opencv下LDA二分類
根據http://www.cnblogs.com/cfantaisie/archive/2011/03/25/1995849.html這是matlab版本下的LDA分類:
[model,k,ClassLabel]=LDATraining(traindata,trainlabel);
>> outputlabel=LDATesting(testdata,k,model,ClassLabel);
>> accurency=length(find(outputlabel==testlabel))/length(testlabel)這樣既可實現分類 得到測試樣本的準確率 很簡潔方便
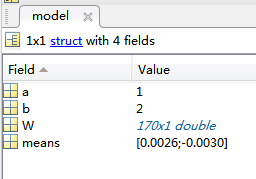
測試部分其實就是利用訓練得到的model 然後看了下這個model到底是什麼怎麼來的:
我的是二分類 對於二分類而言 這個model是這樣的:

在OpenCV裡有封裝好的LDA類:我知道opencv裡有結合好的LDA+Fisher人臉識別的FaceRecognizer這個類 那個比較好弄 但如果不是用LDA做人臉 而是分類普通資料就麻煩點了
根據http://blog.csdn.net/cjc211322/article/details/26590027?utm_source=tuicool&utm_medium=referral
http://www.tuicool.com/articles/BvuQFr http://www.cnblogs.com/freedomshe/archive/2012/04/24/sift_kmeans_lda_img_classification.html#L6
//LDA http://blog.csdn.net/zhazhiqiang/article/details/21189415 http://www.cnblogs.com/cfantaisie/archive/2011/03/25/1995849.html
#include<opencv2/highgui/highgui.hpp>
#include<opencv2/ml/ml.hpp>
#include <iostream>
#include"contrib.hpp"
using namespace cv;
using namespace std;
int main()
{
//sampledata
double sampledata[6][2] = { { 0, 1 }, { 0, 2 }, { 2, 4 }, { 8, 0 }, { 8, 2 }, { 9, 4 } };
Mat mat = Mat(6, 2, CV_64FC1, sampledata);
//labels
vector<int> labels;
for (int i = 0; i<mat.rows; i++)
{
if (i<mat.rows / 2)
{
labels.push_back(0);
}
else
{
labels.push_back(1);
}
}
//do LDA
LDA lda = LDA(mat, labels);
//get the eigenvector
Mat eivector = lda.eigenvectors().clone();
cout << "The eigenvector is:" << endl;
for (int i = 0; i<eivector.rows; i++)
{
for (int j = 0; j<eivector.cols; j++)
{
cout << eivector.ptr<double>(i)[j] << " ";
}
cout << endl;
}
//針對兩類分類問題,計算兩個資料集的中心
int classNum = 2;
vector<Mat> classmean(classNum);
vector<int> setNum(classNum);
for (int i = 0; i<classNum; i++)
{
classmean[i] = Mat::zeros(1, mat.cols, mat.type());
setNum[i] = 0;
}
Mat instance;
for (int i = 0; i<mat.rows; i++)
{
instance = mat.row(i);
if (labels[i] == 0)
{
add(classmean[0], instance, classmean[0]);
setNum[0]++;
}
else if (labels[i] == 1)
{
add(classmean[1], instance, classmean[1]);
setNum[1]++;
}
else
{
}
}
for (int i = 0; i<classNum; i++)
{
classmean[i].convertTo(classmean[i], CV_64FC1, 1.0 / static_cast<double>(setNum[i]));
}
vector<Mat> cluster(classNum);
for (int i = 0; i<classNum; i++)
{
cluster[i] = Mat::zeros(1, 1, mat.type());
multiply(eivector.t(), classmean[i], cluster[i]);
}
cout << "The project cluster center is:" << endl;
for (int i = 0; i<classNum; i++)
{
cout << cluster[i].at<double>(0) << endl;
}
system("pause");
return 0;
}

現在想用opencv的LDA來對自己的資料分類 根據http://blog.csdn.net/cjc211322/article/details/26590027?utm_source=tuicool&utm_medium=referral看到opencv的LDA類有建構函式、投影函式、計算特徵向量和特徵值的函式,可是沒有測試函式?然後應該可以根據matlab的自己寫測試部分:
#include<opencv2/highgui/highgui.hpp>
#include<opencv2/ml/ml.hpp>
#include <iostream>
