
Spark學習筆記03:高階運算元
阿新 • • 發佈:2019-01-30
1.在slave的機器上啟動start-master.sh會出現錯誤的問題如果在mini2上啟動start-master.sh,會出現問題。spark會在mini2本地上啟動master,而不會通過ssh遠端啟動mini1的master。詳細資訊可以之後檢視spark的啟動指令碼。2.spark叢集啟動過程首先在mini1上啟動master程序,之後通過ssh在別的機器上啟動worker程序。之後master與worker之間的通訊心跳報活等是rpc通訊。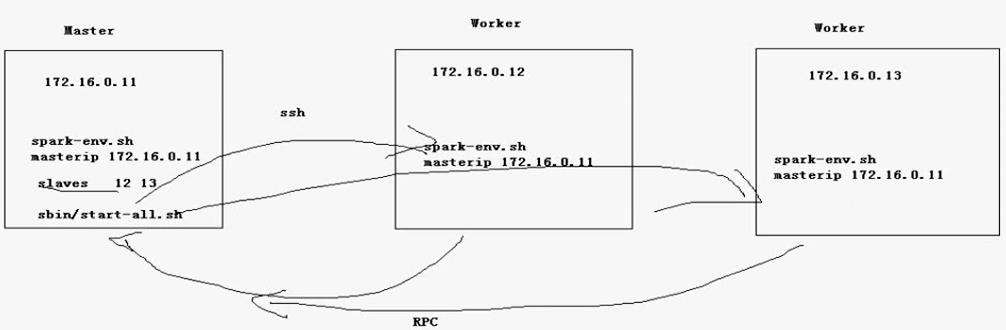
3.spark高階運算元3.1 Transformation: mapPartitions(func) 對每個分割槽Partition進行操作 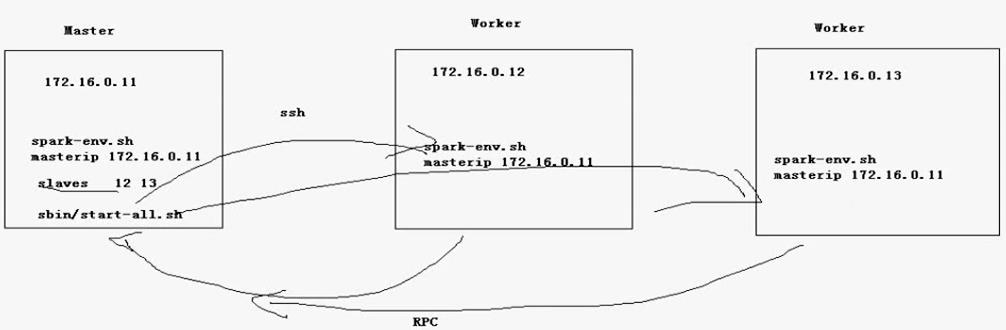
val rdd = sc.parallelize(List(1,2,3,4,5,6,7),2)# scala> val func1 = (iter:Iterator[Int])=>{iter.toList.map(x=>"value:"+x).toIterator}func1: Iterator[Int] => Iterator[String] = <function1># scala> rdd.mapPartitions(func1).collectres2: Array[String] = Array(value:1, value:2, value:3, value:4, value:5, value:6, value:7)3.2 
# scala> val func = (index:Int,iter:Iterator[Int])=>{ | iter.toList.map(x=>"[part:"+ index+" value:"+x+"]").toIterator}func: (Int, Iterator[Int]) => Iterator[String] = <function2># scala> rdd.mapPartitionsWithIndex(func).collectres2: Array[String] = Array([part:0 value:1], [part:0 value:2], [part:0 value:3], [part:1 value:4], [part:1 value:5], [part:1 value:6], [part:1 value:7])3.3 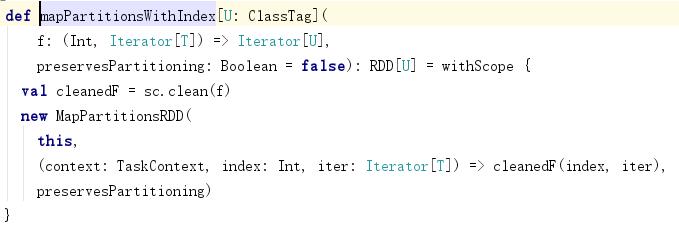
3.4 Action: aggregate (zV)(func1,func2) 先區域性聚合,再整體聚合 |初始值 |各個分割槽內部應用的函式(區域性) |對各個分割槽的結果應用的函式(整體聚合)
.1)aggregate(0)(_+_,_+_) 先區域性相加,再整體相加 #scala> rdd.aggregate(0)(_+_,_+_) res0: Int = 28.2) aggregate(0)(math.max(_,_),_+_) 從各個分割槽中選出最大數,之後相加得結果# scala> rdd.mapPartitionsWithIndex(func).collectres1: Array[String] = Array(part:0 value:1, part:0 value:2, part:0 value:3, part:1 value:4, part:1 value:5, part:1 value:6, part:1 value:7) 3+7=10# scala> rdd.aggregate(0)(math.max(_,_),_+_) res4: Int = 10.3) aggregate(10)(math.max(_,_),_+_) # scala> rdd.aggregate(10)(math.max(_,_),_+_)res6: Int = 30# scala> rdd.aggregate(20)(math.max(_,_),_+_)res7: Int = 60# scala> rdd.aggregate(5)(math.max(_,_),_+_)res8: Int = 17# scala> rdd.aggregate(1)(math.max(_,_),_+_)res11: Int = 11# scala> rdd.aggregate(2)(math.max(_,_),_+_)res12: Int = 12注意:
.4)aggregate("")(_ + _, _ + _) aggregate("=")(_ + _, _ + _)val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)# scala> val func = (index:Int,iter:Iterator[String])=>{ | iter.toList.map(x=>"partId:"+index+" val:"+x).toIterator}func: (Int, Iterator[String]) => Iterator[String] = <function2># scala> rdd2.mapPartitionsWithIndex(func).collectres16: Array[String] = Array(partId:0 val:a, partId:0 val:b, partId:0 val:c, partId:1 val:d, partId:1 val:e, partId:1 val:f)# scala> rdd2.aggregate("")(_ + _, _ + _)res17: String = abcdef# scala> rdd2.aggregate("=")(_ + _, _ + _)res18: String = ==abc=def注意:結果之所以又能會不同,是因為不同分割槽的運算處理速度不同,有時可能是分割槽0較快,有時可能是分割槽1較快,所以位置會有不同。scala> rdd1.aggregate("")(_+_,_+_)res18: String = 456123scala> rdd1.aggregate("")(_+_,_+_)res19: String = 123456.5) aggregate("")((x,y)=>{math.max(x.length,y.length).toString},_+_)val rdd3 = sc.parallelize(List("12","23","345","4567"),2)# scala> rdd3.mapPartitionsWithIndex(func).collectres20: Array[String] = Array(partId:0 val:12, partId:0 val:23, partId:1 val:345, partId:1 val:4567)# scala> rdd3.aggregate("")((x,y)=>{math.max(x.length,y.length).toString},_+_)res21: String = 24# scala> rdd3.aggregate("")((x,y)=>{math.max(x.length,y.length).toString},_+_)res2: String = 42注意:rdd3.aggregate("")((x,y)=>{math.max(x.length,y.length).toString},_+_)part0: max("".length,"12".length).toString=>max(0,2).toString=>2.toString=>"2" max("2".length,"23".length).toString=>max(1,2).toString=>2.toString=>"2"part1: max("".length,"345".length).toString=>max(0,3).toString=>3.toString=>"3" max("3".length,"4567".length).toString=>max(1,4).toString=>4.toString=>"4"全域性: ""+"2"=>"2" "2"+"4"=>"24"或者: 每個分割槽並行操作,速度有快有慢,有可能part0速度快,則結果是“24” 有可能part1速度快,則結果是“42” ""+"4"=>"4" "4"+"2"=>"42".6) aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)val rdd5 = sc.parallelize(List("12","23","","345"),2)# scala> rdd5.