
計算機底層知識拾遺(一)理解虛擬記憶體機制
這個系列會總結計算機,網路相關的一些重要的底層原理。很多底層原理大家上學的時候都學過,但是在學校的時候大部分的同學都是為了應付考試而學習,過幾天全忘了。隨著工作的時間越久,越體會到這些基礎知識的重要性。做技術和練武功一樣,當你到了一定的階段,也會遇到一個瓶頸,突破了你的眼界就會大不同,突破不了,只能困在原地無法成長。我自己深有體會,這些基礎知識,底層原理是助你打破瓶頸的靈丹妙藥。當理解了一些底層原理之後,會發現現在很多熱門技術,原理,常見的設計都是在底層基礎上發展而來的。
這篇總結一下單機系統的虛擬記憶體原理。在聊聊高併發(三十四)Java記憶體模型那些事(二)理解CPU快取記憶體的工作原理
虛擬記憶體是單機系統最重要的幾個底層原理之一,它由底層硬體和作業系統兩者軟硬體結合來實現,是硬體異常,硬體地址翻譯,主存,磁碟檔案和核心的完美互動。它主要提供了3個能力:
1. 給所有程序提供一致的地址空間,每個程序都認為自己是在獨佔使用單機系統的儲存資源
2. 保護每個程序的地址空間不被其他程序破壞,隔離了程序的地址訪問
3. 根據快取原理,上層儲存是下層儲存的快取,虛擬記憶體把主存作為磁碟的快取記憶體,在主存和磁碟之間根據需要來回傳送資料,高效地使用了主存
包括幾塊內容
1. 虛擬地址和實體地址
2. 頁表
3. 地址翻譯
4. 虛擬記憶體相關的資料結構
5. 記憶體對映
虛擬地址和實體地址
對於每個程序來說,它使用到的都是虛擬地址,每個程序都看到一樣的虛擬地址空間,對於32位計算機系統來說,它的虛擬地址空間是 0 - 2^32,也就是0 - 4G。對於64位的計算機系統來說,理論的虛擬地址空間是 0 - 2^64,遠高於目前常見的實體記憶體空間。虛擬地址空間不需要和實體地址空間一樣大小。
Linux核心把虛擬地址空間分為兩部分: 使用者程序空間和核心程序空間,兩者的比例一般是3:1,比如4G的虛擬地址空間,3G使用者使用者程序,1G用於核心程序。
下圖是一個典型的Linux程序的虛擬地址空間分佈
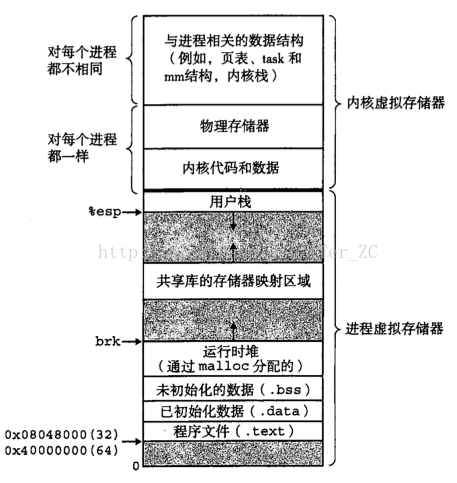
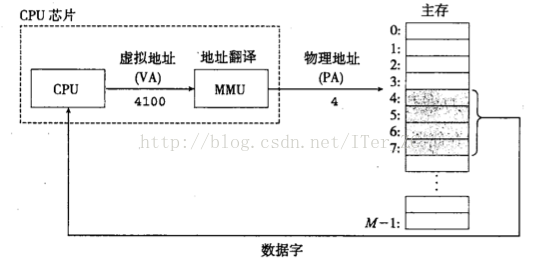
在說CPU快取記憶體的時候說過CPU只直接和暫存器和快取記憶體打交道,CPU在執行程序的指令時要取一個實際的實體地址的值的時候主要有幾步:
1. 把程序指令使用的虛擬地址通過MMU轉換成實體地址
2. 把實體地址對映到快取記憶體的快取行
