
類檔案結構(六)
6.1 無關性的基石
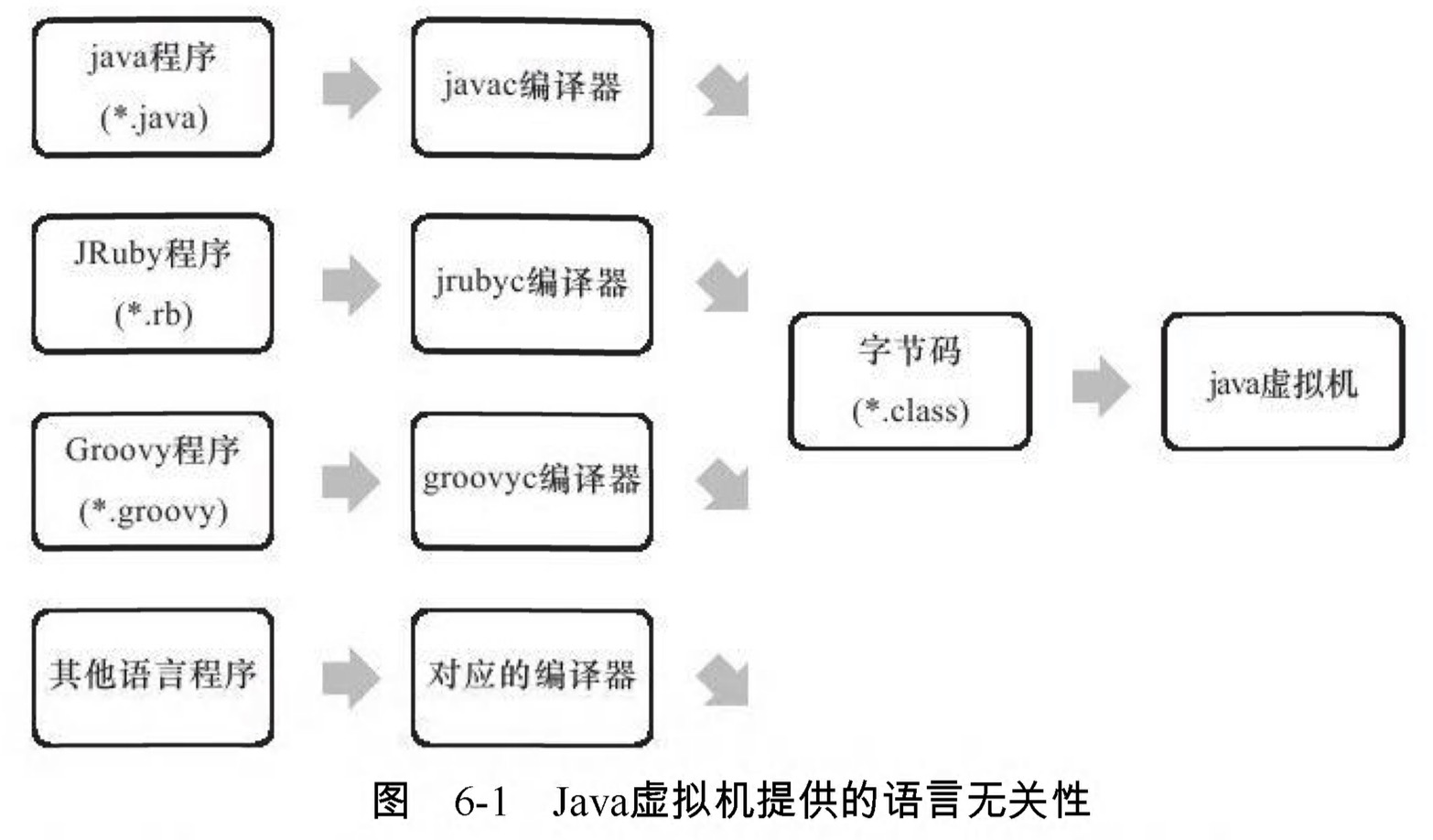
計算機只認識0和1,所以我們寫的程式需要被編譯器翻譯成由0和1構成的二級制格式才能被計算機執行。今天的計算機仍然只能識別0和1,但是由於近些年內虛擬機器及建立在虛擬機器之上的大量程式語言的出現,將我們編寫的程式編譯成二進位制本地機器碼(Native Code)已不再是唯一選擇,越來越多的程式語言選擇了與作業系統和機器指令集無關的、平臺中立的格式作為系統編譯後的儲存格式。
Sun公司及其他虛擬機器提供商釋出了許多可以執行在各種不同平臺上的虛擬機器,這些虛擬機器都可以載入和執行同一種平臺無關的位元組碼,從而實現程式的“一次編寫,到處執行”。
各種不同平臺的虛擬機器與所有平臺都統一使用的程式儲存格式–位元組碼(ByteCode)是構成平臺無關性的基石。
實現語言無關性的基礎仍然是虛擬機器和位元組碼儲存格式,使用Java編譯器可以把Java程式碼編譯為儲存位元組碼的Class檔案,使用JRuby等其他語言的編譯器一樣可以把程式程式碼編譯成Class檔案,虛擬機器不關心Class的來源是什麼語言,只要它符合Class檔案應有的結構就可以在Java虛擬機器中執行。
Java語言中的各種變數、關鍵字和運算子號的語義最終都是由多條位元組碼命令組合而成的,因此位元組碼命令所能提供的語義描述能力肯定會比Java語言本身更強大。因此,有一些Java語言本身無法有效支援的語言特性並不代表位元組碼本身無法有效支援,這也為其他語言實現一些有別於Java的語言特性提供了基礎。
6.2 Class 類檔案的結構
Class檔案是一組8位位元組為基礎單位的二進位制流,各個資料專案嚴格按照順序緊湊地排列在Class檔案之中,中間沒有新增任何分隔符,這使得整個Class檔案中儲存的內容幾乎全部都是程式執行的必要資料,沒有空隙存在。當遇到需要佔用8位位元組以上空間的資料項時,則會按照高位在前的方式分割成若干個8位位元組進行儲存。
根據Java虛擬機器規範的規定,Class檔案格式採用一種類似於C語言結構體的偽結構來儲存的,這種偽結構中只有兩種資料型別:無符號數和表。
有符號數就是用最高位表示符號(正或負),其餘位表示數值大小,無符號數則所有位都用於表示數的大小。
無符號數屬於基本的資料型別,以u1、u2、u4、u8來分別代表1個位元組、2個位元組、4個位元組和8個位元組的無符號數,無符號數可以用來描述數字、索引引用、數量值,或者按照UTF-8編碼構成字串值。
表是由多個無符號數或其他表作為資料項構成的複合資料型別,所有表都習慣性地以“_info”結尾。表用於描述有層次關係的複核結構的資料,整個Class檔案本質上就是一張表,它是由小標所示的資料項構成的:
