
【Lucene&&Solr】Lucene索引和搜尋流程
阿新 • • 發佈:2019-01-30
全文檢索:先建立索引,在對索引進行搜尋的過程
使用Lucene實現全文檢索,其流程包含兩個過程,索引建立過程和索引查詢過程
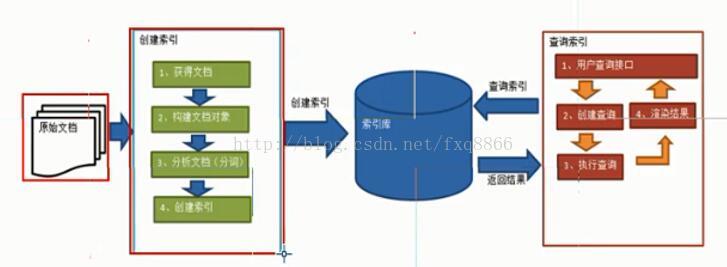
建立索引:
1.獲取文件
2.建立文件物件
3.分析文件
4.建立索引
把建立好的索引和原始文件放入到索引庫中。
查詢索引
1.使用者查詢介面
2.建立查詢
3.執行查詢,查詢索引庫
4.根據索引庫返回結果進行渲染
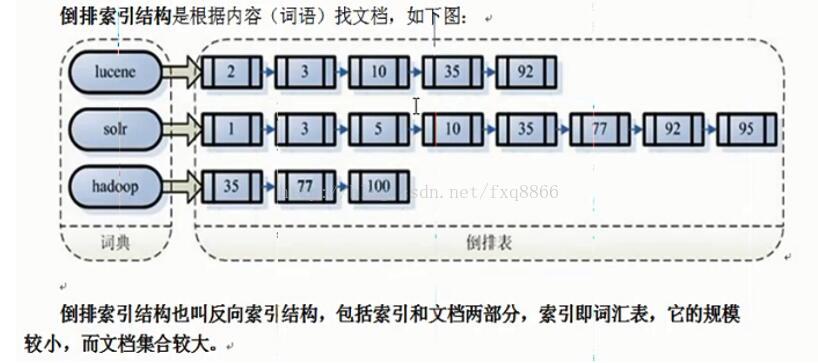
索引的目的是為了搜尋,建立索引是對語彙單元索引,通過詞語找文件,稱為倒排索引結構。
建立索引:
public IndexWriter getIndexWriter() throws Exception { //1.儲存到記憶體中 //Directory directory = new RAMDirectory(); //1.指定索引庫的存放位置Directory; Directory directory = FSDirectory.open(new File("E:\\tempLucencsolr\\index")); //2.指定一個分析器,對文件內容進行分析 Analyzer analyzer = new IKAnalyzer();//StandardAnalyzer();//官方推薦 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST,analyzer); return new IndexWriter(directory,config); } @Test public void createIndex() throws Exception { //建立一個indexWriter物件 IndexWriter indexWriter = getIndexWriter(); //建立filed物件,將filed新增到document物件中 File f = new File("E:\\tempLucencsolr\\searchSource"); File[] listFiles = f.listFiles(); for (File file:listFiles) { //建立document物件 Document document = new Document(); //檔名稱 String file_name = file.getName(); Field fileNameField = new TextField("fileName",file_name, Field.Store.YES); //檔案大小 Long file_size = FileUtils.sizeOf(file); Field fileSizeField = new LongField("fileSize",file_size, Field.Store.YES); //檔案路徑 String file_path = file.getPath(); Field filePathField = new StoredField("filePath",file_path); //檔案內容 String file_content = FileUtils.readFileToString(file); Field fileContentField = new TextField("fileContent",file_content, Field.Store.NO); document.add(fileNameField); document.add(fileSizeField); document.add(filePathField); document.add(fileContentField); //使用indexWriter物件將document物件寫入索引庫,此過程進行索引建立,並將 //索引和document物件寫入索引庫 indexWriter.addDocument(document); } System.out.println("lucene匯入索引建立成功"); //關係IndexWriter物件 indexWriter.close(); }
檢索索引:
@Test public void testSearcher() throws Exception { //第一步:建立一個Directory物件,索引庫存放的位置 Directory directory = FSDirectory.open(new File("E:\\tempLucencsolr\\index")); //第二步: 建立一個indexReader物件,需要指定Directory物件 IndexReader indexreader = DirectoryReader.open(directory); //流 //第三步:建立一個indexsearcher物件,需要指定IndexReader物件 IndexSearcher indexSearcher = new IndexSearcher(indexreader);//搜尋物件 //第四步:建立一個TermQuery物件,指定查詢的域和查詢的關鍵詞 Query query =new TermQuery(new Term("fileContent","jvm")); //第五步:執行查詢 TopDocs topDocs= indexSearcher.search(query,2); //第六步:返回查詢結果,遍歷查詢結果並輸出 ScoreDoc[] scoreDocs= topDocs.scoreDocs; //評分之後的文件。 for (ScoreDoc scoreDoc:scoreDocs) { int doc= scoreDoc.doc; System.out.println("文件編號:"+doc); Document document = indexSearcher.doc(doc); //根據文件編號查詢文件 //檔名稱 String fileName = document.get("fileName"); System.out.println(fileName); //檔案內容 String fileContent = document.get("fileContent"); System.out.println(fileContent); //檔案路徑 String filePath = document.get("filePath"); System.out.println(filePath); } System.out.println("搜尋執行結束"); //第七步:關閉IndexReader物件 indexreader.close(); }