3. 如果快取記憶體命中就返回
4. 如果不命中,就產生一個快取缺失中斷,從主存相應的實體地址取值,並載入到快取記憶體中。CPU從中斷中恢復,繼續執行中斷前的指令
所以快取記憶體是和實體地址相對映的,程序指令中使用到的是虛擬地址。
作業系統記憶體管理
在快取原理中,資料都是按塊來進行邏輯劃分的,一次換入/換出的資料都是以塊為最小單位,這樣提高了資料處理的效能。同樣的原理應用到具體的記憶體管理時,使用了頁(page)來表示塊,虛擬地址空間劃分為多個固定大小的虛擬頁(Virtual Page, VP),實體地址空間劃分為多個固定大小的物理頁(Physical Page, PP), 通常虛擬頁大小等於物理頁大小,這樣簡化了虛擬頁和物理頁的對映。虛擬頁的大小通常在4KB - 2MB之間。在JVM調優的時候有時候會使用2MB的大記憶體頁來提高GC的效能。
要明白一個重要的概念:
1. 對於CPU來說,它的目標儲存器是實體記憶體,使用快取記憶體做實體記憶體的快取
2. 同樣,對於虛擬記憶體來說,它的目標儲存器是磁碟空間,使用實體記憶體做磁碟的快取
所以,從快取原理的角度來理解,在任何時刻,虛擬頁的集合都分為3個不相交的子集:
1. 未分配的頁,即沒有任何資料和這些虛擬頁關聯,不佔用任何磁碟空間
2. 快取的頁,即已經分配了的虛擬頁,並且已經快取在具體的物理頁中
3. 未快取的頁,即已經為磁碟檔案分配了虛擬頁,但是還沒有快取到具體的物理頁中
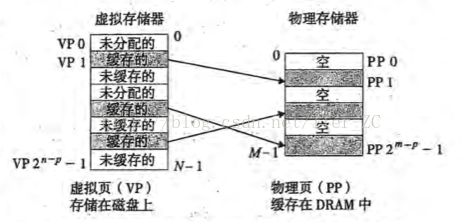
虛擬記憶體系統和快取記憶體系統一樣,需要判斷一個虛擬頁面是否快取在DRAM(主存)中,如果命中,就直接找到對應的物理頁。如果不命中,作業系統需要知道這個虛擬頁對應磁碟的哪個位置,然後根據相應的替換策略從DRAM中選擇一個犧牲的物理頁,把虛擬頁從磁碟中載入到DRAM物理主存中
虛擬記憶體的這種快取管理機制是通過作業系統核心,MMU(記憶體管理單元)中的地址翻譯硬體和每個程序存放在主存中的頁表(page table)資料結構來實現的。
頁表
頁表(page table)是存放在主存中的,每個程序維護一個單獨的頁表。它是一種管理虛擬記憶體頁和實體記憶體頁對映和快取狀態的資料結構。它邏輯上是由頁表條目(Page Table Entry, PTE)為基本元素構成的陣列。
1. 陣列的索引號對應著虛擬頁號
2. 陣列的值對應著物理頁號