| 型別 | 名稱 | 數量 |
|---|---|---|
| u4 | magic | 1 |
| u2 | minor_version | 1 |
| u2 | major_version | 1 |
| u2 | constant_pool_count | 1 |
| cp_info | constant_pool | constant_pool_count - 1 |
| u2 | access_flags | 1 |
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attribute_count | 1 |
| attribute_info | attributes | attributes_count |
無論是無符號數還是表,當需要描述同一型別但數量不定的多個數據時,經常會使用一個前置的容量計數器加若干個連續的資料項的形式,這時候稱這一系列連續的某一型別的資料為某一型別的集合。
6.2.1 魔數與Class檔案的版本
每個Class檔案的頭4個位元組稱為魔數(Magic Number),它的唯一作用是用於確定這個檔案是否為一個能被虛擬機器接受的Class檔案。很多檔案儲存標準中都是用魔數來進行身份識別,譬如圖片格式,如gif或jpeg等在檔案頭中都存有魔數。使用魔數而不是副檔名來進行識別主要是基於安全考慮,因為副檔名可以很隨意地被改動。檔案格式的制定者可以自由地選擇魔數值,只要這個魔數值還沒有被廣泛用過而且不會引起混淆即可。Class檔案的魔數的獲得很有“浪漫氣息”,值為:0xCAFEBABE。
緊接著魔數的4個位元組儲存的是Class檔案的版本號:第5和第6個位元組是次版本號(Minor Version),第7個和第8個位元組是主版本號(Major Version)。Java的版本號是從45開始的,JDK1.1之後的每個JDK大版本釋出主版本號向上加1(JDK1.0–1.1使用了45.0–45.3的版本號),高版本的JDK能向下相容以前版本的Class檔案,但不能執行以後版本的Class檔案,即時檔案格式並未發生變化。
public class TestClass{
private int m;
public int inc(){
return m+1;
}
}
使用十六進位制編輯器WinHex開啟這個Class檔案的結果,可以清楚看見開頭4個位元組的十六進位制表示的是0xCAFEBABE,代表次版本號的第5個和第6個位元組值為0x0000,而主版本號的值為0x0032,即十進位制的50,該版本號說明這個是可以被JDK1.6或以上版本的虛擬機器執行的Class檔案。

6.2.2 常量池
緊接著主次版本號之後的是常量池入口,常量池是Class檔案結構中與其他專案關聯最多的資料型別,也是佔用Class檔案空間最大的資料專案之一,同時它還是在Class檔案中第一個出現的表型別的資料專案。
由於常量池中常量數量不固定,所以在常量池的入口需要放置一項u2型別的資料,代表常量池容量計數值(constant_pool_count)。這個容量計數是從1而不是0開始的。常量池容量(偏移地址:0x00000008)為十六進位制數0x0016,即十進位制的22,這就代表常量池中有21項常量,索引值為1–21。制定Class檔案格式規範時,將第0項常量空出來是有特殊考慮的,這樣做是為了滿足後面某些指向常量池的索引值的資料在特定情況下需要表達“不引用任何一個常量池專案”的意思,這種情況就可以把索引值置為0來表示。Class檔案結構中只有常量池的容量計數是從1開始的,對於其他集合型別,包括介面索引集合、欄位表集合、方法表集合等的容量技術都與一般習慣相同,是從0開始的。

常量池中主要存放兩大類常量:字面量(Literal)和符號引用(Symbolic References)。字面量比較接近於Java語言層面的常量概念,如文字字串、被宣告為final的常量值等。而符號引用則屬於編譯原理方面的概念,包括下面三類常量:
- 類和介面的全限定名(Fully Qualified Name)
- 欄位的名稱和描述符(Descriptor)
- 方法的名稱和描述符
Java程式碼在進行Javac編譯的時候,並不像C和C++那樣有“連線”這一步驟,而是在虛擬機器載入Class檔案的時候進行動態連線。也就是說,在Class檔案中不會儲存各個方法和欄位的最終記憶體佈局資訊,因此這些欄位和方法的符號引用不經過轉換的話是無法直接被虛擬機器使用的。當虛擬機器執行時,需要從常量池獲得對應的符號引用,再在類建立時或執行時解析並翻譯到具體的記憶體地址中。
常量池中每一項常量都是一個表,共有11種結構各不相同的表結構資料,這11種表都有一個共同的特點,就是表開始的第一位是一個u1型別的標誌位(tag,取值為1至12,缺少標誌為2的資料型別),代表當前這個常量屬於哪種常量型別,11種常量型別所代表的具體含義如下表:
之所以說常量池是最繁瑣的資料,是因為這11種常量型別各自均有自己的結構。

由於Class檔案中方法、欄位等都需要引用CONSTANT_UTF8_info型常量來描述名稱,所以CONSTANT_UTF8_info型常量的最大長度也就是Java中方法和欄位名的最大長度。最大值length是65535,所以Java程式中如果定義了超過64KB英文字元的變數或方法名,將會無法編譯。
專門用於分析Class檔案位元組碼的工具:javap,可以輸出class檔案的位元組碼內容:
javap -verbose Test.class
編譯過後會有一些從來沒有在程式碼中出現過的常量,它們會被用來描述一些不方便使用“固定位元組”來表達的內容。譬如描述方法的返回值是什麼?有幾個引數?每個引數的型別是什麼?java無法通過簡單的無符號位元組來描述一個方法用到了什麼類,因此在描述方法的這些資訊時,需要引用常量表中的符號引用進行表達。

6.2.3 訪問標誌
在常量池結束後,緊接著的2個位元組代表訪問標誌(access_flags),這個標誌用於識別一些類或藉口層次的訪問資訊,包括:這個Class是類還是介面;是否定義為public型別;是否定義為abstract型別;如果是類的話,是否被宣告為final等;

access_flags中一共有32個標誌位可以使用,當前只定義了其中8個,沒有用到的標誌位要求一律為0.
6.2.4 類索引、父類索引與介面索引集合
類索引(this_class)和父類索引(super_class)都是一個u2型別的資料,而介面索引集合(interfaces)是一組u2型別的資料的集合,Class檔案由這三項資料來確定這個類的繼承關係。類索引用於確定這個類的全限定名,父類索引用於確定這個類的父類的全限定名。由於Java語言不允許多重繼承,所以父類索引只有一個,除了java.lang.Object之外,所有的Java類都有父類,因此除了java.lang.Object外,所有Java類的父類索引都不為0。介面索引集合就用來描述這個類實現了哪些介面,這些被實現的介面將按implements語句(如果這個類本身是一個介面,則應當是extends語句)後的介面順序從左到右排列在介面的索引集合中。
類索引、父類索引和介面索引集合都按順序排列在訪問標誌之後,類索引和父類索引用兩個u2型別的索引值表示,它們各自指向一個型別為CONSTANT_Class_info的類描述符常量,通過CONSTANT_Class_info型別的常量中的索引值可以找到定義在CONSTANT_Utf8_info型別的常量中的全限定名字串。
對於介面索引集合,入口的第一項—u2型別的資料為藉口計數器(interfaces_count),表示索引表的容量。如果該類沒有任何藉口,那麼該計數器值為0,後面的介面的索引表不再佔用任何位元組。
6.2.5 欄位表集合
欄位表(field_info)用於描述介面或類中宣告的變數。欄位(field)包括了類級變數或例項級變數,但不包括在方法內部宣告的變數。java中描述一個欄位可以包含的資訊:欄位的作用域(public、private、protected修飾符)、是類級變數還是例項級變數(static修飾符)、可變性(final)、併發可見性(volatile修飾符,是否強制從主記憶體讀寫)、可否序列化(transient修飾符)、欄位資料型別(基本型別、物件、陣列)、欄位名稱。這些資訊中,各個修飾符都是布林值,要麼有某個修飾符,要麼沒有,很適合使用標誌位來表示。而欄位叫什麼名字、欄位被定義為什麼資料型別,這些都是無法固定的,只能引用常量池中的常量來描述。
欄位修飾符放在access_flags專案中,它與類中的access_flags專案是非常類似的,都是一個u2的資料型別,其中可設定的標誌位和含義如下:


跟隨access_flags標誌的是兩個索引值:name_index和descriptor_index。它們都是對常量池的引用,分別代表著欄位的簡單名稱及欄位和方法的描述符。
全限定名:"org/fenixsoft/clazz/TestClass"是類的全限定名,僅僅是把類全名中的“.”替換成了“/”而已,為了使連續的多個許可權定名之間不產生混淆,在使用時最後一般會加入一個“;”號表示全限定名結束。
簡單名稱:指沒有型別和引數修飾的方法或欄位名稱,例如方法inc()和欄位m的簡單名稱分別是“inc”和“m”。
描述符:作用是用來描述欄位的資料型別、方法的引數列表(包括數量、型別以及順序)和返回值。根據描述符規則,基本資料型別(byte、char、double、float、int、long、short、boolean)及代表無返回值的void型別都用一個大寫字元來表示,而獨享型別則用字元L加物件的全限定名來表示:

對於陣列型別,每一維度將使用一個前置的“[”字元來描述,如一個定義為“java.lang.String[][]”型別的二維陣列,將被記錄為:“[[Ljava/lang/String;”,一個整型陣列“int[]”將被記錄為“[I”。
用描述符來描述方法時,按照先引數列表,後返回值的順序描述,引數列表按照引數的嚴格順序放在一組小括號“()”之內。如方法void inc()的描述符為“()V”,方法java.lang.String toString()的描述符為“()Ljava/lang/String;”,方法int indexOf(char[] source,int sourceOffset,int sourceCount,char[] targetOffset,int targetCount,int fromIndex)的描述符為“([CII[CIII)I”。
6.2.6 方法表集合
Class檔案儲存格式中對方法的描述與對欄位的描述幾乎用了完全一致的方法,方法表的結構如同欄位表一樣,依次包括了訪問標誌(access_flags)、名稱索引(name_index)、描述符索引(descriptor_index)、屬性表合集(attributes)。

因為volatile關鍵字和transient關鍵字不能修飾方法,所以方法表的訪問標誌中沒有了ACC_VOLATILE標誌和ACC_TRANSIENT標誌。相對的,synchronized、native、strictfp和abstract關鍵字可以修飾的方法,所以方法表的訪問標誌中增加了ACC_SYNCHRONIZED、ACC_NATIVE、ACC_STRICTFP和ACC_ABSTRACT標誌,對於方法表,所有標誌位及其取值:

方法的定義可以通過訪問標誌、名稱索引、描述符索引表達清楚,但方法裡面的程式碼在哪?方法裡的Java程式碼,經過編譯器編譯成位元組碼指令後,存放在方法屬性表集合中一個名為“Code”的屬性裡面,屬性表作為Class檔案格式中最具擴充套件性的一種資料專案。
6.2.7 屬性表集合
屬性表(attribute_info)在前面的講解之中已經出現過多次,在Class檔案、欄位表、方發表中都可以攜帶自己的屬性表集合,以用於描述某些場景專有的資訊。
與Class檔案中其他的資料專案要求嚴格的順序、長度和內容不同,屬性表集合的限制稍微寬鬆,不再要求各個屬性表具有嚴格的順序,並且只要不與已有的屬性名重複,任何人實現的編譯器都可以向屬性表中寫入自己定義的屬性資訊,Java虛擬機器執行時會忽略掉它不認識的屬性。
為了能正確地解析Class檔案,預定義了9項虛擬機器實現應當能識別的屬性:

對於每個屬性,它的名稱需要從常量池中引用一個CONSTANT_Utf8_info型別的常量來表示,而屬性值的結構則是完全自定義的,只需要說明屬性值所佔用的位數長度即可。

1.Code屬性
Java程式方法體裡面的程式碼經過Javac編譯器處理之後,最終變為位元組碼指令儲存在Code屬性內。Code屬性出現在方法表的屬性集合之中,但並非所有的方法表都必須存在這個屬性,譬如介面或抽象類中的方法就不存在Code屬性,如果方法表有Code屬性存在,那麼它的結構如下:

Code屬性是Class檔案中最重要的一個屬性,如果把一個Java程式中的資訊分為程式碼(Code,方法體裡面的Java程式碼)和元資料(Metadata,包括類、欄位、方法定義及其他資訊)兩部分,那麼在整個Class檔案裡,Code屬性用於描述程式碼,所有的其他資料專案就都用於描述元資料。