#include"contrib.hpp"
using namespace cv;
using namespace std;
int main()
{
//read traindata trainlabel testdata testlabel and make them into Mat
CvMLData trainfeature, testfeature, trainlabelprimer, testlabelprimer;
trainfeature.read_csv("traindata.csv");
Mat traindata = Mat(trainfeature.get_values(), true);
testfeature.read_csv("testdata.csv");
Mat testdata = Mat(testfeature.get_values(), true);
trainlabelprimer.read_csv("trainlabel.csv");
Mat trainlabel = Mat(trainlabelprimer.get_values(), true);
testlabelprimer.read_csv("testlabel.csv");
Mat testlabel = Mat(testlabelprimer.get_values(), true);
int positivenum_train = 128, negativenum_train = 238;
//make trainlabel into vector<int>
vector<int> labelfortrain;
for (int i = 0; i < trainlabel.rows; ++i)
{
uchar* data = trainlabel.ptr<uchar>(i);
labelfortrain.push_back(data[0]);
}
//do LDA
//void LDA::compute(InputArrayOfArrays _src, InputArray _lbls) //第一個引數暫時只支援vector<Mat>,並且Mat必須是單通道的 //並且每個Mat的大小要相同,因為在實際操作中都是需要將Mat轉化為一個行向量 //compute函式的實現主要是根據第一個引數的型別呼叫LDA::lda來實現
//void LDA(const Mat& src, vector<int> labels) //這裡要求訓練樣本總數N要大於特徵的維數D
cout << "LDA training..." << endl;
LDA lda = LDA(traindata, labelfortrain);
cout << "LDA training done!" << endl;
//get the eigenvector //相當於matlab裡LDATraining所得model的W dimsX(num-1)
Mat eivector = lda.eigenvectors().clone();
//get the mean after projection //相當於matlab裡LDATraining所得model的means numX1
Mat projectionimg=lda.project(traindata);
Scalar mean,stddev;
meanStdDev(projectionimg, mean, stddev);
float getmean = mean[0];
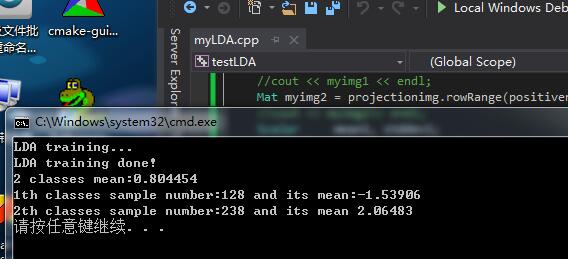
cout << "2 classes mean:" << getmean << endl;
////////////////////
Mat myimg1(positivenum_train, projectionimg.cols, projectionimg.type()), myimg2(negativenum_train, projectionimg.cols, projectionimg.type());
for (int i = 0; i < positivenum_train; i++)
{
uchar* myrow = myimg1.ptr<uchar>(i);
uchar* row = projectionimg.ptr<uchar>(i);
for (int j = 0; j <projectionimg.cols; j++)
myrow[j] = row[j];
}
Scalar means1, means2;
Scalar stddev1, stddev2;
meanStdDev(myimg1, means1, stddev1);
float getmean1 = means1[0];
cout << getmean1 << endl;
/*
for (int i =0; i < negativenum_train; ++i)
{
uchar* myrow = myimg2.ptr<uchar>(i);
int ii = i + positivenum_train ;
uchar* row =projectionimg.ptr<uchar>(ii);
for (int j = 0; j <projectionimg.cols; j++)
myrow[j] = row[j];
}
meanStdDev(myimg2, means2, stddev2);
float getmean2 = means2[0];
cout << getmean2<<endl;
*/
return 0;
} //可以看到投影矩陣有 兩個類投影后的平均值有 就差每一類投影后的平均值了

#include<opencv2/highgui/highgui.hpp>
#include<opencv2/ml/ml.hpp>
#include <iostream>
#include"contrib.hpp"
using namespace cv;
using namespace std;
int main()
{
//read traindata trainlabel testdata testlabel and make them into Mat
CvMLData trainfeature, testfeature, trainlabelprimer, testlabelprimer;
trainfeature.read_csv("traindata.csv");
Mat traindata = Mat(trainfeature.get_values(), true);
testfeature.read_csv("testdata.csv");
Mat testdata = Mat(testfeature.get_values(), true);
trainlabelprimer.read_csv("trainlabel.csv");
Mat trainlabel = Mat(trainlabelprimer.get_values(), true);
testlabelprimer.read_csv("testlabel.csv");
Mat testlabel = Mat(testlabelprimer.get_values(), true);
int positivenum_train = 128, negativenum_train = 238;
//make trainlabel into vector<int>
vector<int> labelfortrain;
for (int i = 0; i < trainlabel.rows; ++i)
{
uchar* data = trainlabel.ptr<uchar>(i);
labelfortrain.push_back(data[0]);
}
//do LDA
//這裡要求訓練樣本總數N要大於特徵的維數D
cout << "LDA training..." << endl;
LDA lda = LDA(traindata, labelfortrain);
cout << "LDA training done!" << endl;
//get the eigenvector //相當於matlab裡LDATraining所得model的W dimsX(num-1)
Mat eivector = lda.eigenvectors().clone();
//get the mean after projection //相當於matlab裡LDATraining所得model的means 1X2
Mat projectionimg=lda.project(traindata);
Scalar mean,stddev;
meanStdDev(projectionimg, mean, stddev);
float getmean = mean[0];
cout << "2 classes mean:" << getmean << endl;
//cout << projectionimg << endl;
Mat myimg1 = projectionimg.rowRange(0,positivenum_train).clone();
//cout << myimg1 << endl;
Mat myimg2 = projectionimg.rowRange(positivenum_train, projectionimg.rows).clone();
//cout << myimg2<< endl;
Scalar mean1, stddev1;
meanStdDev(myimg1, mean1, stddev1);
float getmean1 = mean1[0];
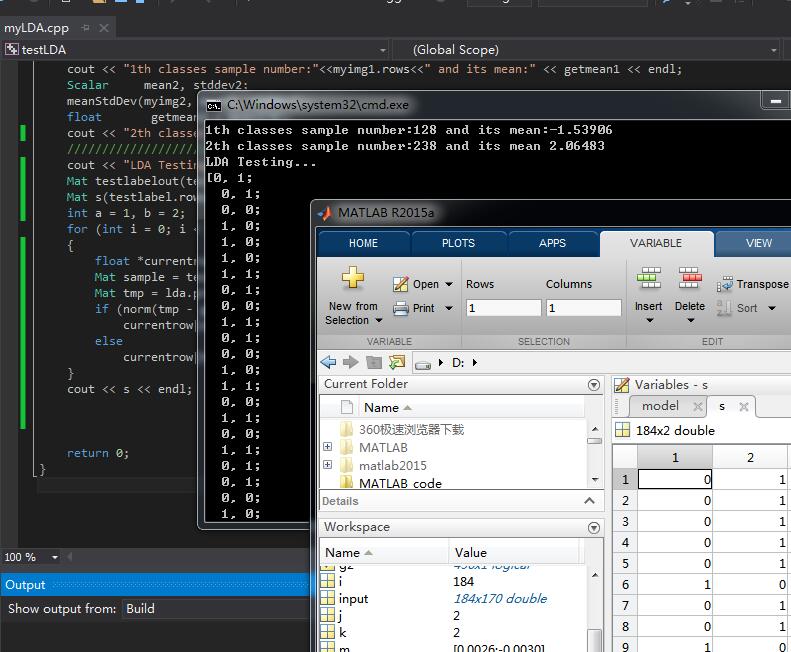
cout << "1th classes sample number:"<<myimg1.rows<<" and its mean:" << getmean1 << endl;
Scalar mean2, stddev2;
meanStdDev(myimg2, mean2, stddev2);
float getmean2 = mean2[0];
cout << "2th classes sample number:"<<myimg2.rows<<" and its mean " << getmean2 << endl;
return 0;
}
這樣matlab的model在opencv裡就有了 接下來就根據測試函式寫opencv的測試函數了
function target=LDATesting(input,k,model,ClassLabel)
% input: n*d matrix,representing samples
% target: n*1 matrix,class label
% model: struct type(see codes below)
% k: the total class number
% ClassLabel: the class name of each class
[n,~]=size(input);
s=zeros(n,k);
target=zeros(n,1);
for j=1:k*(k-1)/2
a=model(j).a;
b=model(j).b;
w=model(j).W;
m=model(j).means;
for i=1:n
sample=input(i,:);
tmp=sample*w;
if norm(tmp-m(1,:))<norm(tmp-m(2,:))
s(i,a)=s(i,a)+1;
else
s(i,b)=s(i,b)+1;
end
end
end
for i=1:n
pos=1;
maxV=0;
for j=1:k
if s(i,j)>maxV
maxV=s(i,j);
pos=j;
end
end
target(i)=ClassLabel(pos);
end
發現opencv裡的LDA真是矯情,首先要求特徵維數要小於樣本個數 而matlab裡的LDA就沒這個規定 還有要求樣本標籤不能像matlab裡一樣nX1的向量 如[11111122222]之類的 也不能是nX2的矩陣 如[0 1]代表第二類 [1 0]代表第一類 我試過這兩種標籤都報錯
#include<opencv2/highgui/highgui.hpp>
#include<opencv2/ml/ml.hpp>
#include <iostream>
#include"contrib.hpp"
using namespace cv;
using namespace std;
int main()
{
//read traindata trainlabel testdata testlabel and make them into Mat
CvMLData trainfeature, testfeature, trainlabelprimer, testlabelprimer;
trainfeature.read_csv("traindata.csv");
Mat traindata = Mat(trainfeature.get_values(), true);
testfeature.read_csv("testdata.csv");
Mat testdata = Mat(testfeature.get_values(), true);
trainlabelprimer.read_csv("trainlabel.csv"); //1th :[1 0] 2th:[0 1]
Mat trainlabel = Mat(trainlabelprimer.get_values(), true);
testlabelprimer.read_csv("testlabel.csv");
Mat testlabel = Mat(testlabelprimer.get_values(), true);
int positivenum_train = 128, negativenum_train = 238;
//make trainlabel into vector<int>
vector<int> labelfortrain;
for (int i = 0; i < trainlabel.rows; ++i)
{
uchar* data = trainlabel.ptr<uchar>(i);
labelfortrain.push_back(data[0]);
}
//do LDA
//這裡要求訓練樣本總數N要大於特徵的維數D
cout << "LDA training..." << endl;
LDA lda = LDA(traindata, labelfortrain);
cout << "LDA training done!" << endl;
//get the eigenvector //相當於matlab裡LDATraining所得model的W dimsX(num-1)
Mat eivector = lda.eigenvectors().clone();
//get the mean after projection //相當於matlab裡LDATraining所得model的means 1X2
Mat projectionimg=lda.project(traindata);
//Scalar mean,stddev;
//meanStdDev(projectionimg, mean, stddev);
//float getmean = mean[0];
//cout << "2 classes mean:" << getmean << endl;
//cout << projectionimg << endl;
Mat myimg1 = projectionimg.rowRange(0,positivenum_train).clone();
//cout << myimg1 << endl;
Mat myimg2 = projectionimg.rowRange(positivenum_train, projectionimg.rows).clone();
//cout << myimg2<< endl;
Scalar mean1, stddev1;
meanStdDev(myimg1, mean1, stddev1);
float getmean1 = mean1[0];
cout << "1th classes sample number:"<<myimg1.rows<<" and its mean:" << getmean1 << endl;
Scalar mean2, stddev2;
meanStdDev(myimg2, mean2, stddev2);
float getmean2 = mean2[0];
cout << "2th classes sample number:"<<myimg2.rows<<" and its mean " << getmean2 << endl;
//////////////////////////////////////test
cout << "LDA Testing..." << endl;
Mat testlabelout(testlabel.size(), testlabel.type()); //for LDA output label //matlab:target
Mat s(testlabel.rows, 2, CV_32F,cv::Scalar(0));
int a = 1, b = 2;
for (int i = 0; i < testdata.rows; i++)
{
float *currentrow = s.ptr<float>(i);
Mat sample = testdata.rowRange(i, i+1).clone();
Mat tmp = lda.project(sample);
if (norm(tmp - getmean1)<norm(tmp - getmean2))
currentrow[a] = currentrow[a] + 1;
else
currentrow[b] = currentrow[b] + 1;
}
//cout << s << endl;
cout << "LDA Test done!" << endl;
///////////////////////////accurency
int correct = 0;
float accurency;
for (int i = 0; i < s.rows; ++i)
{
float* p = s.ptr<float>(i);
float* being = testlabel.ptr<float>(i);
//if (p[0] > p[1])
//cout << 0.9 << " " << 0.1 << " " << being[0] << " " << being[1] << endl;
//else
//cout << 0.1 << " " << 0.9 << " " << being[0] << " " << being[1] << endl;
if (((p[0] > p[1]) && (being[0] > being[1])) || ((p[0] < p[1]) && (being[0] < being[1])))
++correct;
}
cout << endl;
accurency = (float)correct / testlabel.rows;
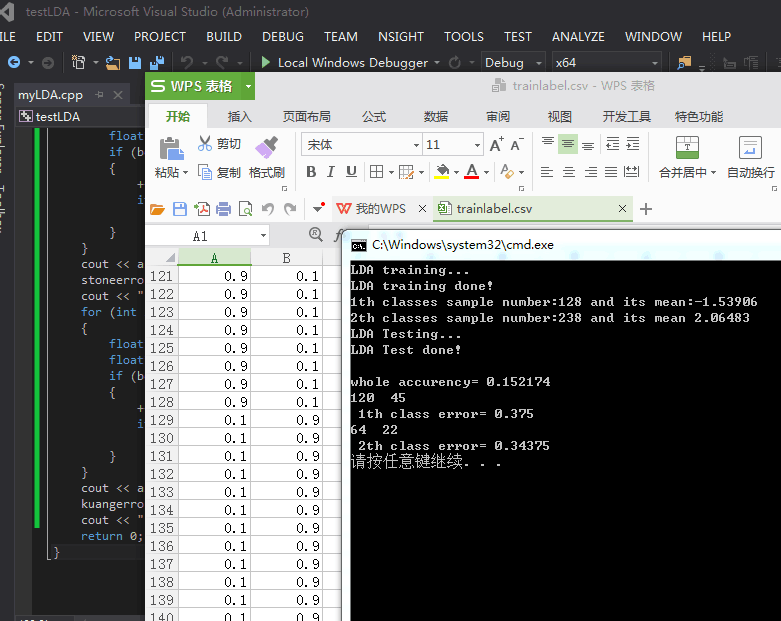
cout << "whole accurency= " << accurency << endl;
///////////////////////////////////////////////////////////////
int alluseless = 0, uselesserror = 0, alluseful = 0, usefulerror = 0;
float stoneerror = 0, kuangerror = 0;
for (int i = 0; i < s.rows; ++i)
{
float* p = s.ptr<float>(i);
float* being = testlabel.ptr<float>(i);
if (being[0] == (float)0.1)
{
++alluseless;
if (p[0] > p[1])
++uselesserror;
}
}
cout << alluseless << " " << uselesserror << endl;
stoneerror = (float)uselesserror / alluseless;
cout << " 1th class error= " << stoneerror << endl;
for (int i = 0; i < s.rows; ++i)
{
float* p = s.ptr<float>(i);
float* being = testlabel.ptr<float>(i);
if (being[0] == (float)0.9)
{
++alluseful;
if (p[0] < p[1])
++usefulerror;
}
}
cout << alluseful << " " << usefulerror << endl;
kuangerror = (float)usefulerror / alluseful;
cout << " 2th class error= " << kuangerror << endl;
return 0;
}
///////////////////////////accurency
Mat s2(testlabel.rows, 2, CV_32F, cv::Scalar(0));
int correct = 0;
float accurency;
for (int i = 0; i < s.rows; ++i)
{
float* p = s.ptr<float>(i);
float* being = testlabel.ptr<float>(i);
float* p2 = s2.ptr<float>(i);
if (p[0] > p[1])
{
//cout << 0.9 << " " << 0.1 << " " << being[0] << " " << being[1] << endl;
p2[0] = float(0.9);
p2[1] = float(0.1);
}
else
{
//cout << 0.1 << " " << 0.9 << " " << being[0] << " " << being[1] << endl;
p2[0] = float(0.1);
p2[1] = float(0.9);
}
}
for (int i = 0; i < s2.rows; ++i)
{
float* p2 = s2.ptr<float>(i);
float* being = testlabel.ptr<float>(i);
if (((p2[0] > p2[1]) && (being[0] > being[1])) || ((p2[0] < p2[1]) && (being[0] < being[1])))
++correct;
}
cout <<testlabel.rows<<" "<<correct<< endl;
accurency = (float)correct / testlabel.rows;
cout << "whole accurency= " << accurency << endl;
///////////////////////////////////////////////////////////////
int alluseless = 0, uselesserror = 0, alluseful = 0, usefulerror = 0;
float stoneerror = 0, kuangerror = 0;
for (int i = 0; i < s2.rows; ++i)
{
float* p = s2.ptr<float>(i);
float* being = testlabel.ptr<float>(i);
if (being[0] == (float)0.1)
{
++alluseless;
if (p[0] > p[1])
++uselesserror;
}
}
cout << alluseless << " " << uselesserror << endl;
stoneerror = (float)uselesserror / alluseless;
cout << " 1th class error= " << stoneerror << endl;
for (int i = 0; i < s2.rows; ++i)
{
float* p = s2.ptr<float>(i);
float* being = testlabel.ptr<float>(i);
if (being[0] == (float)0.9)
{
++alluseful;
if (p[0] < p[1])
++usefulerror;
}
}
cout << alluseful << " " << usefulerror << endl;
kuangerror = (float)usefulerror / alluseful;
cout << " 2th class error= " << kuangerror << endl;
return 0;

可是我用同樣的特徵矩陣 去matlab下的LDA