3. 陣列的值可以留出幾位來表示有效位,許可權控制位。有效位為1的時候表示虛擬頁已經快取。有效位為0,陣列值為null時,表示未分配。有效位為0,陣列值不為null,表示已經分配了虛擬頁,但是還未快取到具體的物理頁中。許可權控制位有可讀,可寫,是否需要root許可權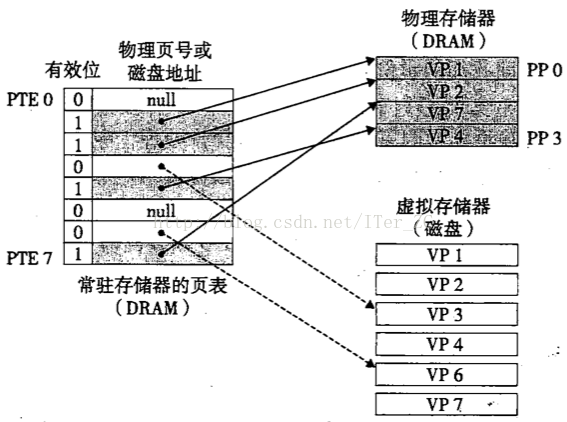
聊聊高併發(三十四)Java記憶體模型那些事(二)理解CPU快取記憶體的工作原理 這篇中解釋了快取相聯度的概念,DRAM快取是全相聯的,即只有一組,任意的快取行可以快取任意的內容,有一個比較判斷的過程,即任意的虛擬頁可以對應任意的物理頁。
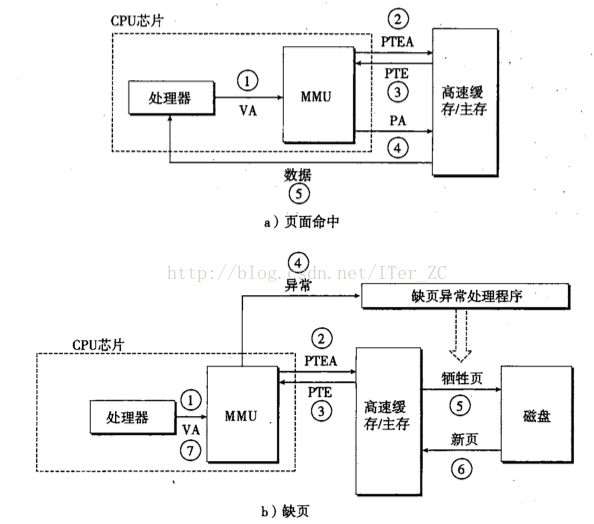
DARM快取的命中稱為頁命中,不命中稱為缺頁。舉個例子來說,
1. CPU要訪問的一個虛擬地址在虛擬頁3上(VP3),通過地址翻譯硬體從頁表的3號頁表條目中取出內容,發現有效位0,即沒有快取,就產生一個缺頁異常
2. 缺頁異常呼叫核心的缺頁異常處理程式,它會根據替換演算法選擇一個DRAM中的犧牲頁,比如PP3。PP3中已經快取了VP4對應的磁碟檔案的內容,如果VP4的內容有改動,就重新整理到磁碟中去。然後把VP3對應的磁碟檔案內容載入到PP3中。然後更新頁表條目,把PTE3指向PP3,並修改PTE4,不再指向PP3.
3. 缺頁異常處理程式返回後重新啟動缺頁異常前的指令,這時候虛擬地址對應的內容已經快取在主存中了,頁命中也可以讓地址翻譯硬體正常處理了
磁碟和主存之間傳送頁的活動叫做交換(swapping)或者頁面排程(頁面調入,頁面調出)。現代作業系統都採用按需排程的策略,即不命中發生時才調入頁面。作業系統都會在主存中分配一塊交換區(swap)來作緩衝區,加速頁面排程。
由於頁的交換會引起磁碟流量,所以具有好的區域性性的程式可以大大減少磁碟流量,提高效能。而如果區域性性不好產生大量缺頁,從而導致不斷地在磁碟和主存交換頁,這種現象叫快取顛簸。可以用Unix的函式getrusage來統計缺頁的次數
現代作業系統都採用多級頁表的方式來壓縮頁表的大小。舉個例子,
1. 對於32位的機器來說,支援4G的虛擬記憶體大小,如果每個頁是4KB大小,那麼採用一級頁表的話,需要10^6個頁表條目PTE。32位機器的頁表條目是4個位元組,那麼頁表需要4MB大小的空間。
2. 假設使用4MB大小的頁,那麼只需要10^3個頁表項。假設每個4MB大小的頁又分為4KB大小的子頁,那麼每個4MB大小的頁需要10^3個的頁表項來指向子頁。也就是說可以分為兩級頁表,第一級頁表項只需要4KB大小的頁表項,每個一級頁表項又指向一個4KB大小的二級頁表,二級頁表項則指向實際的物理頁。
