
[吳恩達機器學習筆記]11機器學習系統設計5資料量對機器學習的影響
阿新 • • 發佈:2019-01-30
11. 機器學習系統的設計
覺得有用的話,歡迎一起討論相互學習~Follow Me
參考資料 斯坦福大學 2014 機器學習教程中文筆記 by 黃海廣
11.5 資料量對機器學習的影響 Data For Machine Learning
問題引入
- 很多很多年前,我認識的兩位研究人員 Michele Banko 和 Eric Brill 進行了一項有趣的研究,他們嘗試通過機器學習演算法來區分常見的易混淆的單詞,他們嘗試了許多種不同的演算法,並發現資料量非常大時,這些不同型別的演算法效果都很好

- 比如,在這樣的句子中:早餐我吃了__個雞蛋 (to,two,too),在這個例子中,“早餐我吃了 2 個雞蛋”,這是一個易混淆的單詞的例子。於是他們把諸如這樣的機器學習問題,當做一類監督學習問題,並嘗試將其分類,什麼樣的詞,在一個英文句子特定的位置,才是合適的。他們用了幾種不同的學習演算法,這些演算法都是在他們 2001 年進行研究的時候,都已經被公認是比較領先的。他們所做的就是改變了訓練資料集的大小,並嘗試將這些學習演算法用於不同大小的訓練資料集中,下面就是他們得到的結果:
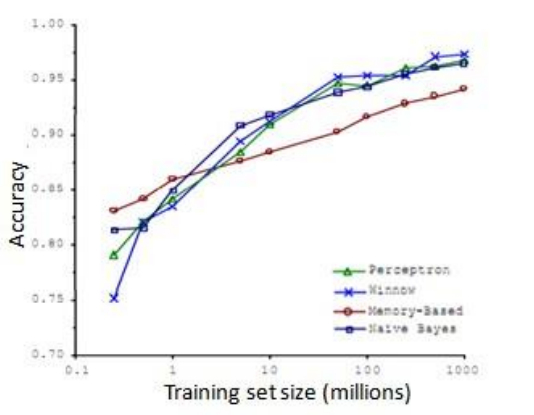
- 這些趨勢非常明顯首先大部分演算法,都具有相似的效能,其次,隨著訓練資料集的增大,在橫軸上代表以百萬為單位的訓練集大小,從 0.1 個百萬到 1000 百萬,也就是到了 10 億規模的訓練集的樣本,這些演算法的效能也都對應地增強了
- 事實上,如果你選擇任意一個演算法,可能是選擇了一個”劣等的”演算法,如果你給這個劣等演算法更多的資料,那麼從這些例子中看起來的話,它看上去很有可能會其他演算法更好,甚至會比”優等演算法”更好。
具有大量引數的模型在大量資料中有更大的提升空間
- 假設特徵值有足夠的資訊來預測y值,假設我們使用一種需要大量引數的學習演算法,這些引數可以擬合非常複雜的函式,如果使用大量資料對其進行訓練,這種演算法能很好地擬合訓練集,因此,訓練誤差就會很低了。
- 現在假設我們使用了非常非常大的訓練集,在這種情況下,儘管我們希望有很多引數,但是如果訓練集比引數的數量還大,甚至是更多,那麼這些演算法就不太可能會過度擬合,其還有很大的上升空間。
總結
- 如果你有大量的資料,而且你訓練了一種帶有很多引數的學習演算法,那麼這將會是一個很好的方式,來提供一個高效能的學習演算法。