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)res4: String = 11val rdd6 = sc.parallelize(List("12","23","345",""),2)# scala> rdd6.mapPartitionsWithIndex(func).collect res13: Array[String] = Array(partID:0 val:12, partID:0 val:23, partID:1 val:345, partID:1 val:)# scala> rdd6.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)res11: String = 10# scala> rdd6.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)res12: String = 01注意:part0: min("".length,"12".length).toString=>min(0,2).toString=>0.toString=>"0" min("0".length,"23".length).toString=>min(1,2).toString=>1.toString=>"1"part1: min("".length,"345".length).toString=>min(0,3).toString=>0.toString=>"0" min("0".length,"".length).toString=>min(1,0).toString=>0.toString=>"0"全域性: ""+"1"="1" "1"+"0"="10"或者 part1速度比part0快 ""+"0"="0" "0"+"1"="01"3.5 Transformation: aggregateByKey 屬於PairRDDval pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)# scala> def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = { | iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator | }func2: (index: Int, iter: Iterator[(String, Int)])Iterator[String]# scala> pairRDD.mapPartitionsWithIndex(func2).collectres15: Array[String] = Array([partID:0, val: (cat,2)], [partID:0, val: (cat,5)], [partID:0, val: (mouse,4)], [partID:1, val: (cat,12)], [partID:1, val: (dog,12)], [partID:1, val: (mouse,2)])
.1) aggregateByKey(0)(_+_,_+_) 相當於 reduceByKey(_+_)# scala> pairRDD.aggregateByKey(0)(_+_,_+_).collectres16: Array[(String, Int)] = Array((dog,12), (cat,19), (mouse,6))# scala> pairRDD.reduceByKey(_+_).collectres19: Array[(String, Int)] = Array((dog,12), (cat,19), (mouse,6))注意:part0: cat: (0+2)=>2 (2+5)=>7 mouse:(0+4)=>4part1: cat:(0+12)=>12mouse:(0+2)=>2dog:(0+12)=>12全域性: cat:(7+12)=>19mouse:(4+2)=>6dog:12.2)aggregateByKey(0)(math.max(_,_),_+_)scala> pairRDD.aggregateByKey(0)(math.max(_,_),_+_).collectres17: Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6))注意:part0: cat: max(0,2)=>2 max(2,5)=>5 mouse:max(0,4)=>4part1: cat:max(0,12)=>12mouse:max(0,2)=>2dog:max(0,12)=>12全域性: cat:(5+12)=>17mouse:(4+2)=>6dog:12.3)aggregateByKey("=")(_+_,_+_)val rdd = sc.parallelize(List(("a","A"),("b","B"),("a","A"),("a","A"),("b","B"),("c","C")),2)#scala> val func1 = (index:Int,iter:Iterator[(String,String)])=>{ | iter.toList.map(x=>"part:"+index+" value:"+x).iterator}func1: (Int, Iterator[(String, String)]) => Iterator[String] = <function2>#scala> rdd.mapPartitionsWithIndex(func1).collectres8: Array[String] = Array(part:0 value:(a,A), part:0 value:(b,B), part:0 value:(a,A), part:1 value:(a,A), part:1 value:(b,B), part:1 value:(c,C))# scala> rdd.aggregateByKey("=")(_+_,_+_).collectres22: Array[(String, String)] = Array((b,=B=B), (a,=AA=A), (c,=C))注意:part0: a:("="+"A")=>"=A" ("=A"+"A")=>"=AA" b:("="+"B")=>"=B"part1: a:("="+"A")=>"=A" b:("="+"B")=>"=B" c:("="+"C")=>"=C"全域性: a:("=AA"+"=A")=>"=AA=A" b:("=B"+"=B")=>"=B=B" c:"=C".4) aggregateByKey(100)(math.max(_, _), _ + _)# scala> pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collectres27: Array[(String, Int)] = Array((dog,100), (cat,200), (mouse,200))3.6 Transformation: combineByKey(func1,func2,func3) 較為底層的方法 屬於PairRDD,reduceByKey,aggregateByKey底層呼叫的都是它
|x=>x,是對每個分割槽的每個key的第一個value進行操作.1) combineByKey(x=>x,(m:Int,n:Int)=>m+n,(a:Int,b:Int)=>a+b)val rdd1 = sc.textFile("hdfs://mini1:9000/wc").flatMap(_.split(" ")).map((_,1))# scala> rdd1.combineByKey(x=>x,(m:Int,n:Int)=>m+n,(a:Int,b:Int)=>a+b).collectres0: Array[(String, Int)] = Array((love,3), (leave,6), (i,3), (me,3), (us,3), (you,3), (girl,3), (hello,6), (kitty,3), (wanna,3), (away,6), (my,3)) |x=>x+10,是對每個分割槽的每個key的第一個value進行+10操作.2) combineByKey(x=>x+10,(m:Int,n:Int)=>m+n,(a:Int,b:Int)=>a+b)val rdd1 = sc.textFile("hdfs://mini1:9000/wc").flatMap(_.split(" ")).map((_,1))scala> rdd1.combineByKey(x=>x+10,(m:Int,n:Int)=>m+n,(a:Int,b:Int)=>a+b).collect res2: Array[(String, Int)] = Array((love,33), (leave,36), (i,33), (me,33), (us,33), (you,33), (girl,33), (hello,36), (kitty,33), (wanna,33), (away,36), (my,33))注意:當/wc下有3個檔案時(有3個block塊(<128m), 不是有3個檔案就有3個block, ), 每個key計算出的value會多加3個10