頁表項載入是按需載入的,沒有分配的虛擬頁不需要建立頁表項, 所以可以一開始只建立一級頁表項,而二級頁表項按需建立,這樣大大壓縮了頁表的空間。
使用k級頁表項的地址翻譯如下:
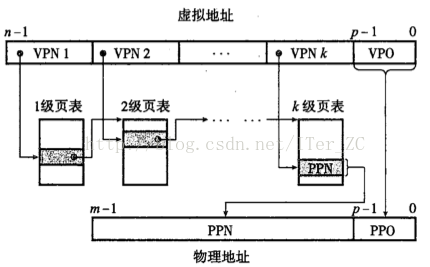
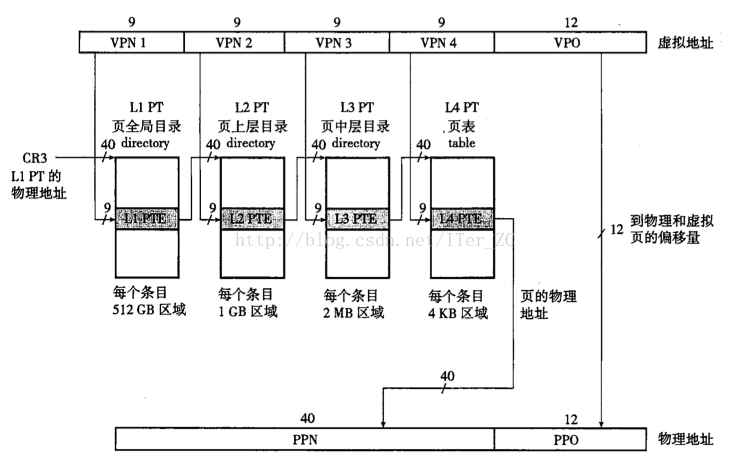
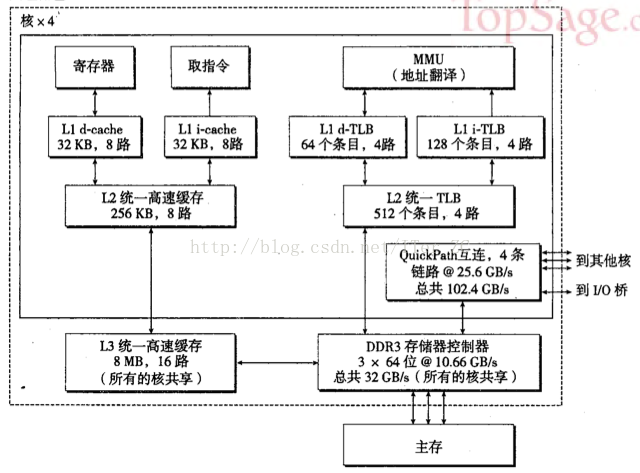
Core i7採用4級頁表的結構
地址翻譯
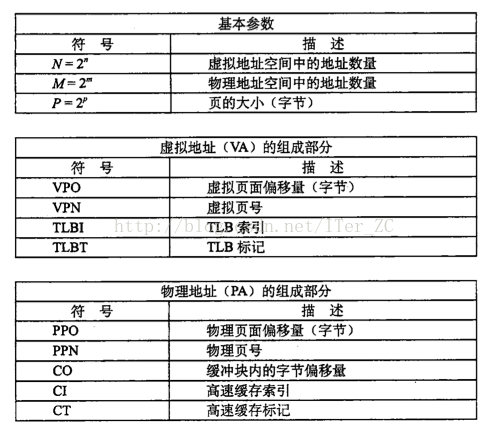
地址翻譯就是把N個元素的虛擬地址空間(VAS)對映到M個元素的實體地址空間(PAS)的過程。下表是地址翻譯時用到的符號
下面看一下CPU如何把一個虛擬地址翻譯到對應的實體地址。
1. CPU有一個專門的頁表基地址暫存器(page table base register, PTBR)指向當前頁表的基地址,從而可以快速定位到該程序的頁表
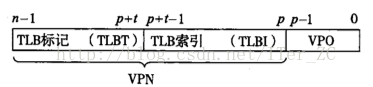
2. n位的虛擬地址劃分為p位的虛擬地址偏移量VPO和(n - p)位的虛擬頁號VPN
3. 實體地址同樣劃分為p位的實體地址偏移量PPO和(m - p)位的物理頁號PPN
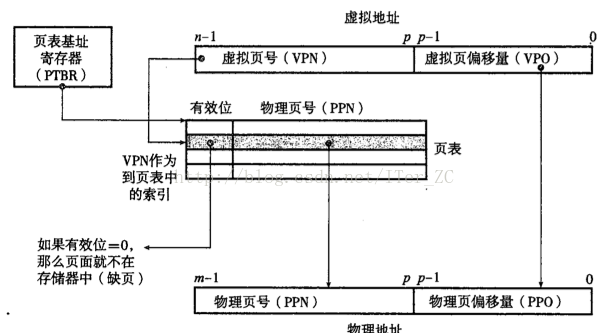
頁面的命中完全由硬體完成,缺頁則由硬體和核心共同完成,已經在上面舉例說明了。
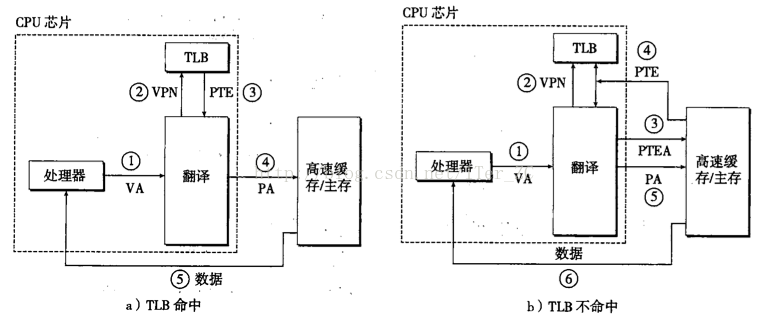
為了提高地址翻譯的效率,地址翻譯硬體還引入了一個硬體裝置來快取頁表條目PTE,叫做翻譯後備緩衝區TLB(translation lookaside buffer)。它是一個小的,虛擬定址的快取,每一行都儲存一個由單個PTE組成的塊。TLB也遵循快取的設計原理,分為組,行,塊的結構。一個虛擬地址對映到TLB的快取結構如下:
而TLB的命中和不命中的流程如下:
Core i7處理器的地址翻譯硬體結構如下
總結一下地址翻譯的過程:
1. CPU拿到一個虛擬地址,分為兩步,先通過頁表機制確定該地址所在虛擬頁的內容是否從磁碟載入到實體記憶體頁中,然後通過快取記憶體機制從該實體地址中取到資料
2. 地址翻譯硬體要把這個虛擬地址翻譯成一個實體地址,從而可以再根據快取記憶體的對映關係,把這個實體地址對應的值找到
3. 地址翻譯硬體利用頁表資料結構,TLB硬體快取等技術,目的只是把一個虛擬地址對映到一個實體地址。要記住DRAM快取是全相聯的,所以一個虛擬地址和一個實體地址是動態關聯的,不能直接根據虛擬地址推匯出實體地址,必須根據DRAM從磁碟把資料快取到DRAM時存到頁表時存的實際物理頁才能得到實際的實體地址,用物理頁PPN + VPO就能算出實際的實體地址 (VPO = PPO,所以直接用VPO即可)。 PPN的值是存在頁表條目PTE中的。地址翻譯做了一堆工作,就是為了找到物理頁PPN,然後根據VPO頁面偏移量,就能定位到實際的實體地址。
4. 得到實際實體地址後,根據快取記憶體的原理,把一個實體地址對映到快取記憶體具體的組,行,塊中,找到實際儲存的資料。
Linux虛擬記憶體機制
Linux把虛擬記憶體劃分成區域area的集合,每個存在的虛擬頁面都屬於一個area。一個area包含了連續的多個頁。Linux通過area相關的資料結構來靈活地管理虛擬記憶體。
1. 核心為每個程序維護了一個單獨的任務結構 task_struct
2. task_struct的mm指標指向了mm_struct,該結構描述了虛擬記憶體的執行狀態
3. mm_struct的pgd指標指向該程序的一級頁表的基地址。mmap指標指向了vm_area_struct連結串列
4. vm_area_struct是描述area結構的一個連結串列,連結串列節點的幾個重要屬性如下:vm_start表示area的開始位置,vm_end表示area的結束位置,vm_prot描述了area內的頁的讀寫許可權,vm_flags描述該area內的頁面是與其他程序共享還是程序私有, vm_next指向下一個area節點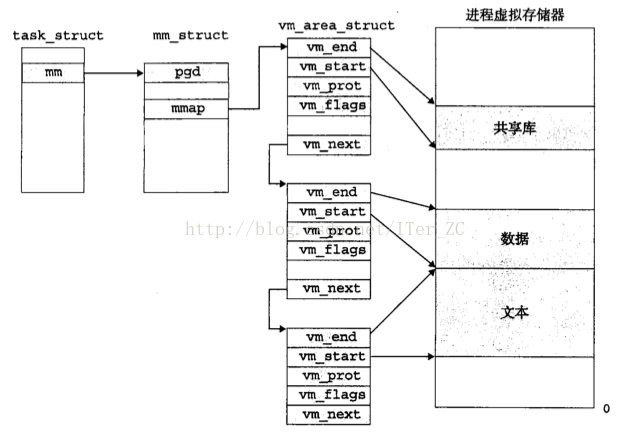
在Linux系統中,當MMU翻譯一個虛擬地址發生缺頁異常時,跳轉到核心的缺頁異常處理程式。
1. Linux的缺頁異常處理程式會先檢查一個虛擬地址是哪個area內的地址。只需要比較所有area結構的vm_start和vm_end就可以知道。area都是一個連續的塊。如果這個虛擬地址不屬於任何一個area,將發生一個段錯誤,終止程序
2. 要訪問的目標地址是否有相應的讀寫許可權,如果沒有,將觸發一個保護異常,終止程序
3. 選擇一個犧牲頁,如果犧牲頁被修改過,那麼把它交換出去。從磁碟載入虛擬頁內容到物理頁,更新頁表
記憶體對映機制
