //插入 htable.put(put); htable.close(); conn.close(); } catch (IOException e) { e.printStackTrace(); } }

3.符合條件刪除-CheckAndDelete
檢查是否有符合某個條件的值,有的話則刪除某一行。
執行後的結果如下//檢查符合某一條件則刪除資料 public static void checkAndDeleteData(String tablename) { try { TableName tableName = TableName.valueOf(tablename); Connection conn = ConnectionFactory.createConnection(configuration); //獲取tablename表 Table htable = conn.getTable(tableName); //申請delete物件,rowkey為rowkey3 Delete delete = new Delete("rowkey3".getBytes()); //列族為column1,列為name delete.addColumn("column1".getBytes(), "name".getBytes()); //檢查是否有值是否存在,若存在則刪除 htable.checkAndDelete("rowkey3".getBytes(), "column1".getBytes(), "name".getBytes(), "ccc".getBytes(), delete); System.out.println("delete=========end"); htable.close(); conn.close(); } catch (IOException e) { e.printStackTrace(); } }

4.計數器-incrementColumnValue
用於實時收集資訊,如點贊之類的。0代表獲取當前值,正數則加,負數則減。
//計數器
public static void incrementColumn(String tablename)
{
try {
TableName tableName = TableName.valueOf(tablename);
Connection conn = ConnectionFactory.createConnection(configuration);
//獲取tablename表
Table htable = conn.getTable(tableName);
//為某一行計數
long result = htable.incrementColumnValue("rowkey3".getBytes(), "column1".getBytes(), "name".getBytes(), 5);
//列印計數結果
System.out.println("the num is:" + result);
} catch (IOException e) {
e.printStackTrace();
}
}二、HBase過濾器
1.Rowkey過濾器-RowFilter
Rowkey過濾器主要對rowkey進行過濾,通過條件的設定獲得想要的行列。一般情況下不太使用filter,因為會降低執行的效率。
以下為程式碼的示例,其中RowFilter的條件設定為EQUAL(相等),還可設定為NOT_EQUAL(不等於),GREATER_OR_EQUAL(大於或等於)等一些值,如果滿足條件,則輸出。
比較器使用的是BinaryComparator,全字元比較,匹配完整的字元。
還有以下幾種:
BinaryPrefixComparator 匹配位元組陣列字首
BitComparator
NullComparator
RegexStringComparator 正則表示式匹配
SubstringComparator 子串匹配setCacheBlocks 設定獲取的資料是否存在於記憶體中,一般設定為false,提高hbase查詢的效能
//rowkey過濾器
public static void rowkeyFilter(String tablename)
{
TableName tableName = TableName.valueOf(tablename);
try {
Connection conn = ConnectionFactory.createConnection(configuration);
Table table = conn.getTable(tableName);
Scan scan = new Scan();
scan.setCacheBlocks(false);
Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(("abc").getBytes()));
scan.setFilter(filter);
ResultScanner results = table.getScanner(scan);
//每一行和每一列組成一個cell
for(Result result:results)
{
Cell[] cells = result.rawCells();
for(Cell cell:cells) {
//列印rowkey
System.out.println("RowKey:"+new String(CellUtil.cloneRow(cell))+" ");
//列印時間戳
System.out.println("Timetamp:"+cell.getTimestamp()+" ");
//列印列族
<span style="white-space:pre"> </span>System.out.println("column Family:"+new String(CellUtil.cloneFamily(cell))+" ");
<span style="white-space:pre"> </span>//列印行名
<span style="white-space:pre"> </span>System.out.println("row Name:"+new String(CellUtil.cloneQualifier(cell))+" ");
<span style="white-space:pre"> </span>//列印value值
<span style="white-space:pre"> </span> System.out.println("value:"+new String(CellUtil.cloneValue(cell))+" ");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}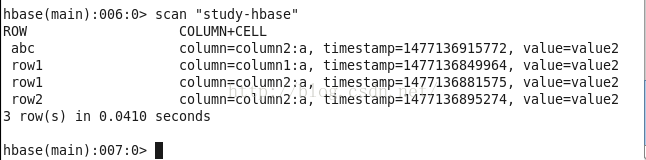
執行之後的結果如下:

2.Qualifier過濾器-QualifierFilter
QualifierFilter是基於列(column)的比較,與rowkey相似,與此相似的還有FamilyFilter,基於列族的比較。一般Qualifier比Family較常用。
QuaiifierFilter對大小寫敏感。
這裡就不舉例了。
3.FilterList
FilterList 過濾器鏈,它包含一組滿足於條件的資料。引數有FilterList.Operator.MUST_PASS_ALL 和FilterList.Operator.MUST_PASS_ONE 兩種,表達形式如下:
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ONE); //資料只要滿足一組過濾器中的一個就可以
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ALL); //資料必須滿足所有過濾器4.列值過濾器-SingleColumnValueFilter
SingleColumnValueFilter 列值過濾器 過濾列值是否滿足於某個條件的
setFilterIfMissing可設定為true或者false,其意義在於若符合我們設定的某一列值本身不存在,則是否過濾掉。
設定為true,則過濾掉;設定為false,則不過濾掉。預設為false
以下例子為FilterList和SingleColumnValunFilter結合使用
</pre><pre name="code" class="java">public static void filterList(String tablename)
{
TableName tableName = TableName.valueOf(tablename);
try {
Connection conn = ConnectionFactory.createConnection(configuration);
Table table = conn.getTable(tableName);
Scan scan = new Scan();
scan.setCacheBlocks(false);
//設定為MUST_PAST_ALL,過濾器中的條件必須同時滿足
FilterList filterlist = new FilterList(FilterList.Operator.MUST_PASS_ALL);
//過濾列值大於或等於某一個值
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(
"column1".getBytes(),
"num".getBytes(),
CompareOp.GREATER_OR_EQUAL,
"20".getBytes());
filter1.setFilterIfMissing(true);
filterlist.addFilter(filter1);
//過濾列值小於或等於某一個值
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(
"column1".getBytes(),
"num".getBytes(),
CompareOp.LESS_OR_EQUAL,
"30".getBytes());
//設定某一列值若本身不存在,則過濾掉
filter1.setFilterIfMissing(true);
filterlist.addFilter(filter2);
scan.setFilter(filterlist);
ResultScanner results = table.getScanner(scan);
//每一行和每一列組成一個cell
for(Result result:results)
{
Cell[] cells = result.rawCells();
for(Cell cell:cells) {
//列印rowkey
System.out.print("RowKey:"+new String(CellUtil.cloneRow(cell))+" ");
//列印時間戳
System.out.print("Timetamp:"+cell.getTimestamp()+" ");
//列印列族
System.out.print("column Family:"+new String(CellUtil.cloneFamily(cell))+" ");
//列印行名
System.out.print("row Name:"+new String(CellUtil.cloneQualifier(cell))+" ");
//列印value值
System.out.println("value:"+new String(CellUtil.cloneValue(cell))+" ");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}使用的tablename為study-habse1,表中的資料如下:
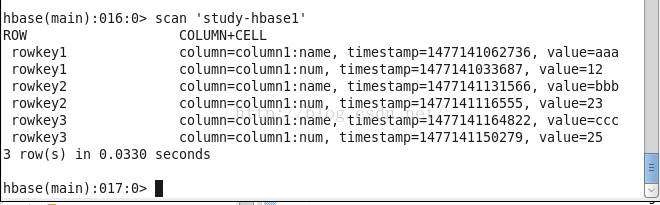
執行之後,結果如下,獲取列值在20到30之間的行