.3)combineByKey(x=>List(x),(m:List[String],n:String)=>m:+n, (a:List[String],b:List[String])=>a++b) 把相同的key的value放到同一個集合中val rdd4 = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)val rdd5 = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)val rdd6 = rdd5.zip(rdd4)# scala> rdd6.collectres3: Array[(Int, String)] = Array((1,dog), (1,cat), (2,gnu), (2,salmon), (2,rabbit), (1,turkey), (2,wolf), (2,bear), (2,bee))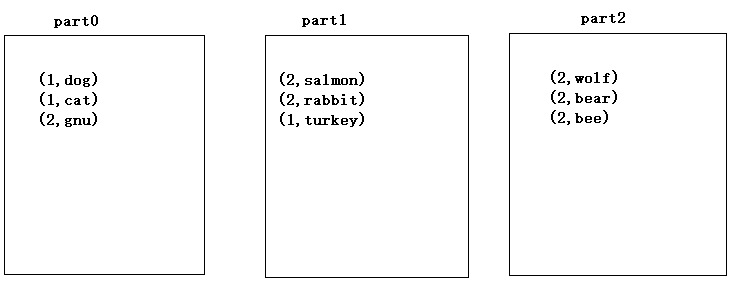
#scala> rdd6.combineByKey(x=>List(x),(m:List[String],n:String)=>m:+n, | (a:List[String],b:List[String])=>a++b).collectres4: Array[(Int, List[String])] = Array((1,List(dog, cat, turkey)), (2,List(gnu, salmon, rabbit, wolf, bear, bee)))注意:part0: 1:"dog"=>List("dog") List("dog"):+"cat"=>List("dog","cat") 2:"gnu"=>List("gnu")part1: 1:"turkey"=>List("turkey") 2:"salmon"=>List("salmon") List("salmon"):+"rabbit"=>List("salmon","rabbit")part2: 2:"wolf"=>List("wolf") List("wolf"):+"bear"=>List("wolf","bear") List("wolf","bear"):+"bee"=>List("wolf","bear","bee") 全域性: 1:List("dog","cat")++List("turkey")=>List("dog","cat","turkey") 2:List("gnu")++List("salmon","rabbit")=>List("gnu","salmon","rabbit") List("gnu","salmon","rabbit")++List("wolf","bear","bee")=> List("gnu","salmon","rabbit","wolf","bear","bee") 3.7 Transformation: repartition(n) 給rdd重新分割槽實際上,repartition(n)的實現呼叫了coalesce(n,true)
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)# scala> val func = (index: Int, iter: Iterator[(Int)]) => { | iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator | }func: (Int, Iterator[Int]) => Iterator[String] = <function2># scala> rdd1.mapPartitionsWithIndex(func).collectres0: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:0, val: 4], [partID:1, val: 5], [partID:1, val: 6], [partID:1, val: 7], [partID:1, val: 8], [partID:1, val: 9])# scala> val rdd2 = rdd1.repartition(3)rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at repartition at <console>:23# scala> rdd2.partitions.lengthres5: Int = 3# scala> rdd2.mapPartitionsWithIndex(func).collectres3: Array[String] = Array([partID:0, val: 3], [partID:0, val: 7], [partID:1, val: 1], [partID:1, val: 4], [partID:1, val: 5], [partID:1, val: 8], [partID:2, val: 2], [partID:2, val: 6], [partID:2, val: 9])3.8 Transformation: coalesce(n,shuffle=false) 合併val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)# scala> val func = (index: Int, iter: Iterator[(Int)]) => { | iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator | }func: (Int, Iterator[Int]) => Iterator[String] = <function2># scala> rdd1.mapPartitionsWithIndex(func).collectres0: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:0, val: 4], [partID:1, val: 5], [partID:1, val: 6], [partID:1, val: 7], [partID:1, val: 8], [partID:1, val: 9]) # scala> val rdd3 = rdd1.coalesce(3)rdd3: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:23# scala> rdd3.partitions.lengthres1: Int = 2# scala> rdd3.mapPartitionsWithIndex(func).collectres1: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:0, val: 4], [partID:1, val: 5], [partID:1, val: 6], [partID:1, val: 7], [partID:1, val: 8], [partID:1, val: 9])注意:coalesce(3)之後分割槽的情況並沒有改變,因為預設方法中引數shuffle=false(把一個機器上的資料通過網路移動到另一個機器上的過程)coalesce(n)如果shuffle為false時,如果傳入的引數大於現有的分割槽數目,最終結果RDD的分割槽數不變,也就是說不經過shuffle,是無法將RDD的分割槽數變多的。
實際上,repartition(n)的實現呼叫了coalesce(n,true)