虛擬記憶體的目標儲存器是磁碟,所以虛擬記憶體區域是和磁碟中的檔案對應的。初始化虛擬記憶體區域的內容時,會把虛擬記憶體區域和一個磁碟檔案物件對應起來,這個過程叫記憶體對映(memory mapping)。虛擬記憶體可以對映的磁碟檔案物件包括兩種:
1. 一個普通的磁碟檔案,檔案中的內容被分成頁大小的塊。因為按需進行頁面排程,只有真正需要讀取這些虛擬頁時,才會交換到主存
2. 一個匿名檔案,匿名檔案是核心建立的,內容全是二進位制0,它相當於一個佔位符,不會產生實際的磁碟流量。對映到匿名檔案中的頁叫做請求二進位制零的頁(demand zero page)
一旦一個虛擬頁面被初始化了,它就在一個由核心維護的專門的交換區(swap area)之間換來換去。
由於記憶體對映機制,所以一個磁碟檔案物件可以被多個程序共享訪問,也可以被多個程序物件私有訪問。如果是共享訪問,那麼一個程序對這個物件的修改會顯示到其他程序。如果是私有訪問,核心會採用寫時拷貝copy on write的方式,如果一個程序要修改一個私有的寫時拷貝的物件,會產生一個保護故障,核心會拷貝這個私有物件,寫程序會在新的私有物件上修改,其他程序仍指向原來的私有物件。
理解了記憶體對映機制就可以理解幾個重要的函式:
1. fork函式會建立帶有獨立虛擬地址空間的新程序,核心會為新程序建立各種資料結構,分配一個唯一的PID,把當前程序的mm_struct, area結構和頁表都複製給新程序。兩個程序的共享同樣的區域,這些區域包括共享的記憶體對映和私有的記憶體對映。私有的記憶體對映區域都被標記為私有的寫時拷貝。如果新建的程序對這些虛擬頁做修改,那麼會觸發寫時拷貝,為新的程序維護私有的虛擬地址空間。
2. mmap函式可以建立新的虛擬記憶體area,並把磁碟物件對映到新建的area。
mmap可以用作高效的操作檔案的方式,直接把一個檔案對映到記憶體,通過修改記憶體就相當於修改了磁碟檔案,減少了普通檔案操作的一次拷貝操作。普通檔案操作時會先把檔案內容從磁碟複製到核心空間管理的一塊虛擬記憶體區域area,然後核心再把內容複製到使用者空間管理的虛擬記憶體area。 mmap相當於建立了一個核心空間和使用者空間共享的area,檔案的內容只需要在這個area對應的實體記憶體和磁碟檔案之間交換即可。
mmap也可以通過對映匿名檔案的方式來分配記憶體空間。比如malloc當要求分配的記憶體大小超過了MMAP_THRESHOLD(預設128kb)時,會使用mmap私有的,匿名檔案的方式來分配大塊的記憶體空間。
後面會詳細介紹mmap的機制
參考資料: