
DataFrame與RDD的區別
阿新 • • 發佈:2019-01-30
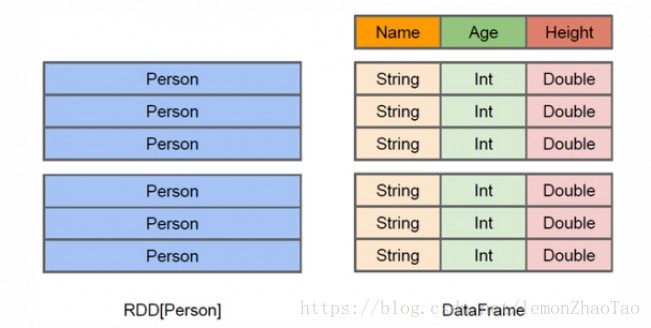
結合上圖進行理解:
- RDD與DataFrame都是分散式的 可以並行處理的 一個集合
- 但是DataFrame更像是一個二維表格,在這個二維表格裡面,我們是知道每一列的名稱
第一列是Name,它的型別是String
第二列是Age,它的型別是Int
第三列是Height,它的型別是Double
而對於DataFrame來說,它不僅可以知道里面的資料,而且它還可以知道里面的schema資訊
因此能做的優化肯定也是更多的,舉個例子:
因為每一列的資料型別是一樣的,因此可以採用更好的壓縮,這樣的話整個DF儲存所佔用的東西必然是比RDD要少很多的(這也是DF的優點)
想要優化的更好,所要暴露的資訊就需要更多,這樣系統才能更好大的進行優化
RDD的型別可以是Person,但是這個Person裡面,我們是不知道它的Name,Age,Height的,因此相比DF而言更難進行優化
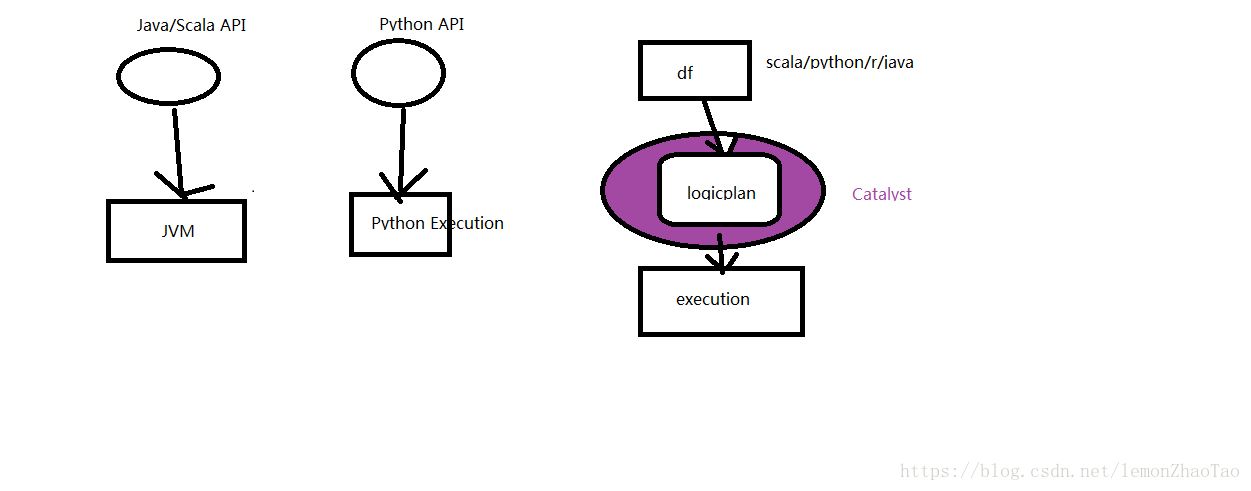
結合上圖進行理解:
- Java/Scala 操作RDD的底層是跑在JVM上的
Python 操作RDD的底層不跑在JVM上,它有Python Execution
因此使用RDD程式設計帶來一個很大的問題:
由於使用不同語言操作RDD,底層所執行的環境不同(使用Java/Scala 與 Python 所執行的效率完全是不一樣的,Python是會慢一些的) - 但是有了DataFrame是不一樣的
DF不是直接到執行環境的,中間還有一層是logicplan,統統先轉換成邏輯執行計劃之後,再去進行執行的;所以現在DF不管採用什麼語言,它的執行效率都是一樣的
從程式設計時,引入的依賴包角度進行理解:
我們會發現在工作中,只需要新增Spark SQL的依賴就可以了,不需要再特地新增Spark Core的依賴了
因為Spark SQL也需要依賴Spark Core,因此可以不新增Spark Core的依賴