# scala> val rdd4 = rdd1.coalesce(3,true)rdd4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at coalesce at <console>:23# scala> rdd4.partitions.lengthres1: Int = 3# scala> rdd4.mapPartitionsWithIndex(func).collectres0: Array[String] = Array([partID:0, val: 3], [partID:0, val: 7], [partID:1, val: 1], [partID:1, val: 4], [partID:1, val: 5], [partID:1, val: 8], [partID:2, val: 2], [partID:2, val: 6], [partID:2, val: 9])注意:此時coalesce(3,true)之後分割槽情況改變,因為傳入了引數shuffle=true3.9 Action: collectAsMap 屬於PairRDDval rdd = sc.parallelize(List(("a", 1), ("b", 2)))# scala> rdd.collect collect返回的是陣列Arrayres0: Array[(String, Int)] = Array((a,1), (b,2))# scala> rdd.collectAsMap collectAsMap返回的是對映Mapres1: scala.collection.Map[String,Int] = Map(b -> 2, a -> 1)3.10 Action: countByKey 屬於PairRDD,計算key為“xx”出現的次數 val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))# scala> rdd1.count res2: Long = 5# scala> rdd1.countByKeyres3: scala.collection.Map[String,Long] = Map(a -> 1, b -> 2, c -> 2)注意:countByKey可以用來寫Wordcount,前提是(“xxx”,1)3.11 Action: countByValue 屬於RDD,計算每個元素出現的次數val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))scala> rdd1.countByValueres4: scala.collection.Map[(String, Int),Long] = Map((c,2) -> 1, (a,1) -> 1, (b,2) -> 2, (c,1) -> 1)注意:把rdd中的元組(“xxx”,n)當做value來count3.12 Transformation: filterByRange 屬於OrderedRDD 需要有k:v的rddval rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1),("b",6)))# scala> val rdd2 = rdd1.filterByRange("b","d")rdd2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[9] at filterByRange at <console>:23# scala> rdd2.collect res5: Array[(String, Int)] = Array((c,3), (d,4), (c,2), (b,6))注意:filterByRange實際上把key按順序排序,之後再根據給定的range篩選3.13 Transformation: flatMapValues 屬於PairRDDval rdd3 = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))# scala> val rdd4 = rdd3.flatMapValues(_.split(" "))rdd4: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[1] at flatMapValues at <console>:23# scala> rdd4.collectres0: Array[(String, String)] = Array((a,1), (a,2), (b,3), (b,4))注意:對Value先進行map後進行flat3.14 Transformation: foldByKey(zV)(func) 屬於PairRDDval rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)# scala> val rdd2 = rdd1.map(x => (x.length, x))rdd2: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[3] at map at <console>:23# scala> rdd2.collectres1: Array[(Int, String)] = Array((3,dog), (4,wolf), (3,cat), (4,bear))# scala> rdd2.foldByKey("")(_+_).collectres3: Array[(Int, String)] = Array((4,wolfbear), (3,dogcat))3.15 Action: foreach(func) 與map類似,但返回值為Unit(空), 屬於RDDval rdd = sc.parallelize(List(1,2,3,4,5,6,7))scala> rdd.map(x=>println(x))res4: org.apache.spark.rdd.RDD[Unit] = MapPartitionsRDD[6] at map at <console>:24scala> rdd.map(x=>println(x)).collectres5: Array[Unit] = Array((), (), (), (), (), (), ())scala> rdd.foreach(x=>println(x))注意: rdd.foreach(x=>println(x)) 返回值為空,所以沒有顯示rdd.foreach(x=>{ 寫入資料庫的操作函式,首先建立connection }) 此時,rdd中有多少個元素就會建立多少個jdbc連結,供不應求,耗費資源 解決辦法:foreachPartition 每個分割槽從連線池獲取一個連線,進行操作,節省資源消耗3.16 Action: foreachPartition 返回值為Unit(空) 屬於RDD非常適合用於對資料庫進行操作時
3.17 Transformation: keyBy(func) 屬於PairRDDval rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)# scala> val rdd2 = rdd1.keyBy(_.length)rdd2: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[10] at keyBy at <console>:23# scala> rdd2.collectres8: Array[(Int, String)] = Array((3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant))# scala> rdd1.map(x=>(x.length,x)).collectres10: Array[(Int, String)] = Array((3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant))# scala> val rdd3 = rdd1.keyBy(_(0))rdd3: org.apache.spark.rdd.RDD[(Char, String)] = MapPartitionsRDD[11] at keyBy at <console>:23# scala> rdd3.collectres9: Array[(Char, String)] = Array((d,dog), (s,salmon), (s,salmon), (r,rat), (e,elephant))# scala> rdd1.map(x=>(x(0),x)).collectres11: Array[(Char, String)] = Array((d,dog), (s,salmon), (s,salmon), (r,rat), (e,elephant))3.18 Transformation: keys 屬於PairRDD# scala> rdd2.keys.collectres14: Array[Int] = Array(3, 6, 6, 3, 8)# scala> rdd3.keys.collectres16: Array[Char] = Array(d, s, s, r, e)3.19 Transformation: values 屬於PairRDD# scala> rdd2.values.collectres15: Array[String] = Array(dog, salmon, salmon, rat, elephant)# scala> rdd3.values.collectres17: Array[String] = Array(dog, salmon, salmon, rat, elephant)3.20 其他運算元學習的網址:
3.spark高階運算元3.1 Transformation: mapPartitions(func) 對每個分割槽Partition進行操作
val rdd = sc.parallelize(List(1,2,3,4,5,6,7),2)# scala> val func1 = (iter:Iterator[Int])=>{iter.toList.map(x=>"value:"+x).toIterator}func1: Iterator[Int] => Iterator[String] = <function1># scala> rdd.mapPartitions(func1).collectres2: Array[String] = Array(value:1, value:2, value:3, value:4, value:5, value:6, value:7)3.2
# scala> val func = (index:Int,iter:Iterator[Int])=>{ | iter.toList.map(x=>"[part:"+ index+" value:"+x+"]").toIterator}func: (Int, Iterator[Int]) => Iterator[String] = <function2># scala> rdd.mapPartitionsWithIndex(func).collectres2: Array[String] = Array([part:0 value:1], [part:0 value:2], [part:0 value:3], [part:1 value:4], [part:1 value:5], [part:1 value:6], [part:1 value:7])3.3
3.4 Action: aggregate (zV)(func1,func2) 先區域性聚合,再整體聚合 |初始值 |各個分割槽內部應用的函式(區域性) |對各個分割槽的結果應用的函式(整體聚合)
.1)aggregate(0)(_+_,_+_) 先區域性相加,再整體相加 #scala> rdd.aggregate(0)(_+_,_+_) res0: Int = 28.2) aggregate(0)(math.max(_,_),_+_) 從各個分割槽中選出最大數,之後相加得結果# scala> rdd.mapPartitionsWithIndex(func).collectres1: Array[String] = Array(part:0 value:1, part:0 value:2, part:0 value:3, part:1 value:4, part:1 value:5, part:1 value:6, part:1 value:7) 3+7=10# scala> rdd.aggregate(0)(math.max(_,_),_+_) res4: Int = 10.3) aggregate(10)(math.max(_,_),_+_) # scala> rdd.aggregate(10)(math.max(_,_),_+_)res6: Int = 30# scala> rdd.aggregate(20)(math.max(_,_),_+_)res7: Int = 60# scala> rdd.aggregate(5)(math.max(_,_),_+_)res8: Int = 17# scala> rdd.aggregate(1)(math.max(_,_),_+_)res11: Int = 11# scala> rdd.aggregate(2)(math.max(_,_),_+_)res12: Int = 12注意:
.4)aggregate("")(_ + _, _ + _) aggregate("=")(_ + _, _ + _)val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)# scala> val func = (index:Int,iter:Iterator[String])=>{ | iter.toList.map(x=>"partId:"+index+" val:"+x).toIterator}func: (Int, Iterator[String]) => Iterator[String] = <function2># scala> rdd2.mapPartitionsWithIndex(func).collectres16: Array[String] = Array(partId:0 val:a, partId:0 val:b, partId:0 val:c, partId:1 val:d, partId:1 val:e, partId:1 val:f)# scala> rdd2.aggregate("")(_ + _, _ + _)res17: String = abcdef# scala> rdd2.aggregate("=")(_ + _, _ + _)res18: String = ==abc=def注意:結果之所以又能會不同,是因為不同分割槽的運算處理速度不同,有時可能是分割槽0較快,有時可能是分割槽1較快,所以位置會有不同。scala> rdd1.aggregate("")(_+_,_+_)res18: String = 456123scala> rdd1.aggregate("")(_+_,_+_)res19: String = 123456.5) aggregate("")((x,y)=>{math.max(x.length,y.length).toString},_+_)val rdd3 = sc.parallelize(List("12","23","345","4567"),2)# scala> rdd3.mapPartitionsWithIndex(func).collectres20: Array[String] = Array(partId:0 val:12, partId:0 val:23, partId:1 val:345, partId:1 val:4567)# scala> rdd3.aggregate("")((x,y)=>{math.max(x.length,y.length).toString},_+_)res21: String = 24# scala> rdd3.aggregate("")((x,y)=>{math.max(x.length,y.length).toString},_+_)res2: String = 42注意:rdd3.aggregate("")((x,y)=>{math.max(x.length,y.length).toString},_+_)part0: max("".length,"12".length).toString=>max(0,2).toString=>2.toString=>"2" max("2".length,"23".length).toString=>max(1,2).toString=>2.toString=>"2"part1: max("".length,"345".length).toString=>max(0,3).toString=>3.toString=>"3" max("3".length,"4567".length).toString=>max(1,4).toString=>4.toString=>"4"全域性: ""+"2"=>"2" "2"+"4"=>"24"或者: 每個分割槽並行操作,速度有快有慢,有可能part0速度快,則結果是“24” 有可能part1速度快,則結果是“42” ""+"4"=>"4" "4"+"2"=>"42".6) aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)val rdd5 = sc.parallelize(List("12","23","","345"),2)# scala> rdd5.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)res4: String = 11val rdd6 = sc.parallelize(List("12","23","345",""),2)# scala> rdd6.mapPartitionsWithIndex(func).collect res13: Array[String] = Array(partID:0 val:12, partID:0 val:23, partID:1 val:345, partID:1 val:)# scala> rdd6.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)res11: String = 10# scala> rdd6.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)res12: String = 01注意:part0: min("".length,"12".length).toString=>min(0,2).toString=>0.toString=>"0" min("0".length,"23".length).toString=>min(1,2).toString=>1.toString=>"1"part1: min("".length,"345".length).toString=>min(0,3).toString=>0.toString=>"0" min("0".length,"".length).toString=>min(1,0).toString=>0.toString=>"0"全域性: ""+"1"="1" "1"+"0"="10"或者 part1速度比part0快 ""+"0"="0" "0"+"1"="01"3.5 Transformation: aggregateByKey 屬於PairRDDval pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)# scala> def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = { | iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator | }func2: (index: Int, iter: Iterator[(String, Int)])Iterator[String]# scala> pairRDD.mapPartitionsWithIndex(func2).collectres15: Array[String] = Array([partID:0, val: (cat,2)], [partID:0, val: (cat,5)], [partID:0, val: (mouse,4)], [partID:1, val: (cat,12)], [partID:1, val: (dog,12)], [partID:1, val: (mouse,2)])
.1) aggregateByKey(0)(_+_,_+_) 相當於 reduceByKey(_+_)# scala> pairRDD.aggregateByKey(0)(_+_,_+_).collectres16: Array[(String, Int)] = Array((dog,12), (cat,19), (mouse,6))# scala> pairRDD.reduceByKey(_+_).collectres19: Array[(String, Int)] = Array((dog,12), (cat,19), (mouse,6))注意:part0: cat: (0+2)=>2 (2+5)=>7 mouse:(0+4)=>4part1: cat:(0+12)=>12mouse:(0+2)=>2dog:(0+12)=>12全域性: cat:(7+12)=>19mouse:(4+2)=>6dog:12.2)aggregateByKey(0)(math.max(_,_),_+_)scala> pairRDD.aggregateByKey(0)(math.max(_,_),_+_).collectres17: Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6))注意:part0: cat: max(0,2)=>2 max(2,5)=>5 mouse:max(0,4)=>4part1: cat:max(0,12)=>12mouse:max(0,2)=>2dog:max(0,12)=>12全域性: cat:(5+12)=>17mouse:(4+2)=>6dog:12.3)aggregateByKey("=")(_+_,_+_)val rdd = sc.parallelize(List(("a","A"),("b","B"),("a","A"),("a","A"),("b","B"),("c","C")),2)#scala> val func1 = (index:Int,iter:Iterator[(String,String)])=>{ | iter.toList.map(x=>"part:"+index+" value:"+x).iterator}func1: (Int, Iterator[(String, String)]) => Iterator[String] = <function2>#scala> rdd.mapPartitionsWithIndex(func1).collectres8: Array[String] = Array(part:0 value:(a,A), part:0 value:(b,B), part:0 value:(a,A), part:1 value:(a,A), part:1 value:(b,B), part:1 value:(c,C))# scala> rdd.aggregateByKey("=")(_+_,_+_).collectres22: Array[(String, String)] = Array((b,=B=B), (a,=AA=A), (c,=C))注意:part0: a:("="+"A")=>"=A" ("=A"+"A")=>"=AA" b:("="+"B")=>"=B"part1: a:("="+"A")=>"=A" b:("="+"B")=>"=B" c:("="+"C")=>"=C"全域性: a:("=AA"+"=A")=>"=AA=A" b:("=B"+"=B")=>"=B=B" c:"=C".4) aggregateByKey(100)(math.max(_, _), _ + _)# scala> pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collectres27: Array[(String, Int)] = Array((dog,100), (cat,200), (mouse,200))3.6 Transformation: combineByKey(func1,func2,func3) 較為底層的方法 屬於PairRDD,reduceByKey,aggregateByKey底層呼叫的都是它
|x=>x,是對每個分割槽的每個key的第一個value進行操作.1) combineByKey(x=>x,(m:Int,n:Int)=>m+n,(a:Int,b:Int)=>a+b)val rdd1 = sc.textFile("hdfs://mini1:9000/wc").flatMap(_.split(" ")).map((_,1))# scala> rdd1.combineByKey(x=>x,(m:Int,n:Int)=>m+n,(a:Int,b:Int)=>a+b).collectres0: Array[(String, Int)] = Array((love,3), (leave,6), (i,3), (me,3), (us,3), (you,3), (girl,3), (hello,6), (kitty,3), (wanna,3), (away,6), (my,3)) |x=>x+10,是對每個分割槽的每個key的第一個value進行+10操作.2) combineByKey(x=>x+10,(m:Int,n:Int)=>m+n,(a:Int,b:Int)=>a+b)val rdd1 = sc.textFile("hdfs://mini1:9000/wc").flatMap(_.split(" ")).map((_,1))scala> rdd1.combineByKey(x=>x+10,(m:Int,n:Int)=>m+n,(a:Int,b:Int)=>a+b).collect res2: Array[(String, Int)] = Array((love,33), (leave,36), (i,33), (me,33), (us,33), (you,33), (girl,33), (hello,36), (kitty,33), (wanna,33), (away,36), (my,33))注意:當/wc下有3個檔案時(有3個block塊(<128m), 不是有3個檔案就有3個block, ), 每個key計算出的value會多加3個10
.3)combineByKey(x=>List(x),(m:List[String],n:String)=>m:+n, (a:List[String],b:List[String])=>a++b) 把相同的key的value放到同一個集合中val rdd4 = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)val rdd5 = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)val rdd6 = rdd5.zip(rdd4)# scala> rdd6.collectres3: Array[(Int, String)] = Array((1,dog), (1,cat), (2,gnu), (2,salmon), (2,rabbit), (1,turkey), (2,wolf), (2,bear), (2,bee))
#scala> rdd6.combineByKey(x=>List(x),(m:List[String],n:String)=>m:+n, | (a:List[String],b:List[String])=>a++b).collectres4: Array[(Int, List[String])] = Array((1,List(dog, cat, turkey)), (2,List(gnu, salmon, rabbit, wolf, bear, bee)))注意:part0: 1:"dog"=>List("dog") List("dog"):+"cat"=>List("dog","cat") 2:"gnu"=>List("gnu")part1: 1:"turkey"=>List("turkey") 2:"salmon"=>List("salmon") List("salmon"):+"rabbit"=>List("salmon","rabbit")part2: 2:"wolf"=>List("wolf") List("wolf"):+"bear"=>List("wolf","bear") List("wolf","bear"):+"bee"=>List("wolf","bear","bee") 全域性: 1:List("dog","cat")++List("turkey")=>List("dog","cat","turkey") 2:List("gnu")++List("salmon","rabbit")=>List("gnu","salmon","rabbit") List("gnu","salmon","rabbit")++List("wolf","bear","bee")=> List("gnu","salmon","rabbit","wolf","bear","bee") 3.7 Transformation: repartition(n) 給rdd重新分割槽實際上,repartition(n)的實現呼叫了coalesce(n,true)
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)# scala> val func = (index: Int, iter: Iterator[(Int)]) => { | iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator | }func: (Int, Iterator[Int]) => Iterator[String] = <function2># scala> rdd1.mapPartitionsWithIndex(func).collectres0: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:0, val: 4], [partID:1, val: 5], [partID:1, val: 6], [partID:1, val: 7], [partID:1, val: 8], [partID:1, val: 9])# scala> val rdd2 = rdd1.repartition(3)rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[5] at repartition at <console>:23# scala> rdd2.partitions.lengthres5: Int = 3# scala> rdd2.mapPartitionsWithIndex(func).collectres3: Array[String] = Array([partID:0, val: 3], [partID:0, val: 7], [partID:1, val: 1], [partID:1, val: 4], [partID:1, val: 5], [partID:1, val: 8], [partID:2, val: 2], [partID:2, val: 6], [partID:2, val: 9])3.8 Transformation: coalesce(n,shuffle=false) 合併val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)# scala> val func = (index: Int, iter: Iterator[(Int)]) => { | iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator | }func: (Int, Iterator[Int]) => Iterator[String] = <function2># scala> rdd1.mapPartitionsWithIndex(func).collectres0: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:0, val: 4], [partID:1, val: 5], [partID:1, val: 6], [partID:1, val: 7], [partID:1, val: 8], [partID:1, val: 9]) # scala> val rdd3 = rdd1.coalesce(3)rdd3: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:23# scala> rdd3.partitions.lengthres1: Int = 2# scala> rdd3.mapPartitionsWithIndex(func).collectres1: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:0, val: 4], [partID:1, val: 5], [partID:1, val: 6], [partID:1, val: 7], [partID:1, val: 8], [partID:1, val: 9])注意:coalesce(3)之後分割槽的情況並沒有改變,因為預設方法中引數shuffle=false(把一個機器上的資料通過網路移動到另一個機器上的過程)coalesce(n)如果shuffle為false時,如果傳入的引數大於現有的分割槽數目,最終結果RDD的分割槽數不變,也就是說不經過shuffle,是無法將RDD的分割槽數變多的。
實際上,repartition(n)的實現呼叫了coalesce(n,true)
# scala> val rdd4 = rdd1.coalesce(3,true)rdd4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at coalesce at <console>:23# scala> rdd4.partitions.lengthres1: Int = 3# scala> rdd4.mapPartitionsWithIndex(func).collectres0: Array[String] = Array([partID:0, val: 3], [partID:0, val: 7], [partID:1, val: 1], [partID:1, val: 4], [partID:1, val: 5], [partID:1, val: 8], [partID:2, val: 2], [partID:2, val: 6], [partID:2, val: 9])注意:此時coalesce(3,true)之後分割槽情況改變,因為傳入了引數shuffle=true3.9 Action: collectAsMap 屬於PairRDDval rdd = sc.parallelize(List(("a", 1), ("b", 2)))# scala> rdd.collect collect返回的是陣列Arrayres0: Array[(String, Int)] = Array((a,1), (b,2))# scala> rdd.collectAsMap collectAsMap返回的是對映Mapres1: scala.collection.Map[String,Int] = Map(b -> 2, a -> 1)3.10 Action: countByKey 屬於PairRDD,計算key為“xx”出現的次數 val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))# scala> rdd1.count res2: Long = 5# scala> rdd1.countByKeyres3: scala.collection.Map[String,Long] = Map(a -> 1, b -> 2, c -> 2)注意:countByKey可以用來寫Wordcount,前提是(“xxx”,1)3.11 Action: countByValue 屬於RDD,計算每個元素出現的次數val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))scala> rdd1.countByValueres4: scala.collection.Map[(String, Int),Long] = Map((c,2) -> 1, (a,1) -> 1, (b,2) -> 2, (c,1) -> 1)注意:把rdd中的元組(“xxx”,n)當做value來count3.12 Transformation: filterByRange 屬於OrderedRDD 需要有k:v的rddval rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1),("b",6)))# scala> val rdd2 = rdd1.filterByRange("b","d")rdd2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[9] at filterByRange at <console>:23# scala> rdd2.collect res5: Array[(String, Int)] = Array((c,3), (d,4), (c,2), (b,6))注意:filterByRange實際上把key按順序排序,之後再根據給定的range篩選3.13 Transformation: flatMapValues 屬於PairRDDval rdd3 = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))# scala> val rdd4 = rdd3.flatMapValues(_.split(" "))rdd4: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[1] at flatMapValues at <console>:23# scala> rdd4.collectres0: Array[(String, String)] = Array((a,1), (a,2), (b,3), (b,4))注意:對Value先進行map後進行flat3.14 Transformation: foldByKey(zV)(func) 屬於PairRDDval rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)# scala> val rdd2 = rdd1.map(x => (x.length, x))rdd2: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[3] at map at <console>:23# scala> rdd2.collectres1: Array[(Int, String)] = Array((3,dog), (4,wolf), (3,cat), (4,bear))# scala> rdd2.foldByKey("")(_+_).collectres3: Array[(Int, String)] = Array((4,wolfbear), (3,dogcat))3.15 Action: foreach(func) 與map類似,但返回值為Unit(空), 屬於RDDval rdd = sc.parallelize(List(1,2,3,4,5,6,7))scala> rdd.map(x=>println(x))res4: org.apache.spark.rdd.RDD[Unit] = MapPartitionsRDD[6] at map at <console>:24scala> rdd.map(x=>println(x)).collectres5: Array[Unit] = Array((), (), (), (), (), (), ())scala> rdd.foreach(x=>println(x))注意: rdd.foreach(x=>println(x)) 返回值為空,所以沒有顯示rdd.foreach(x=>{ 寫入資料庫的操作函式,首先建立connection }) 此時,rdd中有多少個元素就會建立多少個jdbc連結,供不應求,耗費資源 解決辦法:foreachPartition 每個分割槽從連線池獲取一個連線,進行操作,節省資源消耗3.16 Action: foreachPartition 返回值為Unit(空) 屬於RDD非常適合用於對資料庫進行操作時
3.17 Transformation: keyBy(func) 屬於PairRDDval rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)# scala> val rdd2 = rdd1.keyBy(_.length)rdd2: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[10] at keyBy at <console>:23# scala> rdd2.collectres8: Array[(Int, String)] = Array((3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant))# scala> rdd1.map(x=>(x.length,x)).collectres10: Array[(Int, String)] = Array((3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant))# scala> val rdd3 = rdd1.keyBy(_(0))rdd3: org.apache.spark.rdd.RDD[(Char, String)] = MapPartitionsRDD[11] at keyBy at <console>:23# scala> rdd3.collectres9: Array[(Char, String)] = Array((d,dog), (s,salmon), (s,salmon), (r,rat), (e,elephant))# scala> rdd1.map(x=>(x(0),x)).collectres11: Array[(Char, String)] = Array((d,dog), (s,salmon), (s,salmon), (r,rat), (e,elephant))3.18 Transformation: keys 屬於PairRDD# scala> rdd2.keys.collectres14: Array[Int] = Array(3, 6, 6, 3, 8)# scala> rdd3.keys.collectres16: Array[Char] = Array(d, s, s, r, e)3.19 Transformation: values 屬於PairRDD# scala> rdd2.values.collectres15: Array[String] = Array(dog, salmon, salmon, rat, elephant)# scala> rdd3.values.collectres17: Array[String] = Array(dog, salmon, salmon, rat, elephant)3.20 其他運算元學習的網址: